 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot causal learning
Jan 28, 2023Predicting how different interventions will causally affect a specific individual is important in a variety of domains such as personalized medicine, public policy, and online marketing. However, most existing causal methods cannot generalize to predicting the effects of previously unseen interventions (e.g., a newly invented drug), because they require data for individuals who received the intervention. Here, we consider zero-shot causal learning: predicting the personalized effects of novel, previously unseen interventions. To tackle this problem, we propose CaML, a causal meta-learning framework which formulates the personalized prediction of each intervention's effect as a task. Rather than training a separate model for each intervention, CaML trains as a single meta-model across thousands of tasks, each constructed by sampling an intervention and individuals who either did or did not receive it. By leveraging both intervention information (e.g., a drug's attributes) and individual features (e.g., a patient's history), CaML is able to predict the personalized effects of unseen interventions. Experimental results on real world datasets in large-scale medical claims and cell-line perturbations demonstrate the effectiveness of our approach. Most strikingly, CaML zero-shot predictions outperform even strong baselines which have direct access to data of considered target interventions.
Causal Conceptions of Fairness and their Consequences
Jul 12, 2022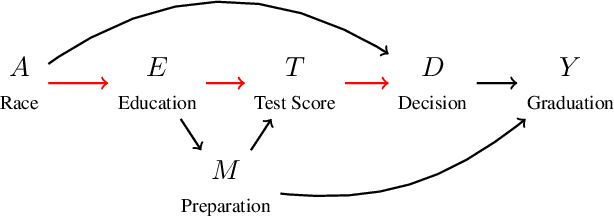
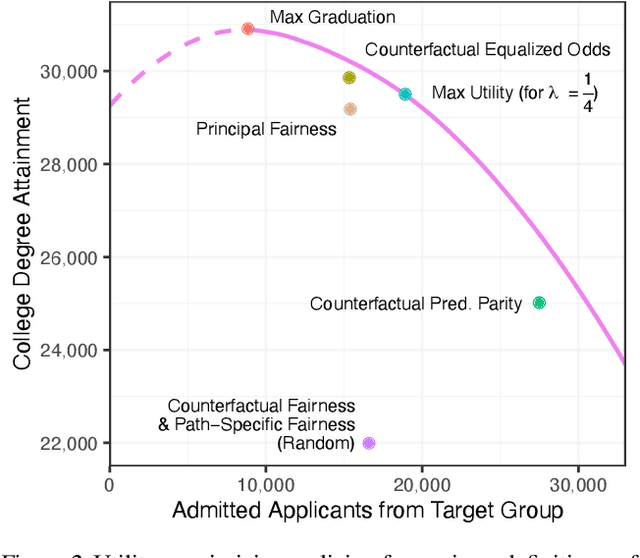
Recent work highlights the role of causality in designing equitable decision-making algorithms. It is not immediately clear, however, how existing causal conceptions of fairness relate to one another, or what the consequences are of using these definitions as design principles. Here, we first assemble and categorize popular causal definitions of algorithmic fairness into two broad families: (1) those that constrain the effects of decisions on counterfactual disparities; and (2) those that constrain the effects of legally protected characteristics, like race and gender, on decisions. We then show, analytically and empirically, that both families of definitions \emph{almost always} -- in a measure theoretic sense -- result in strongly Pareto dominated decision policies, meaning there is an alternative, unconstrained policy favored by every stakeholder with preferences drawn from a large, natural class. For example, in the case of college admissions decisions, policies constrained to satisfy causal fairness definitions would be disfavored by every stakeholder with neutral or positive preferences for both academic preparedness and diversity. Indeed, under a prominent definition of causal fairness, we prove the resulting policies require admitting all students with the same probability, regardless of academic qualifications or group membership. Our results highlight formal limitations and potential adverse consequences of common mathematical notions of causal fairness.
* ICML 2022
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
SliceNDice: Mining Suspicious Multi-attribute Entity Groups with Multi-view Graphs
Aug 21, 2019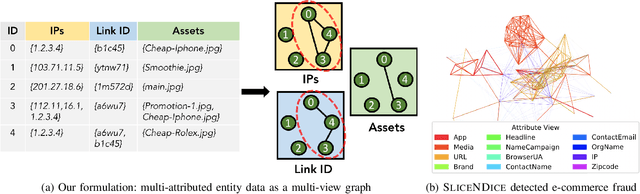
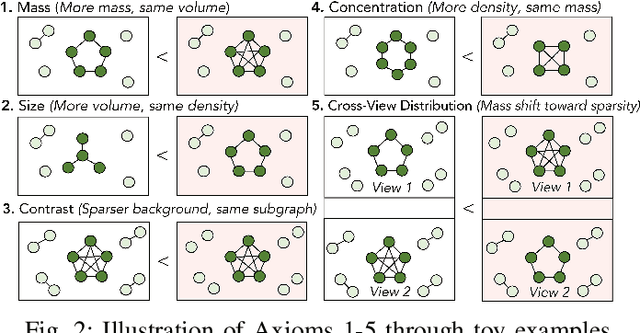
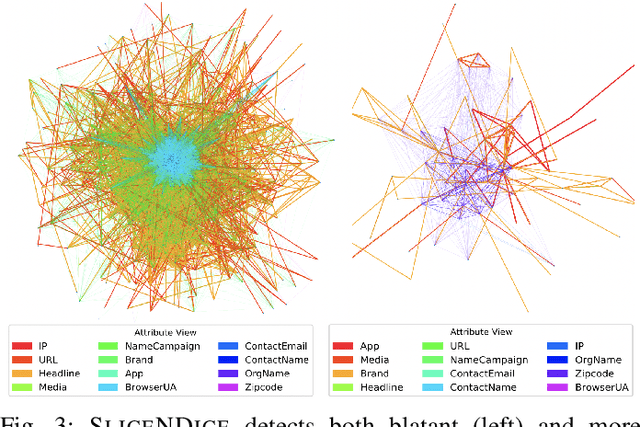

Given the reach of web platforms, bad actors have considerable incentives to manipulate and defraud users at the expense of platform integrity. This has spurred research in numerous suspicious behavior detection tasks, including detection of sybil accounts, false information, and payment scams/fraud. In this paper, we draw the insight that many such initiatives can be tackled in a common framework by posing a detection task which seeks to find groups of entities which share too many properties with one another across multiple attributes (sybil accounts created at the same time and location, propaganda spreaders broadcasting articles with the same rhetoric and with similar reshares, etc.) Our work makes four core contributions: Firstly, we posit a novel formulation of this task as a multi-view graph mining problem, in which distinct views reflect distinct attribute similarities across entities, and contextual similarity and attribute importance are respected. Secondly, we propose a novel suspiciousness metric for scoring entity groups given the abnormality of their synchronicity across multiple views, which obeys intuitive desiderata that existing metrics do not. Finally, we propose the SliceNDice algorithm which enables efficient extraction of highly suspicious entity groups, and demonstrate its practicality in production, in terms of strong detection performance and discoveries on Snapchat's large advertiser ecosystem (89% precision and numerous discoveries of real fraud rings), marked outperformance of baselines (over 97% precision/recall in simulated settings) and linear scalability.