 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Equitable Algorithms
Feb 17, 2023Predictive algorithms are now used to help distribute a large share of our society's resources and sanctions, such as healthcare, loans, criminal detentions, and tax audits. Under the right circumstances, these algorithms can improve the efficiency and equity of decision-making. At the same time, there is a danger that the algorithms themselves could entrench and exacerbate disparities, particularly along racial, ethnic, and gender lines. To help ensure their fairness, many researchers suggest that algorithms be subject to at least one of three constraints: (1) no use of legally protected features, such as race, ethnicity, and gender; (2) equal rates of "positive" decisions across groups; and (3) equal error rates across groups. Here we show that these constraints, while intuitively appealing, often worsen outcomes for individuals in marginalized groups, and can even leave all groups worse off. The inherent trade-off we identify between formal fairness constraints and welfare improvements -- particularly for the marginalized -- highlights the need for a more robust discussion on what it means for an algorithm to be "fair". We illustrate these ideas with examples from healthcare and the criminal-legal system, and make several proposals to help practitioners design more equitable algorithms.
Learning to be Fair: A Consequentialist Approach to Equitable Decision-Making
Sep 18, 2021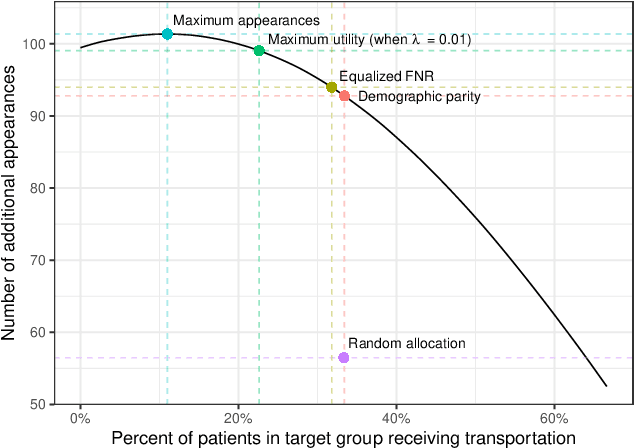
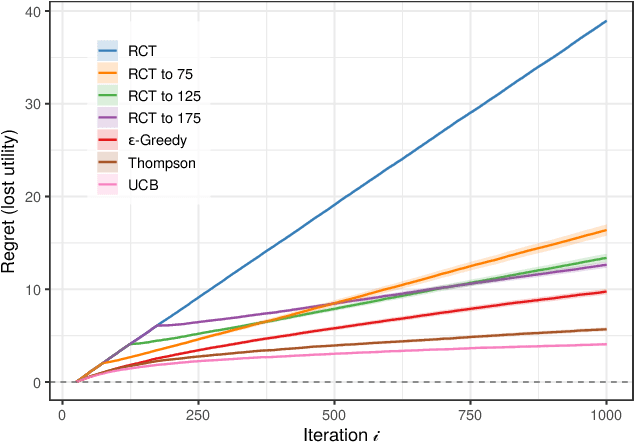
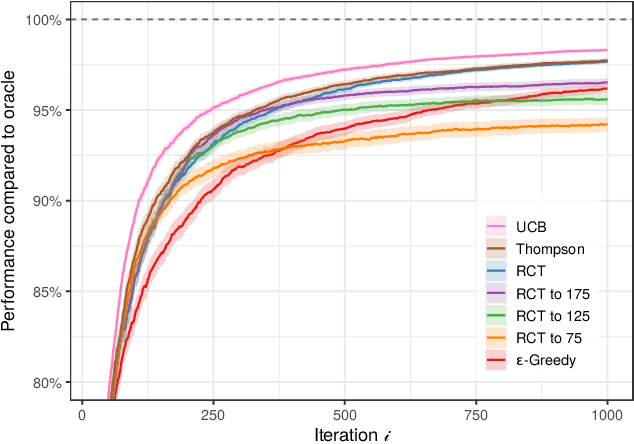
In the dominant paradigm for designing equitable machine learning systems, one works to ensure that model predictions satisfy various fairness criteria, such as parity in error rates across race, gender, and other legally protected traits. That approach, however, typically divorces predictions from the downstream outcomes they ultimately affect, and, as a result, can induce unexpected harms. Here we present an alternative framework for fairness that directly anticipates the consequences of actions. Stakeholders first specify preferences over the possible outcomes of an algorithmically informed decision-making process. For example, lenders may prefer extending credit to those most likely to repay a loan, while also preferring similar lending rates across neighborhoods. One then searches the space of decision policies to maximize the specified utility. We develop and describe a method for efficiently learning these optimal policies from data for a large family of expressive utility functions, facilitating a more holistic approach to equitable decision-making.