 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
STAR: SocioTechnical Approach to Red Teaming Language Models
Jun 17, 2024This research introduces STAR, a sociotechnical framework that improves on current best practices for red teaming safety of large language models. STAR makes two key contributions: it enhances steerability by generating parameterised instructions for human red teamers, leading to improved coverage of the risk surface. Parameterised instructions also provide more detailed insights into model failures at no increased cost. Second, STAR improves signal quality by matching demographics to assess harms for specific groups, resulting in more sensitive annotations. STAR further employs a novel step of arbitration to leverage diverse viewpoints and improve label reliability, treating disagreement not as noise but as a valuable contribution to signal quality.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
BlackJAX: Composable Bayesian inference in JAX
Feb 22, 2024BlackJAX is a library implementing sampling and variational inference algorithms commonly used in Bayesian computation. It is designed for ease of use, speed, and modularity by taking a functional approach to the algorithms' implementation. BlackJAX is written in Python, using JAX to compile and run NumpPy-like samplers and variational methods on CPUs, GPUs, and TPUs. The library integrates well with probabilistic programming languages by working directly with the (un-normalized) target log density function. BlackJAX is intended as a collection of low-level, composable implementations of basic statistical 'atoms' that can be combined to perform well-defined Bayesian inference, but also provides high-level routines for ease of use. It is designed for users who need cutting-edge methods, researchers who want to create complex sampling methods, and people who want to learn how these work.
APTx: better activation function than MISH, SWISH, and ReLU's variants used in deep learning
Sep 14, 2022
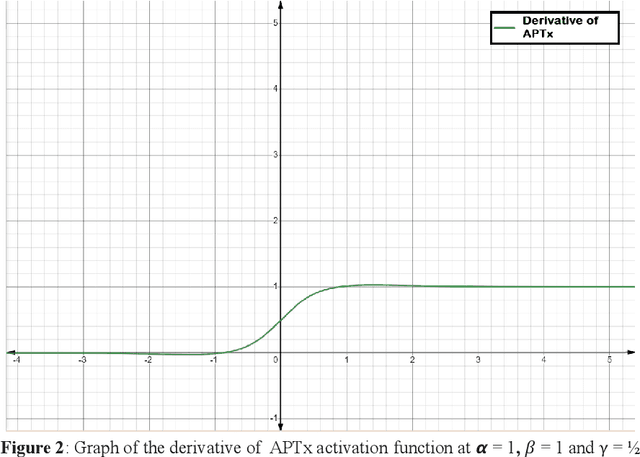


Activation Functions introduce non-linearity in the deep neural networks. This nonlinearity helps the neural networks learn faster and efficiently from the dataset. In deep learning, many activation functions are developed and used based on the type of problem statement. ReLU's variants, SWISH, and MISH are goto activation functions. MISH function is considered having similar or even better performance than SWISH, and much better than ReLU. In this paper, we propose an activation function named APTx which behaves similar to MISH, but requires lesser mathematical operations to compute. The lesser computational requirements of APTx does speed up the model training, and thus also reduces the hardware requirement for the deep learning model.