 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterdiabatic Hamiltonian Monte Carlo
Feb 24, 2026Hamiltonian Monte Carlo (HMC) is a state of the art method for sampling from distributions with differentiable densities, but can converge slowly when applied to challenging multimodal problems. Running HMC with a time varying Hamiltonian, in order to interpolate from an initial tractable distribution to the target of interest, can address this problem. In conjunction with a weighting scheme to eliminate bias, this can be viewed as a special case of Sequential Monte Carlo (SMC) sampling \cite{doucet2001introduction}. However, this approach can be inefficient, since it requires slow change between the initial and final distribution. Inspired by \cite{sels2017minimizing}, where a learned \emph{counterdiabatic} term added to the Hamiltonian allows for efficient quantum state preparation, we propose \emph{Counterdiabatic Hamiltonian Monte Carlo} (CHMC), which can be viewed as an SMC sampler with a more efficient kernel. We establish its relationship to recent proposals for accelerating gradient-based sampling with learned drift terms, and demonstrate on simple benchmark problems.
BlackJAX: Composable Bayesian inference in JAX
Feb 22, 2024BlackJAX is a library implementing sampling and variational inference algorithms commonly used in Bayesian computation. It is designed for ease of use, speed, and modularity by taking a functional approach to the algorithms' implementation. BlackJAX is written in Python, using JAX to compile and run NumpPy-like samplers and variational methods on CPUs, GPUs, and TPUs. The library integrates well with probabilistic programming languages by working directly with the (un-normalized) target log density function. BlackJAX is intended as a collection of low-level, composable implementations of basic statistical 'atoms' that can be combined to perform well-defined Bayesian inference, but also provides high-level routines for ease of use. It is designed for users who need cutting-edge methods, researchers who want to create complex sampling methods, and people who want to learn how these work.
Pragmatic Issue-Sensitive Image Captioning
Apr 29, 2020
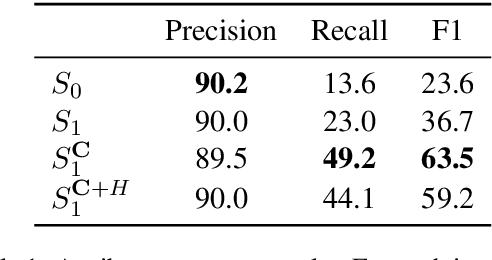
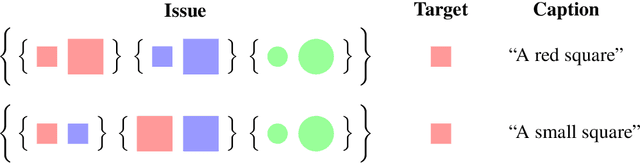
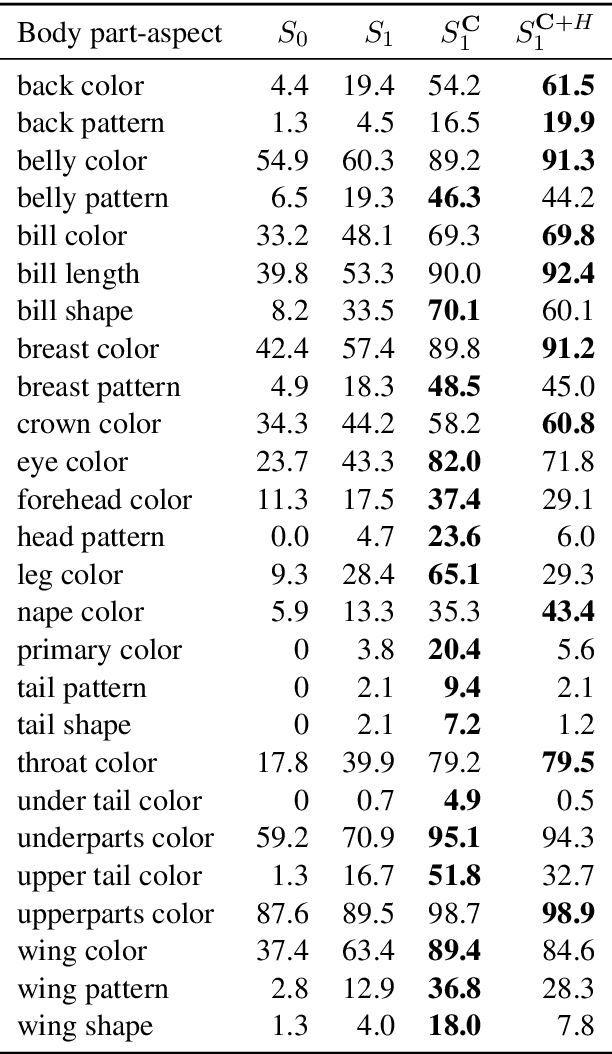
Image captioning systems have recently improved dramatically, but they still tend to produce captions that are insensitive to the communicative goals that captions should meet. To address this, we propose Issue-Sensitive Image Captioning (ISIC). In ISIC, a captioning system is given a target image and an \emph{issue}, which is a set of images partitioned in a way that specifies what information is relevant. The goal of the captioner is to produce a caption that resolves this issue. To model this task, we use an extension of the Rational Speech Acts model of pragmatic language use. Our extension is built on top of state-of-the-art pretrained neural image captioners and explicitly reasons about issues in our sense. We establish experimentally that these models generate captions that are both highly descriptive and issue-sensitive, and we show how ISIC can complement and enrich the related task of Visual Question Answering.
Lexical Learning as an Online Optimal Experiment: Building Efficient Search Engines through Human-Machine Collaboration
Oct 30, 2019
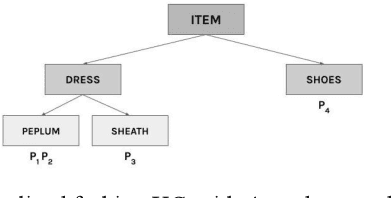
Information retrieval (IR) systems need to constantly update their knowledge as target objects and user queries change over time. Due to the power-law nature of linguistic data, learning lexical concepts is a problem resisting standard machine learning approaches: while manual intervention is always possible, a more general and automated solution is desirable. In this work, we propose a novel end-to-end framework that models the interaction between a search engine and users as a virtuous human-in-the-loop inference. The proposed framework is the first to our knowledge combining ideas from psycholinguistics and experiment design to maximize efficiency in IR. We provide a brief overview of the main components and initial simulations in a toy world, showing how inference works end-to-end and discussing preliminary results and next steps.
Communication-based Evaluation for Natural Language Generation
Oct 11, 2019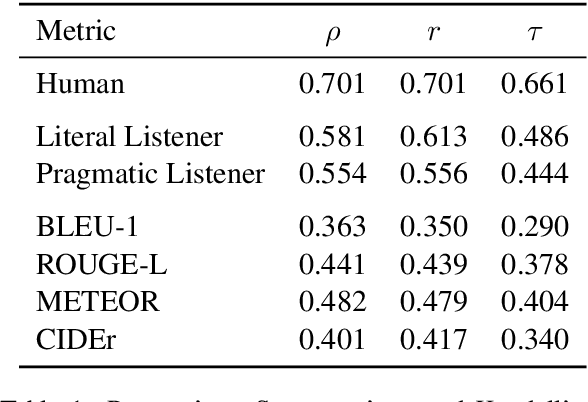

Natural language generation (NLG) systems are commonly evaluated using n-gram overlap measures (e.g. BLEU, ROUGE). These measures do not directly capture semantics or speaker intentions, and so they often turn out to be misaligned with our true goals for NLG. In this work, we argue instead for communication-based evaluations: assuming the purpose of an NLG system is to convey information to a reader/listener, we can directly evaluate its effectiveness at this task using the Rational Speech Acts model of pragmatic language use. We illustrate with a color reference dataset that contains descriptions in pre-defined quality categories, showing that our method better aligns with these quality categories than do any of the prominent n-gram overlap methods.
Lost in Machine Translation: A Method to Reduce Meaning Loss
Apr 12, 2019


A desideratum of high-quality translation systems is that they preserve meaning, in the sense that two sentences with different meanings should not translate to one and the same sentence in another language. However, state-of-the-art systems often fail in this regard, particularly in cases where the source and target languages partition the "meaning space" in different ways. For instance, "I cut my finger." and "I cut my finger off." describe different states of the world but are translated to French (by both Fairseq and Google Translate) as "Je me suis coupe le doigt.", which is ambiguous as to whether the finger is detached. More generally, translation systems are typically many-to-one (non-injective) functions from source to target language, which in many cases results in important distinctions in meaning being lost in translation. Building on Bayesian models of informative utterance production, we present a method to define a less ambiguous translation system in terms of an underlying pre-trained neural sequence-to-sequence model. This method increases injectivity, resulting in greater preservation of meaning as measured by improvement in cycle-consistency, without impeding translation quality (measured by BLEU score).
An Incremental Iterated Response Model of Pragmatics
Oct 19, 2018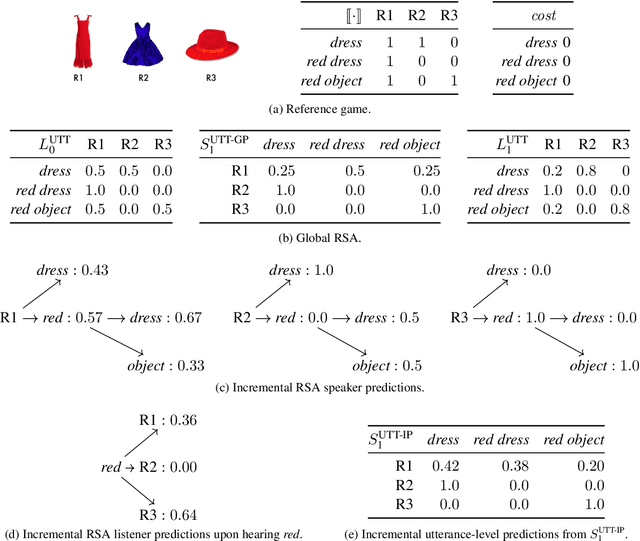



Recent Iterated Response (IR) models of pragmatics conceptualize language use as a recursive process in which agents reason about each other to increase communicative efficiency. These models are generally defined over complete utterances. However, there is substantial evidence that pragmatic reasoning takes place incrementally during production and comprehension. We address this with an incremental IR model. We compare the incremental and global versions using computational simulations, and we assess the incremental model against existing experimental data and in the TUNA corpus for referring expression generation, showing that the model can capture phenomena out of reach of global versions.
Pragmatically Informative Image Captioning with Character-Level Inference
May 10, 2018
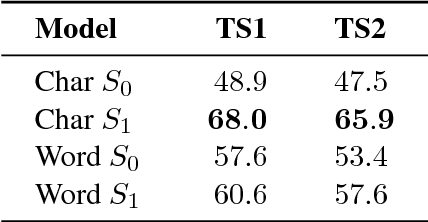

We combine a neural image captioner with a Rational Speech Acts (RSA) model to make a system that is pragmatically informative: its objective is to produce captions that are not merely true but also distinguish their inputs from similar images. Previous attempts to combine RSA with neural image captioning require an inference which normalizes over the entire set of possible utterances. This poses a serious problem of efficiency, previously solved by sampling a small subset of possible utterances. We instead solve this problem by implementing a version of RSA which operates at the level of characters ("a","b","c"...) during the unrolling of the caption. We find that the utterance-level effect of referential captions can be obtained with only character-level decisions. Finally, we introduce an automatic method for testing the performance of pragmatic speaker models, and show that our model outperforms a non-pragmatic baseline as well as a word-level RSA captioner.