Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPTx: better activation function than MISH, SWISH, and ReLU's variants used in deep learning
Paper and Code
Sep 14, 2022
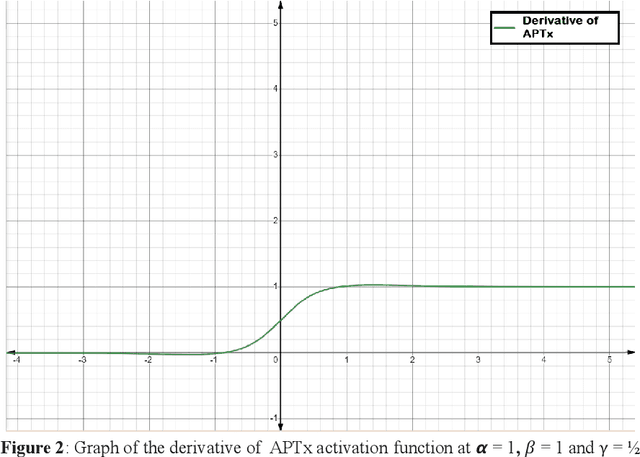


Activation Functions introduce non-linearity in the deep neural networks. This nonlinearity helps the neural networks learn faster and efficiently from the dataset. In deep learning, many activation functions are developed and used based on the type of problem statement. ReLU's variants, SWISH, and MISH are goto activation functions. MISH function is considered having similar or even better performance than SWISH, and much better than ReLU. In this paper, we propose an activation function named APTx which behaves similar to MISH, but requires lesser mathematical operations to compute. The lesser computational requirements of APTx does speed up the model training, and thus also reduces the hardware requirement for the deep learning model.
* 8 pages, 5 figures
View paper on