 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNBA2Vec: Dense feature representations of NBA players
Feb 26, 2023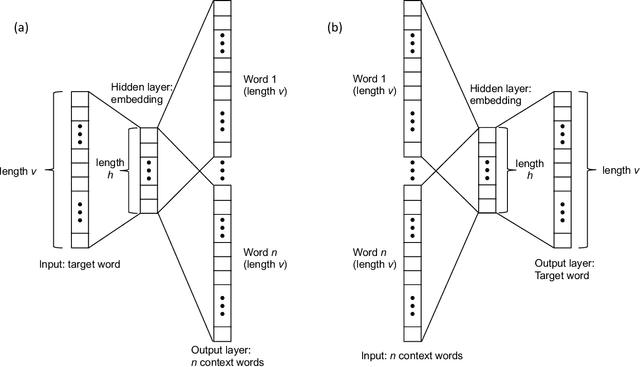
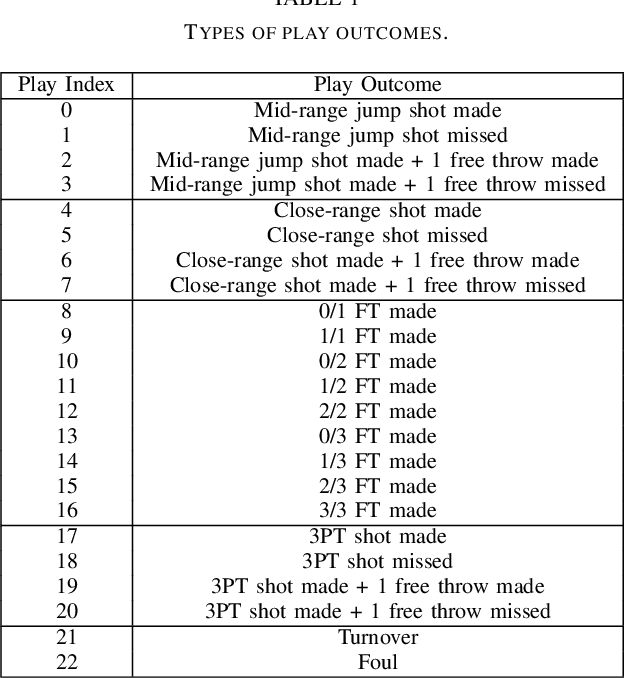
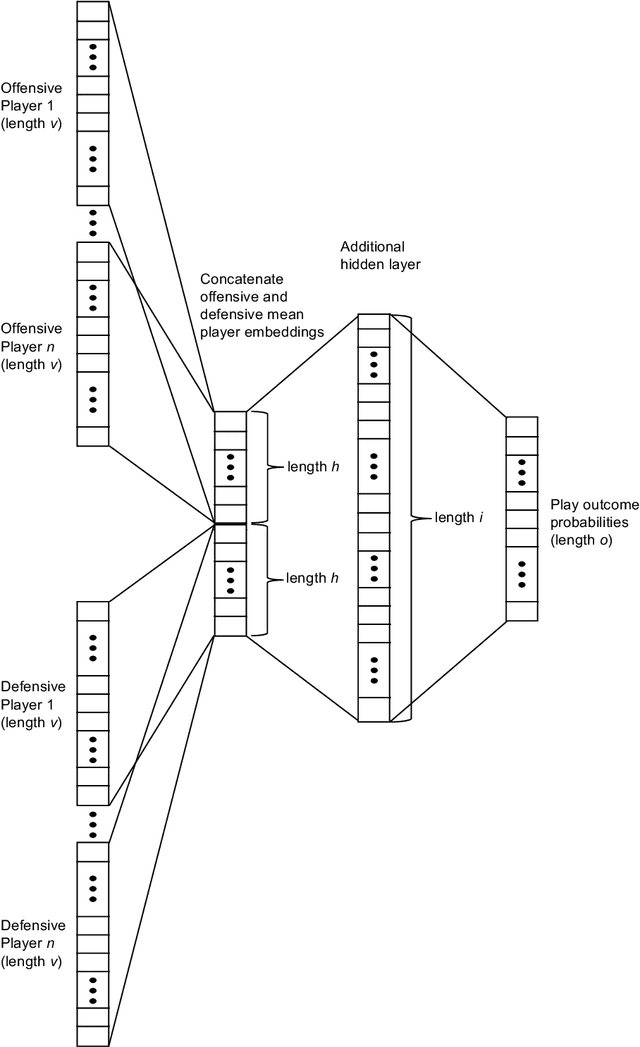
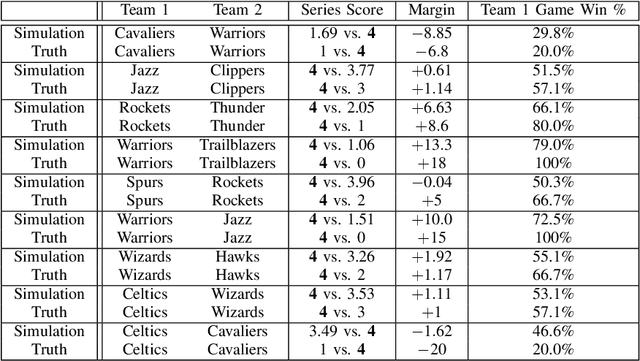
Understanding a player's performance in a basketball game requires an evaluation of the player in the context of their teammates and the opposing lineup. Here, we present NBA2Vec, a neural network model based on Word2Vec which extracts dense feature representations of each player by predicting play outcomes without the use of hand-crafted heuristics or aggregate statistical measures. Specifically, our model aimed to predict the outcome of a possession given both the offensive and defensive players on the court. By training on over 3.5 million plays involving 1551 distinct players, our model was able to achieve a 0.3 K-L divergence with respect to the empirical play-by-play distribution. The resulting embedding space is consistent with general classifications of player position and style, and the embedding dimensions correlated at a significant level with traditional box score metrics. Finally, we demonstrate that NBA2Vec accurately predicts the outcomes to various 2017 NBA Playoffs series, and shows potential in determining optimal lineup match-ups. Future applications of NBA2Vec embeddings to characterize players' style may revolutionize predictive models for player acquisition and coaching decisions that maximize team success.
Integration of Neural Network-Based Symbolic Regression in Deep Learning for Scientific Discovery
Dec 10, 2019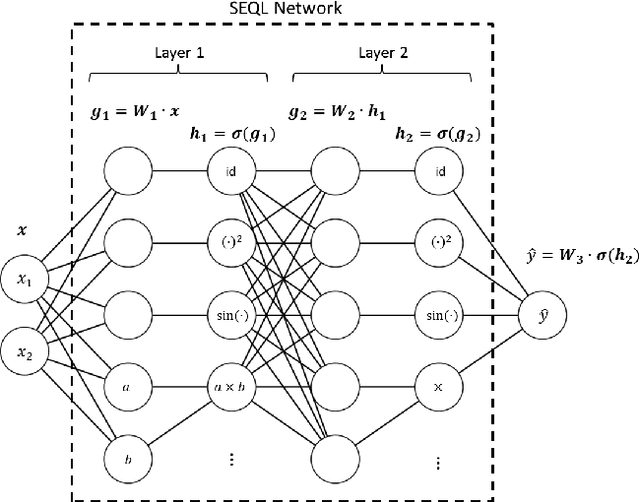
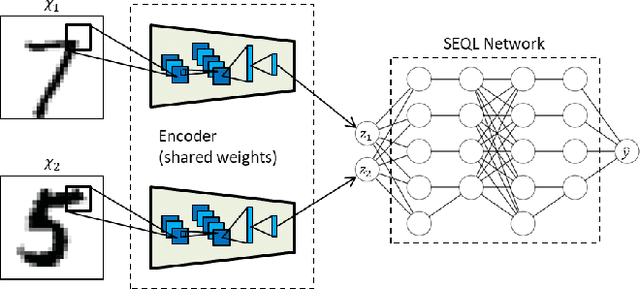
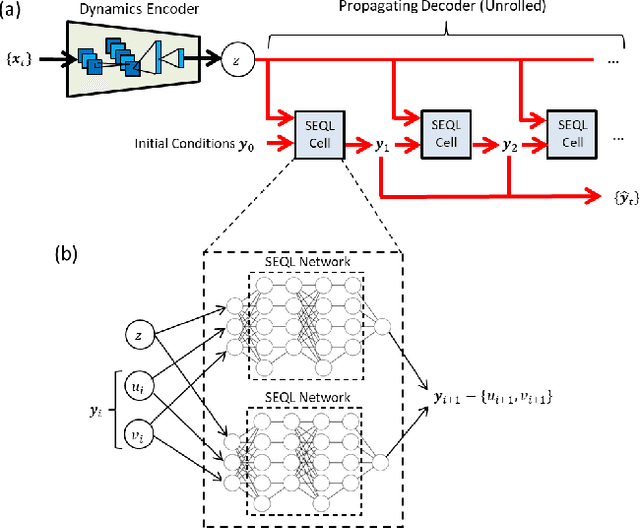
Symbolic regression is a powerful technique that can discover analytical equations that describe data, which can lead to explainable models and generalizability outside of the training data set. In contrast, neural networks have achieved amazing levels of accuracy on image recognition and natural language processing tasks, but are often seen as black-box models that are difficult to interpret and typically extrapolate poorly. Here we use a neural network-based architecture for symbolic regression that we call the Sequential Equation Learner (SEQL) network and integrate it with other deep learning architectures such that the whole system can be trained end-to-end through backpropagation. To demonstrate the power of such systems, we study their performance on several substantially different tasks. First, we show that the neural network can perform symbolic regression and learn the form of several functions. Next, we present an MNIST arithmetic task where a separate part of the neural network extracts the digits. Finally, we demonstrate prediction of dynamical systems where an unknown parameter is extracted through an encoder. We find that the EQL-based architecture can extrapolate quite well outside of the training data set compared to a standard neural network-based architecture, paving the way for deep learning to be applied in scientific exploration and discovery.
Amanuensis: The Programmer's Apprentice
Jun 29, 2018

This document provides an overview of the material covered in a course taught at Stanford in the spring quarter of 2018. The course draws upon insight from cognitive and systems neuroscience to implement hybrid connectionist and symbolic reasoning systems that leverage and extend the state of the art in machine learning by integrating human and machine intelligence. As a concrete example we focus on digital assistants that learn from continuous dialog with an expert software engineer while providing initial value as powerful analytical, computational and mathematical savants. Over time these savants learn cognitive strategies (domain-relevant problem solving skills) and develop intuitions (heuristics and the experience necessary for applying them) by learning from their expert associates. By doing so these savants elevate their innate analytical skills allowing them to partner on an equal footing as versatile collaborators - effectively serving as cognitive extensions and digital prostheses, thereby amplifying and emulating their human partner's conceptually-flexible thinking patterns and enabling improved access to and control over powerful computing resources.
Stem-ming the Tide: Predicting STEM attrition using student transcript data
Aug 28, 2017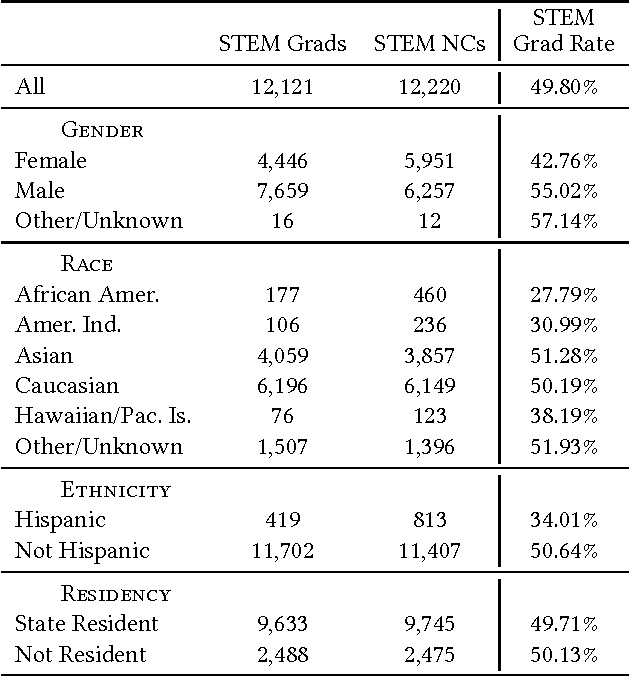
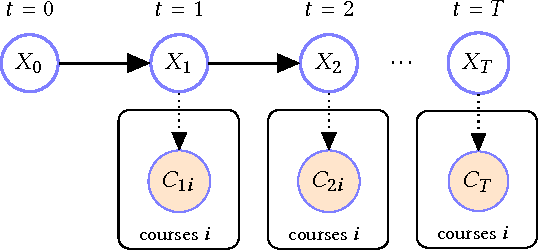
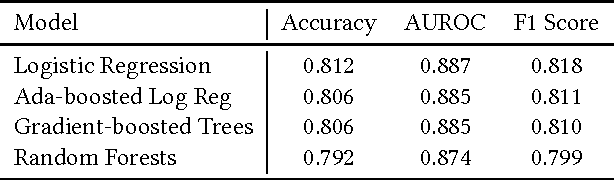
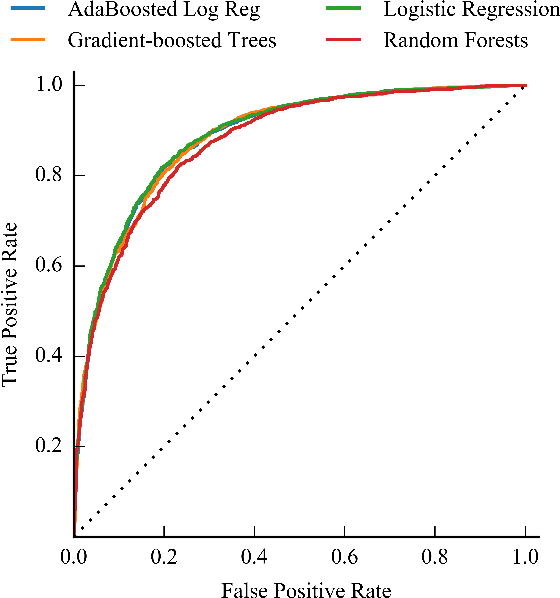
Science, technology, engineering, and math (STEM) fields play growing roles in national and international economies by driving innovation and generating high salary jobs. Yet, the US is lagging behind other highly industrialized nations in terms of STEM education and training. Furthermore, many economic forecasts predict a rising shortage of domestic STEM-trained professions in the US for years to come. One potential solution to this deficit is to decrease the rates at which students leave STEM-related fields in higher education, as currently over half of all students intending to graduate with a STEM degree eventually attrite. However, little quantitative research at scale has looked at causes of STEM attrition, let alone the use of machine learning to examine how well this phenomenon can be predicted. In this paper, we detail our efforts to model and predict dropout from STEM fields using one of the largest known datasets used for research on students at a traditional campus setting. Our results suggest that attrition from STEM fields can be accurately predicted with data that is routinely collected at universities using only information on students' first academic year. We also propose a method to model student STEM intentions for each academic term to better understand the timing of STEM attrition events. We believe these results show great promise in using machine learning to improve STEM retention in traditional and non-traditional campus settings.