 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Stitching: Looking For Functional Similarity Between Representations
Mar 20, 2023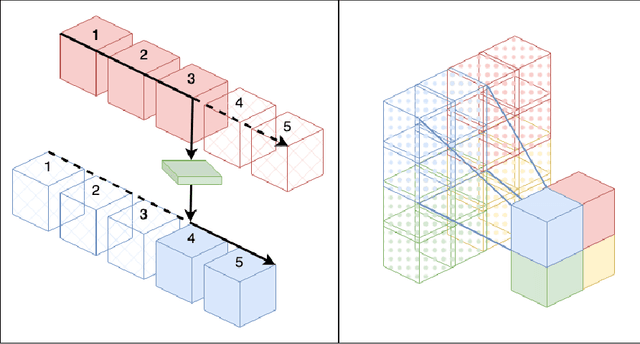

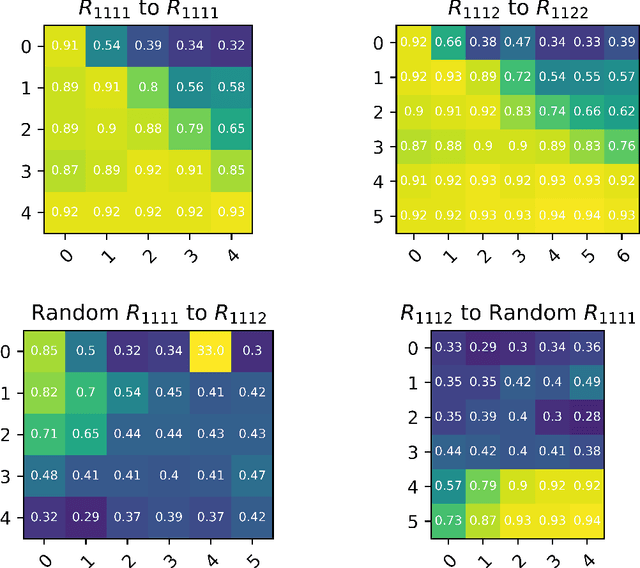
Model stitching (Lenc & Vedaldi 2015) is a compelling methodology to compare different neural network representations, because it allows us to measure to what degree they may be interchanged. We expand on a previous work from Bansal, Nakkiran & Barak which used model stitching to compare representations of the same shapes learned by differently seeded and/or trained neural networks of the same architecture. Our contribution enables us to compare the representations learned by layers with different shapes from neural networks with different architectures. We subsequently reveal unexpected behavior of model stitching. Namely, we find that stitching, based on convolutions, for small ResNets, can reach high accuracy if those layers come later in the first (sender) network than in the second (receiver), even if those layers are far apart.
Multi-Symmetry Ensembles: Improving Diversity and Generalization via Opposing Symmetries
Mar 04, 2023



Deep ensembles (DE) have been successful in improving model performance by learning diverse members via the stochasticity of random initialization. While recent works have attempted to promote further diversity in DE via hyperparameters or regularizing loss functions, these methods primarily still rely on a stochastic approach to explore the hypothesis space. In this work, we present Multi-Symmetry Ensembles (MSE), a framework for constructing diverse ensembles by capturing the multiplicity of hypotheses along symmetry axes, which explore the hypothesis space beyond stochastic perturbations of model weights and hyperparameters. We leverage recent advances in contrastive representation learning to create models that separately capture opposing hypotheses of invariant and equivariant symmetries and present a simple ensembling approach to efficiently combine appropriate hypotheses for a given task. We show that MSE effectively captures the multiplicity of conflicting hypotheses that is often required in large, diverse datasets like ImageNet. As a result of their inherent diversity, MSE improves classification performance, uncertainty quantification, and generalization across a series of transfer tasks.
On the Importance of Calibration in Semi-supervised Learning
Oct 10, 2022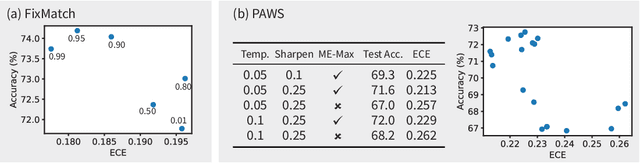
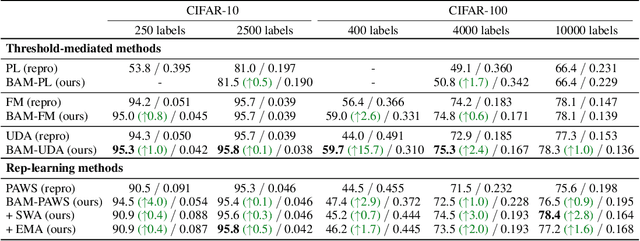
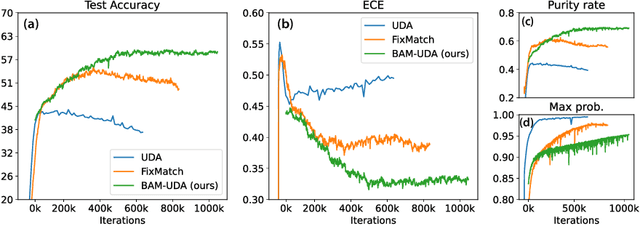
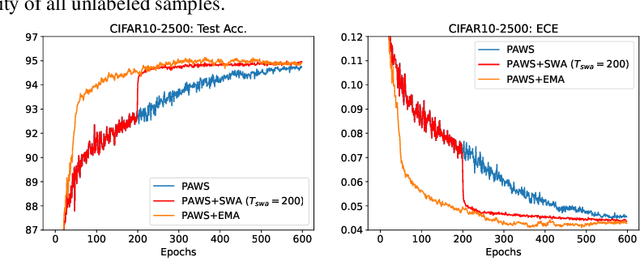
State-of-the-art (SOTA) semi-supervised learning (SSL) methods have been highly successful in leveraging a mix of labeled and unlabeled data by combining techniques of consistency regularization and pseudo-labeling. During pseudo-labeling, the model's predictions on unlabeled data are used for training and thus, model calibration is important in mitigating confirmation bias. Yet, many SOTA methods are optimized for model performance, with little focus directed to improve model calibration. In this work, we empirically demonstrate that model calibration is strongly correlated with model performance and propose to improve calibration via approximate Bayesian techniques. We introduce a family of new SSL models that optimizes for calibration and demonstrate their effectiveness across standard vision benchmarks of CIFAR-10, CIFAR-100 and ImageNet, giving up to 15.9% improvement in test accuracy. Furthermore, we also demonstrate their effectiveness in additional realistic and challenging problems, such as class-imbalanced datasets and in photonics science.
AI-Assisted Discovery of Quantitative and Formal Models in Social Science
Oct 02, 2022In social science, formal and quantitative models, such as ones describing economic growth and collective action, are used to formulate mechanistic explanations, provide predictions, and uncover questions about observed phenomena. Here, we demonstrate the use of a machine learning system to aid the discovery of symbolic models that capture nonlinear and dynamical relationships in social science datasets. By extending neuro-symbolic methods to find compact functions and differential equations in noisy and longitudinal data, we show that our system can be used to discover interpretable models from real-world data in economics and sociology. Augmenting existing workflows with symbolic regression can help uncover novel relationships and explore counterfactual models during the scientific process. We propose that this AI-assisted framework can bridge parametric and non-parametric models commonly employed in social science research by systematically exploring the space of nonlinear models and enabling fine-grained control over expressivity and interpretability.
Surrogate- and invariance-boosted contrastive learning for data-scarce applications in science
Oct 15, 2021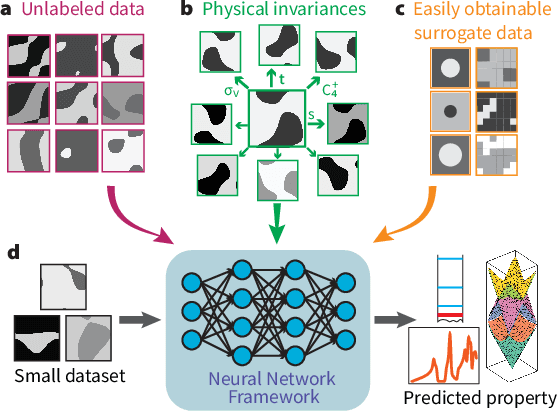
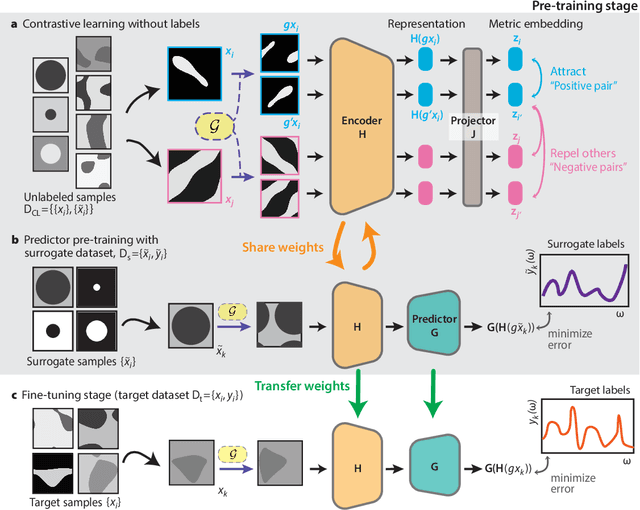
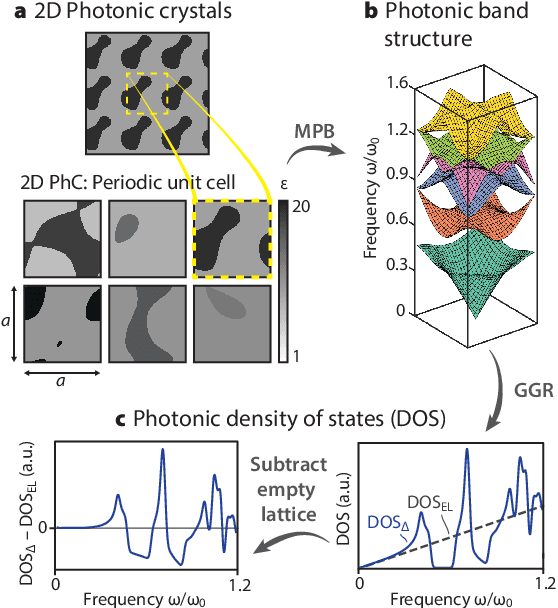
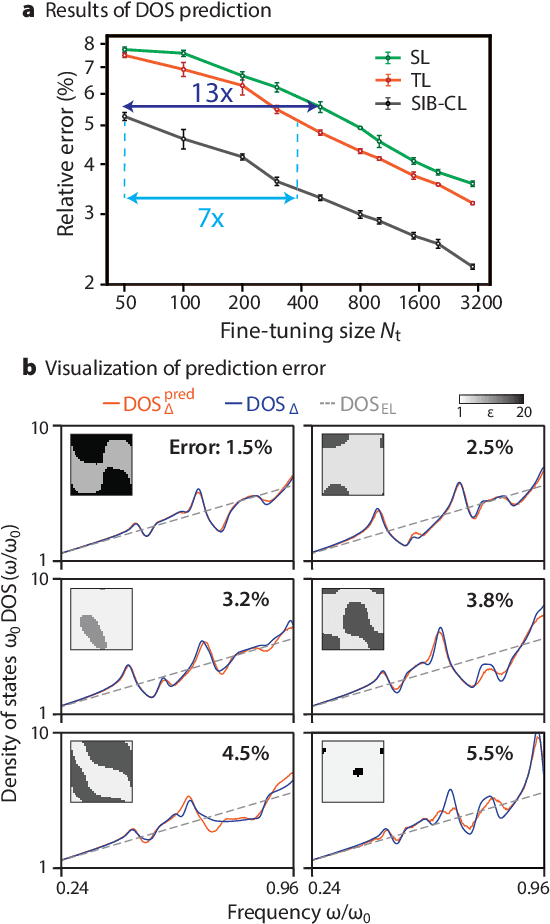
Deep learning techniques have been increasingly applied to the natural sciences, e.g., for property prediction and optimization or material discovery. A fundamental ingredient of such approaches is the vast quantity of labelled data needed to train the model; this poses severe challenges in data-scarce settings where obtaining labels requires substantial computational or labor resources. Here, we introduce surrogate- and invariance-boosted contrastive learning (SIB-CL), a deep learning framework which incorporates three ``inexpensive'' and easily obtainable auxiliary information sources to overcome data scarcity. Specifically, these are: 1)~abundant unlabeled data, 2)~prior knowledge of symmetries or invariances and 3)~surrogate data obtained at near-zero cost. We demonstrate SIB-CL's effectiveness and generality on various scientific problems, e.g., predicting the density-of-states of 2D photonic crystals and solving the 3D time-independent Schrodinger equation. SIB-CL consistently results in orders of magnitude reduction in the number of labels needed to achieve the same network accuracies.
Integration of Neural Network-Based Symbolic Regression in Deep Learning for Scientific Discovery
Dec 10, 2019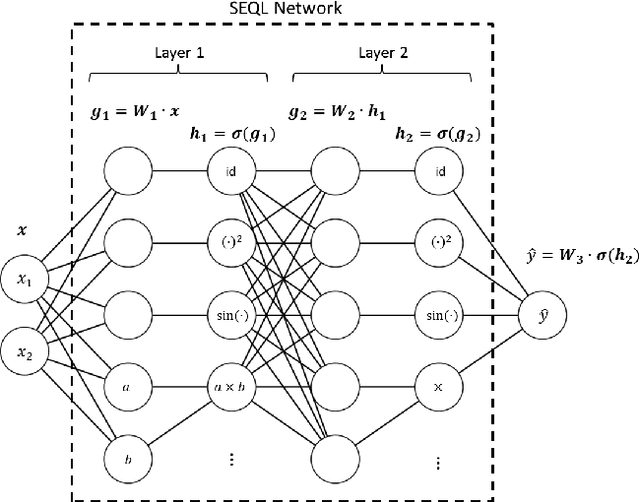
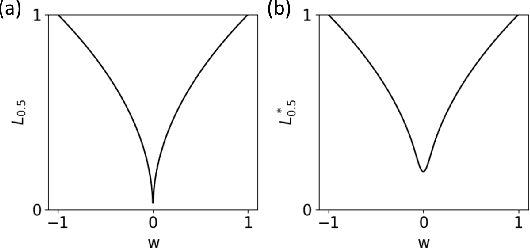
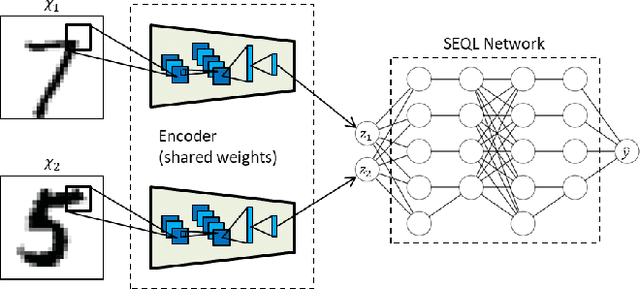
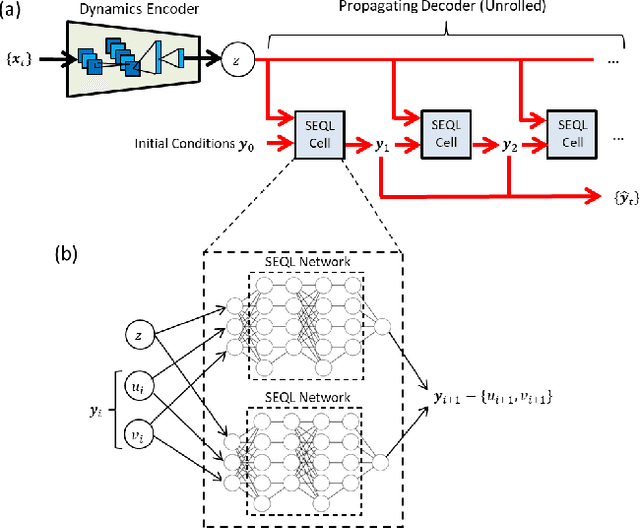
Symbolic regression is a powerful technique that can discover analytical equations that describe data, which can lead to explainable models and generalizability outside of the training data set. In contrast, neural networks have achieved amazing levels of accuracy on image recognition and natural language processing tasks, but are often seen as black-box models that are difficult to interpret and typically extrapolate poorly. Here we use a neural network-based architecture for symbolic regression that we call the Sequential Equation Learner (SEQL) network and integrate it with other deep learning architectures such that the whole system can be trained end-to-end through backpropagation. To demonstrate the power of such systems, we study their performance on several substantially different tasks. First, we show that the neural network can perform symbolic regression and learn the form of several functions. Next, we present an MNIST arithmetic task where a separate part of the neural network extracts the digits. Finally, we demonstrate prediction of dynamical systems where an unknown parameter is extracted through an encoder. We find that the EQL-based architecture can extrapolate quite well outside of the training data set compared to a standard neural network-based architecture, paving the way for deep learning to be applied in scientific exploration and discovery.
WaveletNet: Logarithmic Scale Efficient Convolutional Neural Networks for Edge Devices
Nov 28, 2018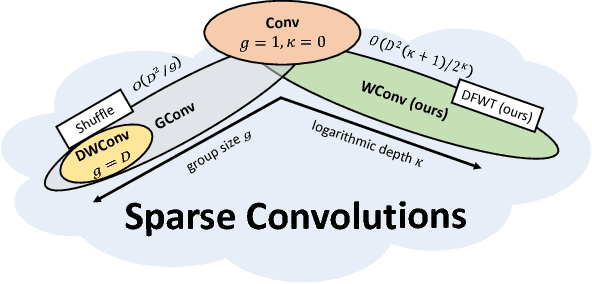
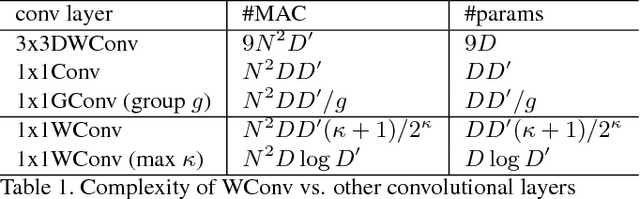
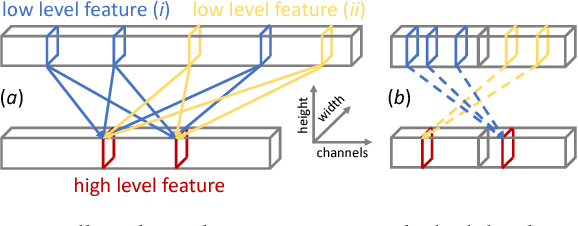
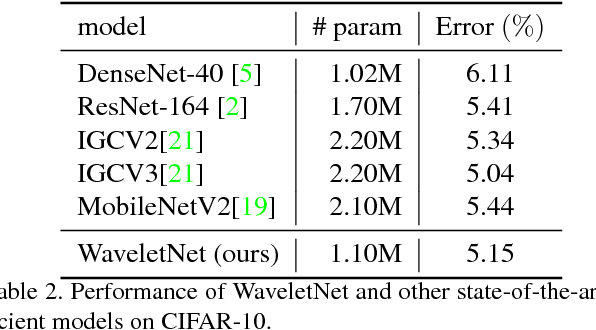
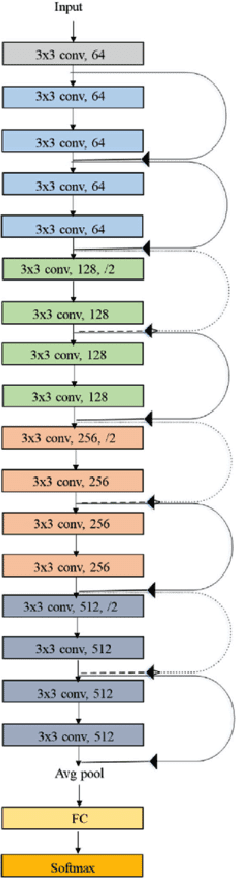
We present a logarithmic-scale efficient convolutional neural network architecture for edge devices, named WaveletNet. Our model is based on the well-known depthwise convolution, and on two new layers, which we introduce in this work: a wavelet convolution and a depthwise fast wavelet transform. By breaking the symmetry in channel dimensions and applying a fast algorithm, WaveletNet shrinks the complexity of convolutional blocks by an O(logD/D) factor, where D is the number of channels. Experiments on CIFAR-10 and ImageNet classification show superior and comparable performances of WaveletNet compared to state-of-the-art models such as MobileNetV2.
Migrating Knowledge between Physical Scenarios based on Artificial Neural Networks
Aug 27, 2018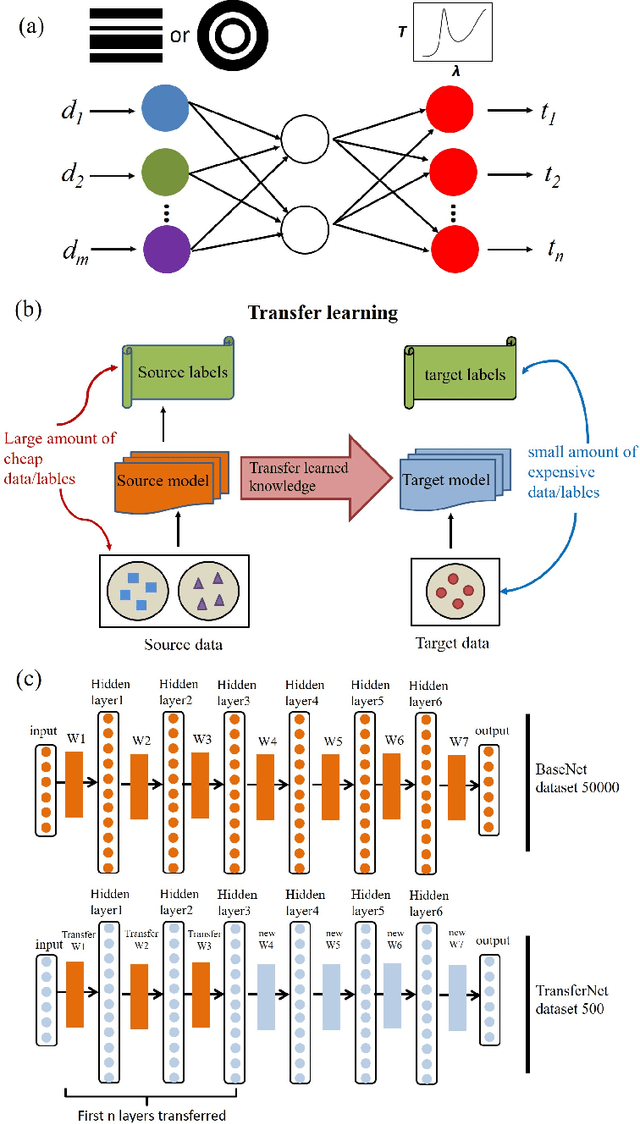

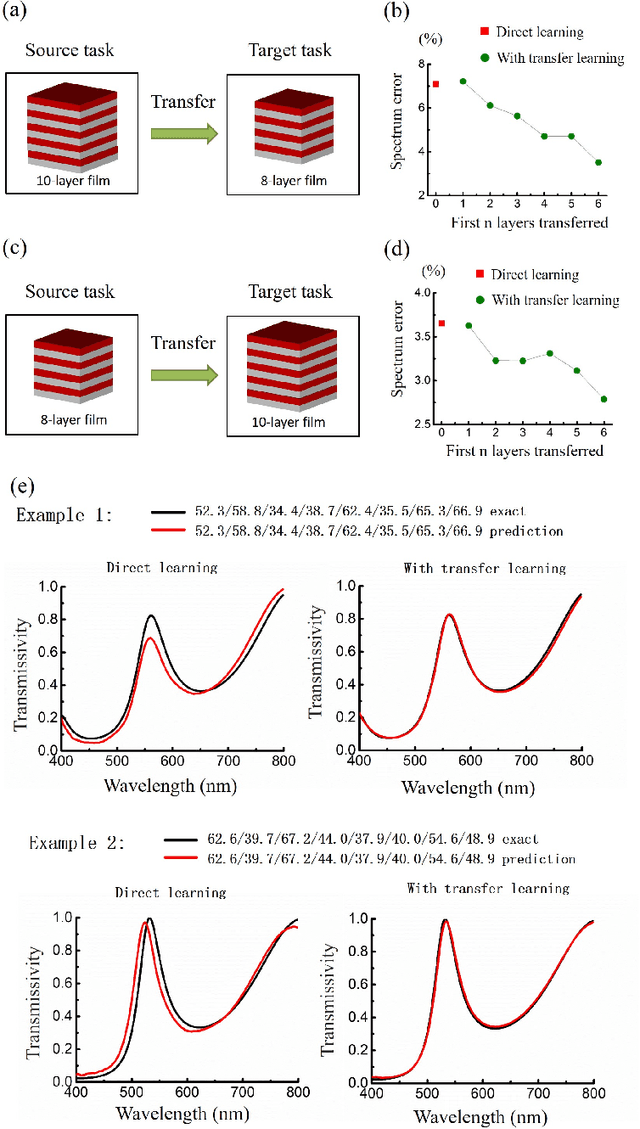
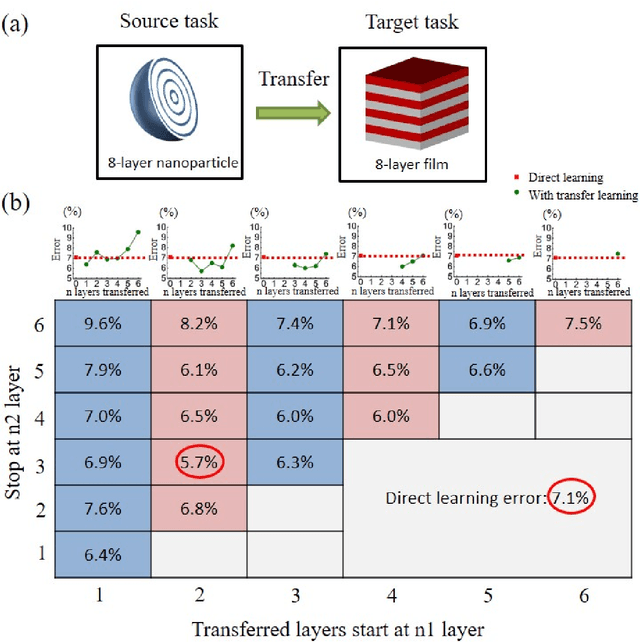
Deep learning is known to be data-hungry, which hinders its application in many areas of science when datasets are small. Here, we propose to use transfer learning methods to migrate knowledge between different physical scenarios and significantly improve the prediction accuracy of artificial neural networks trained on a small dataset. This method can help reduce the demand for expensive data by making use of additional inexpensive data. First, we demonstrate that in predicting the transmission from multilayer photonic film, the relative error rate is reduced by 46.8% (26.5%) when the source data comes from 10-layer (8-layer) films and the target data comes from 8-layer (10-layer) films. Second, we show that the relative error rate is decreased by 22% when knowledge is transferred between two very different physical scenarios: transmission from multilayer films and scattering from multilayer nanoparticles. Finally, we propose a multi-task learning method to improve the performance of different physical scenarios simultaneously in which each task only has a small dataset.
Rotational Unit of Memory
Oct 26, 2017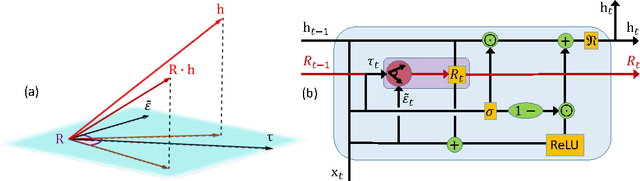

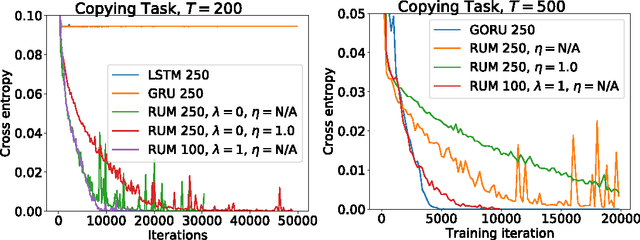

The concepts of unitary evolution matrices and associative memory have boosted the field of Recurrent Neural Networks (RNN) to state-of-the-art performance in a variety of sequential tasks. However, RNN still have a limited capacity to manipulate long-term memory. To bypass this weakness the most successful applications of RNN use external techniques such as attention mechanisms. In this paper we propose a novel RNN model that unifies the state-of-the-art approaches: Rotational Unit of Memory (RUM). The core of RUM is its rotational operation, which is, naturally, a unitary matrix, providing architectures with the power to learn long-term dependencies by overcoming the vanishing and exploding gradients problem. Moreover, the rotational unit also serves as associative memory. We evaluate our model on synthetic memorization, question answering and language modeling tasks. RUM learns the Copying Memory task completely and improves the state-of-the-art result in the Recall task. RUM's performance in the bAbI Question Answering task is comparable to that of models with attention mechanism. We also improve the state-of-the-art result to 1.189 bits-per-character (BPC) loss in the Character Level Penn Treebank (PTB) task, which is to signify the applications of RUM to real-world sequential data. The universality of our construction, at the core of RNN, establishes RUM as a promising approach to language modeling, speech recognition and machine translation.