 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf You Don't Understand It, Don't Use It: Eliminating Trojans with Filters Between Layers
Jul 08, 2024Large language models (LLMs) sometimes exhibit dangerous unintended behaviors. Finding and fixing these is challenging because the attack surface is massive -- it is not tractable to exhaustively search for all possible inputs that may elicit such behavior. One specific and particularly challenging case is that if data-poisoning-injected trojans, since there is no way to know what they are to search for them. To our knowledge, there is no generally applicable method to unlearn unknown trojans injected during pre-training. This work seeks to provide a general purpose recipe (filters) and a specific implementation (LoRA) filters that work in practice on small to medium sized models. The focus is primarily empirical, though some perplexing behavior opens the door to the fundamental question of how LLMs store and process information. Not unexpectedly, we find that our filters work best on the residual stream and the latest layers.
Model Stitching: Looking For Functional Similarity Between Representations
Mar 20, 2023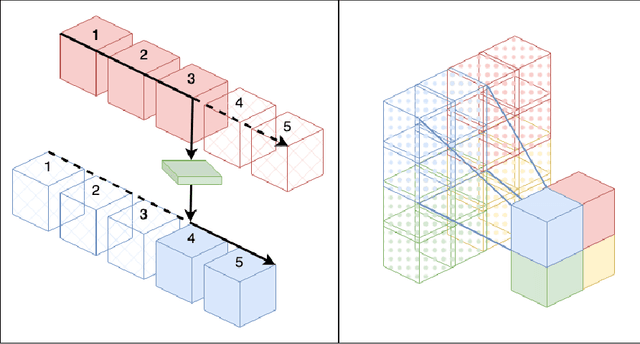

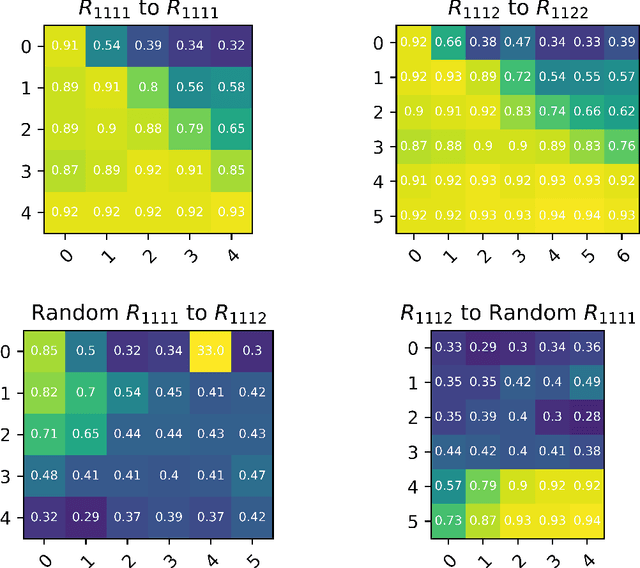
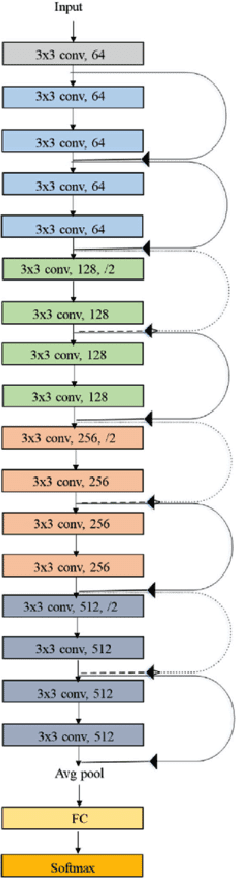
Model stitching (Lenc & Vedaldi 2015) is a compelling methodology to compare different neural network representations, because it allows us to measure to what degree they may be interchanged. We expand on a previous work from Bansal, Nakkiran & Barak which used model stitching to compare representations of the same shapes learned by differently seeded and/or trained neural networks of the same architecture. Our contribution enables us to compare the representations learned by layers with different shapes from neural networks with different architectures. We subsequently reveal unexpected behavior of model stitching. Namely, we find that stitching, based on convolutions, for small ResNets, can reach high accuracy if those layers come later in the first (sender) network than in the second (receiver), even if those layers are far apart.