 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
Feb 12, 2026We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the "sim2real" gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Robust LLM safeguarding via refusal feature adversarial training
Sep 30, 2024

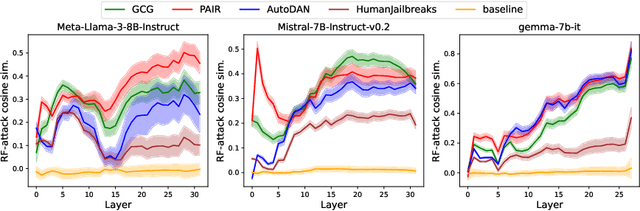

Large language models (LLMs) are vulnerable to adversarial attacks that can elicit harmful responses. Defending against such attacks remains challenging due to the opacity of jailbreaking mechanisms and the high computational cost of training LLMs robustly. We demonstrate that adversarial attacks share a universal mechanism for circumventing LLM safeguards that works by ablating a dimension in the residual stream embedding space called the refusal feature. We further show that the operation of refusal feature ablation (RFA) approximates the worst-case perturbation of offsetting model safety. Based on these findings, we propose Refusal Feature Adversarial Training (ReFAT), a novel algorithm that efficiently performs LLM adversarial training by simulating the effect of input-level attacks via RFA. Experiment results show that ReFAT significantly improves the robustness of three popular LLMs against a wide range of adversarial attacks, with considerably less computational overhead compared to existing adversarial training methods.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Contextual bandits with concave rewards, and an application to fair ranking
Oct 18, 2022
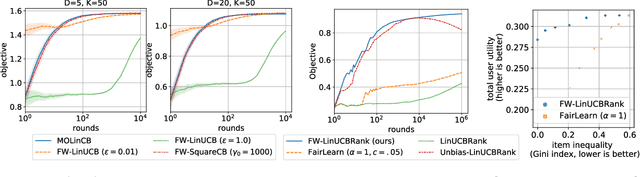
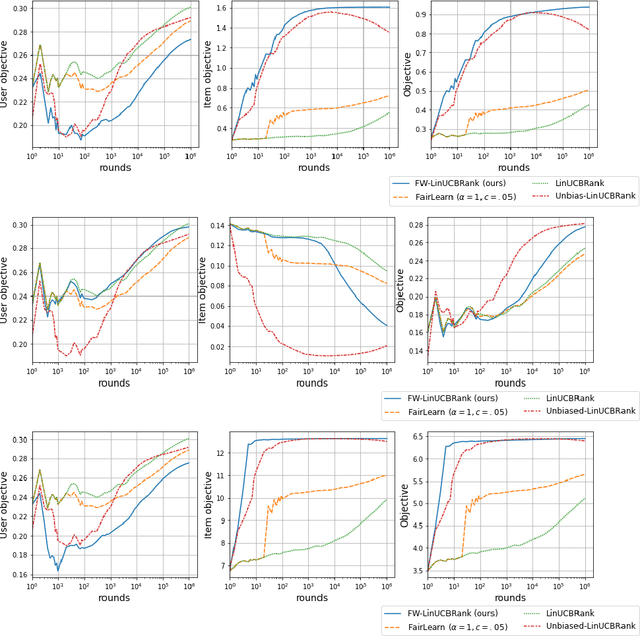
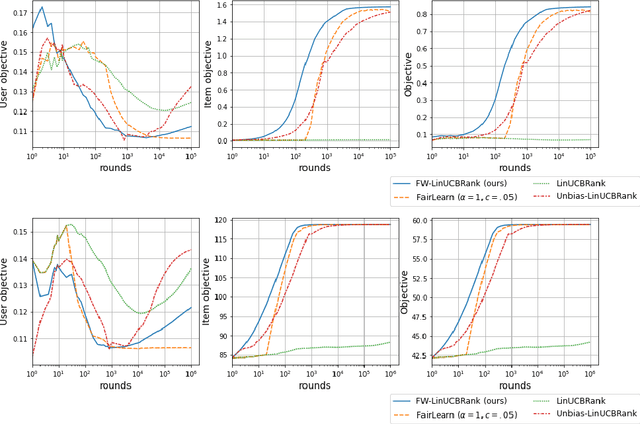
We consider Contextual Bandits with Concave Rewards (CBCR), a multi-objective bandit problem where the desired trade-off between the rewards is defined by a known concave objective function, and the reward vector depends on an observed stochastic context. We present the first algorithm with provably vanishing regret for CBCR without restrictions on the policy space, whereas prior works were restricted to finite policy spaces or tabular representations. Our solution is based on a geometric interpretation of CBCR algorithms as optimization algorithms over the convex set of expected rewards spanned by all stochastic policies. Building on Frank-Wolfe analyses in constrained convex optimization, we derive a novel reduction from the CBCR regret to the regret of a scalar-reward bandit problem. We illustrate how to apply the reduction off-the-shelf to obtain algorithms for CBCR with both linear and general reward functions, in the case of non-combinatorial actions. Motivated by fairness in recommendation, we describe a special case of CBCR with rankings and fairness-aware objectives, leading to the first algorithm with regret guarantees for contextual combinatorial bandits with fairness of exposure.
Fast online ranking with fairness of exposure
Sep 13, 2022
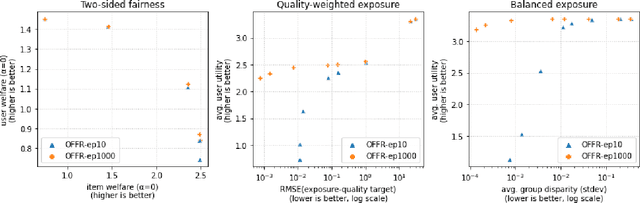
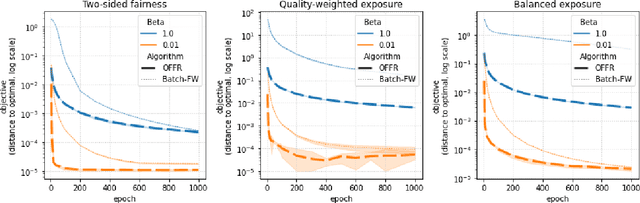
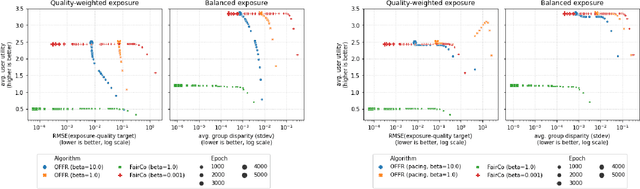
As recommender systems become increasingly central for sorting and prioritizing the content available online, they have a growing impact on the opportunities or revenue of their items producers. For instance, they influence which recruiter a resume is recommended to, or to whom and how much a music track, video or news article is being exposed. This calls for recommendation approaches that not only maximize (a proxy of) user satisfaction, but also consider some notion of fairness in the exposure of items or groups of items. Formally, such recommendations are usually obtained by maximizing a concave objective function in the space of randomized rankings. When the total exposure of an item is defined as the sum of its exposure over users, the optimal rankings of every users become coupled, which makes the optimization process challenging. Existing approaches to find these rankings either solve the global optimization problem in a batch setting, i.e., for all users at once, which makes them inapplicable at scale, or are based on heuristics that have weak theoretical guarantees. In this paper, we propose the first efficient online algorithm to optimize concave objective functions in the space of rankings which applies to every concave and smooth objective function, such as the ones found for fairness of exposure. Based on online variants of the Frank-Wolfe algorithm, we show that our algorithm is computationally fast, generating rankings on-the-fly with computation cost dominated by the sort operation, memory efficient, and has strong theoretical guarantees. Compared to baseline policies that only maximize user-side performance, our algorithm allows to incorporate complex fairness of exposure criteria in the recommendations with negligible computational overhead.
Optimizing generalized Gini indices for fairness in rankings
Apr 14, 2022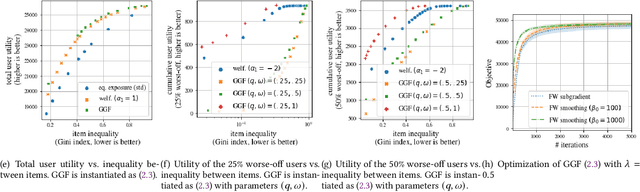
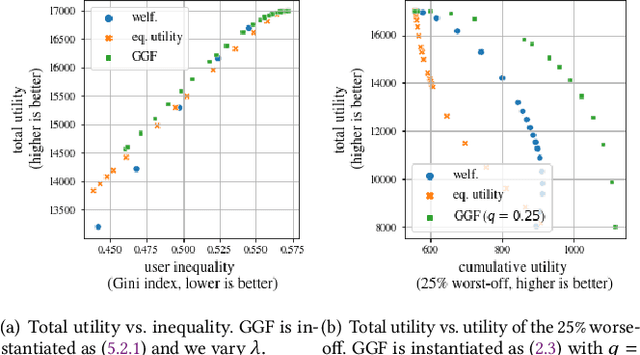
There is growing interest in designing recommender systems that aim at being fair towards item producers or their least satisfied users. Inspired by the domain of inequality measurement in economics, this paper explores the use of generalized Gini welfare functions (GGFs) as a means to specify the normative criterion that recommender systems should optimize for. GGFs weight individuals depending on their ranks in the population, giving more weight to worse-off individuals to promote equality. Depending on these weights, GGFs minimize the Gini index of item exposure to promote equality between items, or focus on the performance on specific quantiles of least satisfied users. GGFs for ranking are challenging to optimize because they are non-differentiable. We resolve this challenge by leveraging tools from non-smooth optimization and projection operators used in differentiable sorting. We present experiments using real datasets with up to 15k users and items, which show that our approach obtains better trade-offs than the baselines on a variety of recommendation tasks and fairness criteria.
Online Approval Committee Elections
Feb 14, 2022Assume $k$ candidates need to be selected. The candidates appear over time. Each time one appears, it must be immediately selected or rejected -- a decision that is made by a group of individuals through voting. Assume the voters use approval ballots, i.e., for each candidate they only specify whether they consider it acceptable or not. This setting can be seen as a voting variant of choosing $k$ secretaries. Our contribution is twofold. (1) We assess to what extent the committees that are computed online can proportionally represent the voters. (2) If a prior probability over candidate approvals is available, we show how to compute committees with maximal expected score.
Two-sided fairness in rankings via Lorenz dominance
Oct 28, 2021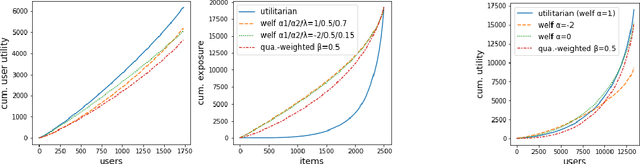

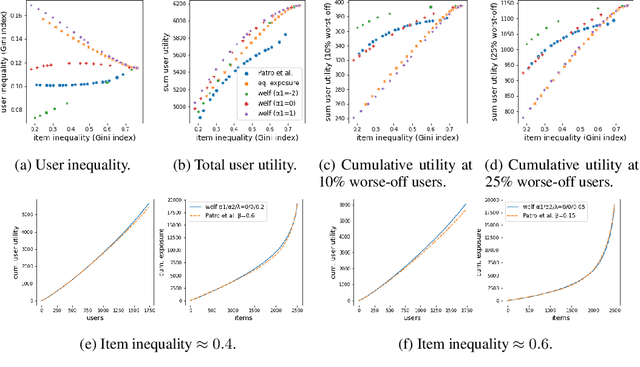

We consider the problem of generating rankings that are fair towards both users and item producers in recommender systems. We address both usual recommendation (e.g., of music or movies) and reciprocal recommendation (e.g., dating). Following concepts of distributive justice in welfare economics, our notion of fairness aims at increasing the utility of the worse-off individuals, which we formalize using the criterion of Lorenz efficiency. It guarantees that rankings are Pareto efficient, and that they maximally redistribute utility from better-off to worse-off, at a given level of overall utility. We propose to generate rankings by maximizing concave welfare functions, and develop an efficient inference procedure based on the Frank-Wolfe algorithm. We prove that unlike existing approaches based on fairness constraints, our approach always produces fair rankings. Our experiments also show that it increases the utility of the worse-off at lower costs in terms of overall utility.
Online Selection of Diverse Committees
May 19, 2021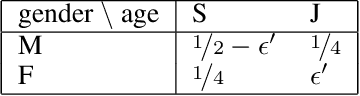


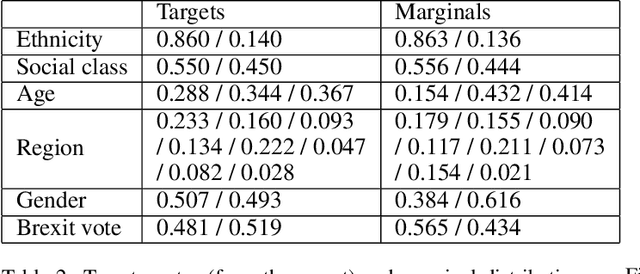
Citizens' assemblies need to represent subpopulations according to their proportions in the general population. These large committees are often constructed in an online fashion by contacting people, asking for the demographic features of the volunteers, and deciding to include them or not. This raises a trade-off between the number of people contacted (and the incurring cost) and the representativeness of the committee. We study three methods, theoretically and experimentally: a greedy algorithm that includes volunteers as long as proportionality is not violated; a non-adaptive method that includes a volunteer with a probability depending only on their features, assuming that the joint feature distribution in the volunteer pool is known; and a reinforcement learning based approach when this distribution is not known a priori but learnt online.