 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Act: Unified Policy for Interleaving Language Reasoning with Actions
Apr 18, 2023



The success of transformer models trained with a language modeling objective brings a promising opportunity to the reinforcement learning framework. Decision Transformer is a step towards this direction, showing how to train transformers with a similar next-step prediction objective on offline data. Another important development in this area is the recent emergence of large-scale datasets collected from the internet, such as the ones composed of tutorial videos with captions where people talk about what they are doing. To take advantage of this language component, we propose a novel method for unifying language reasoning with actions in a single policy. Specifically, we augment a transformer policy with word outputs, so it can generate textual captions interleaved with actions. When tested on the most challenging task in BabyAI, with captions describing next subgoals, our reasoning policy consistently outperforms the caption-free baseline.
Learning Goal-Conditioned Policies Offline with Self-Supervised Reward Shaping
Jan 05, 2023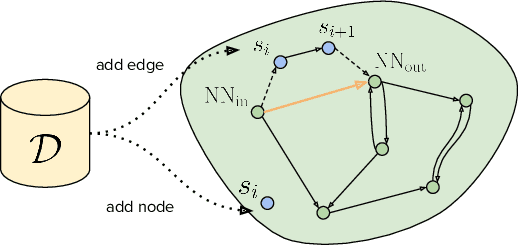
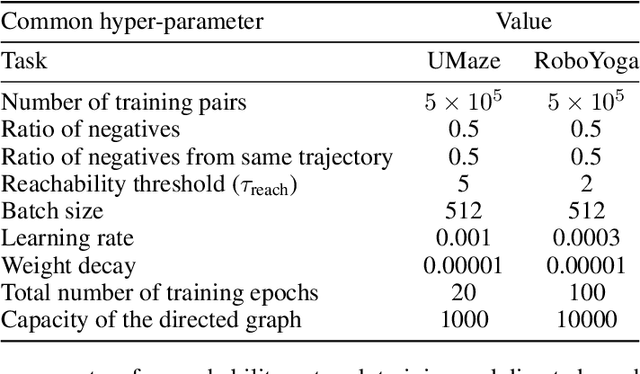
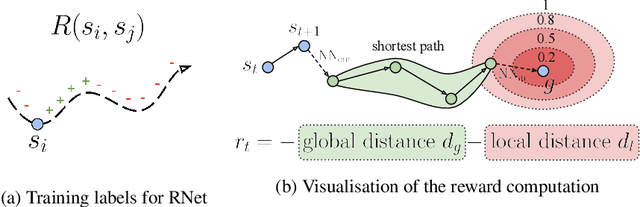
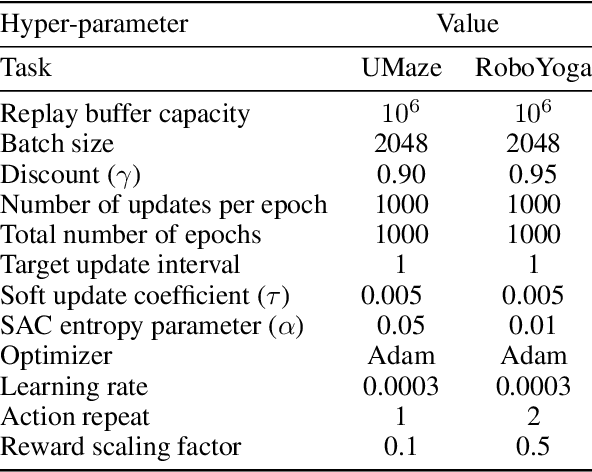
Developing agents that can execute multiple skills by learning from pre-collected datasets is an important problem in robotics, where online interaction with the environment is extremely time-consuming. Moreover, manually designing reward functions for every single desired skill is prohibitive. Prior works targeted these challenges by learning goal-conditioned policies from offline datasets without manually specified rewards, through hindsight relabelling. These methods suffer from the issue of sparsity of rewards, and fail at long-horizon tasks. In this work, we propose a novel self-supervised learning phase on the pre-collected dataset to understand the structure and the dynamics of the model, and shape a dense reward function for learning policies offline. We evaluate our method on three continuous control tasks, and show that our model significantly outperforms existing approaches, especially on tasks that involve long-term planning.
* Code: https://github.com/facebookresearch/go-fresh
Walk the Random Walk: Learning to Discover and Reach Goals Without Supervision
Jun 23, 2022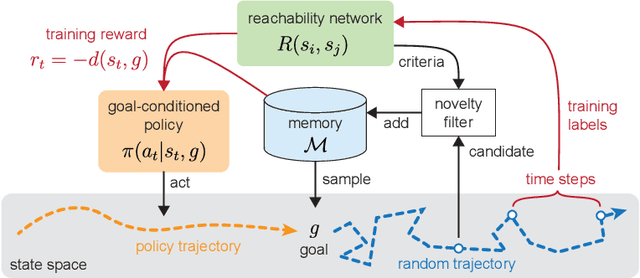
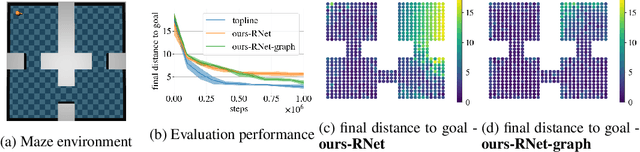
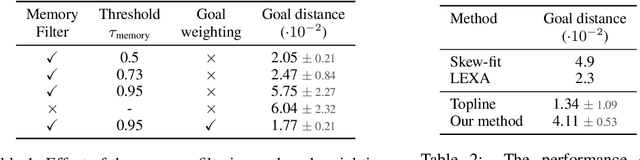
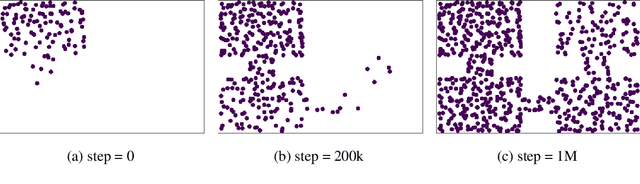
Learning a diverse set of skills by interacting with an environment without any external supervision is an important challenge. In particular, obtaining a goal-conditioned agent that can reach any given state is useful in many applications. We propose a novel method for training such a goal-conditioned agent without any external rewards or any domain knowledge. We use random walk to train a reachability network that predicts the similarity between two states. This reachability network is then used in building goal memory containing past observations that are diverse and well-balanced. Finally, we train a goal-conditioned policy network with goals sampled from the goal memory and reward it by the reachability network and the goal memory. All the components are kept updated throughout training as the agent discovers and learns new goals. We apply our method to a continuous control navigation and robotic manipulation tasks.
Memory-Augmented Reinforcement Learning for Image-Goal Navigation
Jan 13, 2021



In this work, we address the problem of image-goal navigation in the context of visually-realistic 3D environments. This task involves navigating to a location indicated by a target image in a previously unseen environment. Earlier attempts, including RL-based and SLAM-based approaches, have either shown poor generalization performance, or are heavily-reliant on pose/depth sensors. We present a novel method that leverages a cross-episode memory to learn to navigate. We first train a state-embedding network in a self-supervised fashion, and then use it to embed previously-visited states into a memory. In order to avoid overfitting, we propose to use data augmentation on the RGB input during training. We validate our approach through extensive evaluations, showing that our data-augmented memory-based model establishes a new state of the art on the image-goal navigation task in the challenging Gibson dataset. We obtain this competitive performance from RGB input only, without access to additional sensors such as position or depth.
Learning to Visually Navigate in Photorealistic Environments Without any Supervision
Apr 10, 2020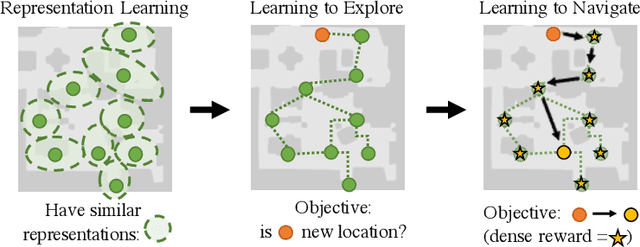



Learning to navigate in a realistic setting where an agent must rely solely on visual inputs is a challenging task, in part because the lack of position information makes it difficult to provide supervision during training. In this paper, we introduce a novel approach for learning to navigate from image inputs without external supervision or reward. Our approach consists of three stages: learning a good representation of first-person views, then learning to explore using memory, and finally learning to navigate by setting its own goals. The model is trained with intrinsic rewards only so that it can be applied to any environment with image observations. We show the benefits of our approach by training an agent to navigate challenging photo-realistic environments from the Gibson dataset with RGB inputs only.
Understanding Image Quality and Trust in Peer-to-Peer Marketplaces
Nov 26, 2018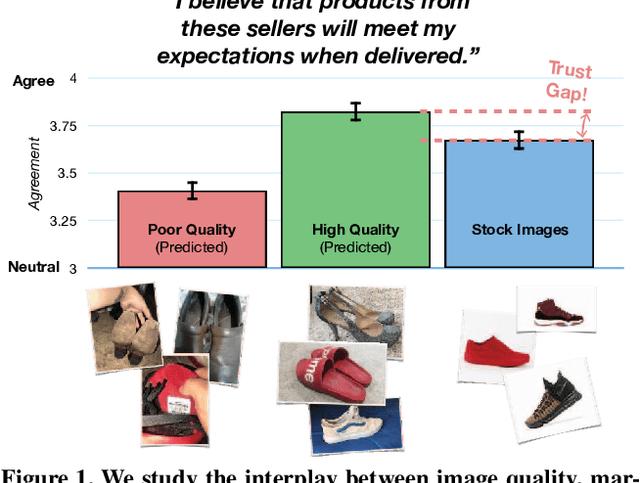

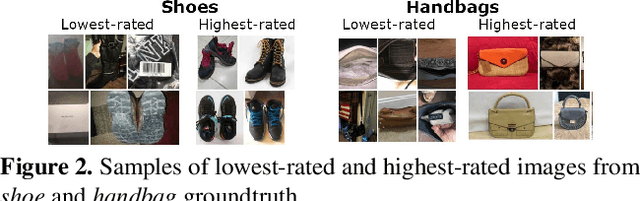
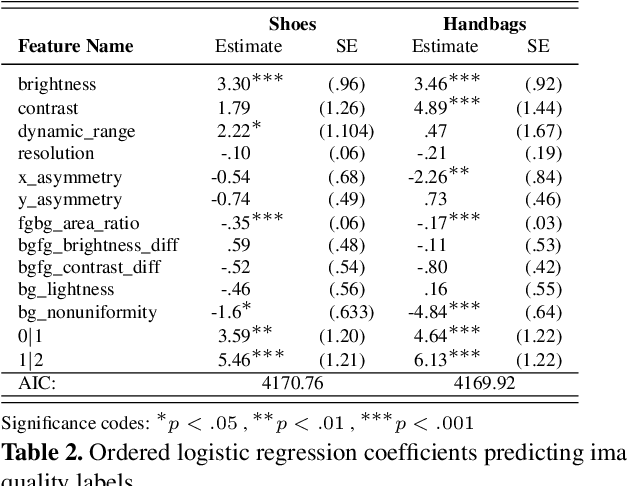
As any savvy online shopper knows, second-hand peer-to-peer marketplaces are filled with images of mixed quality. How does image quality impact marketplace outcomes, and can quality be automatically predicted? In this work, we conducted a large-scale study on the quality of user-generated images in peer-to-peer marketplaces. By gathering a dataset of common second-hand products (~75,000 images) and annotating a subset with human-labeled quality judgments, we were able to model and predict image quality with decent accuracy (~87%). We then conducted two studies focused on understanding the relationship between these image quality scores and two marketplace outcomes: sales and perceived trustworthiness. We show that image quality is associated with higher likelihood that an item will be sold, though other factors such as view count were better predictors of sales. Nonetheless, we show that high quality user-generated images selected by our models outperform stock imagery in eliciting perceptions of trust from users. Our findings can inform the design of future marketplaces and guide potential sellers to take better product images.