 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
D5RL: Diverse Datasets for Data-Driven Deep Reinforcement Learning
Aug 15, 2024
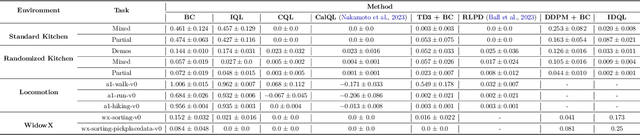

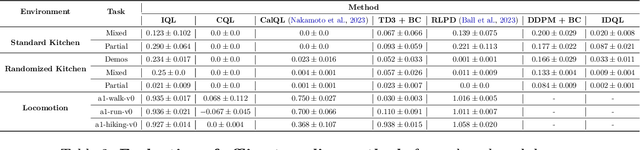
Offline reinforcement learning algorithms hold the promise of enabling data-driven RL methods that do not require costly or dangerous real-world exploration and benefit from large pre-collected datasets. This in turn can facilitate real-world applications, as well as a more standardized approach to RL research. Furthermore, offline RL methods can provide effective initializations for online finetuning to overcome challenges with exploration. However, evaluating progress on offline RL algorithms requires effective and challenging benchmarks that capture properties of real-world tasks, provide a range of task difficulties, and cover a range of challenges both in terms of the parameters of the domain (e.g., length of the horizon, sparsity of rewards) and the parameters of the data (e.g., narrow demonstration data or broad exploratory data). While considerable progress in offline RL in recent years has been enabled by simpler benchmark tasks, the most widely used datasets are increasingly saturating in performance and may fail to reflect properties of realistic tasks. We propose a new benchmark for offline RL that focuses on realistic simulations of robotic manipulation and locomotion environments, based on models of real-world robotic systems, and comprising a variety of data sources, including scripted data, play-style data collected by human teleoperators, and other data sources. Our proposed benchmark covers state-based and image-based domains, and supports both offline RL and online fine-tuning evaluation, with some of the tasks specifically designed to require both pre-training and fine-tuning. We hope that our proposed benchmark will facilitate further progress on both offline RL and fine-tuning algorithms. Website with code, examples, tasks, and data is available at \url{https://sites.google.com/view/d5rl/}
Training Diffusion Models with Reinforcement Learning
May 23, 2023
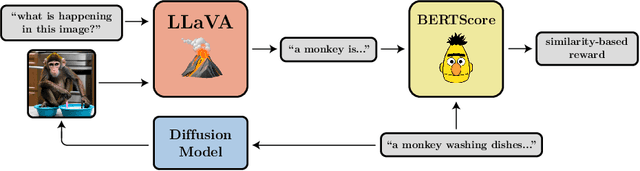

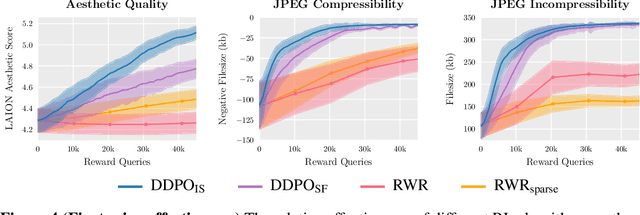
Diffusion models are a class of flexible generative models trained with an approximation to the log-likelihood objective. However, most use cases of diffusion models are not concerned with likelihoods, but instead with downstream objectives such as human-perceived image quality or drug effectiveness. In this paper, we investigate reinforcement learning methods for directly optimizing diffusion models for such objectives. We describe how posing denoising as a multi-step decision-making problem enables a class of policy gradient algorithms, which we refer to as denoising diffusion policy optimization (DDPO), that are more effective than alternative reward-weighted likelihood approaches. Empirically, DDPO is able to adapt text-to-image diffusion models to objectives that are difficult to express via prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality. Finally, we show that DDPO can improve prompt-image alignment using feedback from a vision-language model without the need for additional data collection or human annotation.
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Apr 20, 2023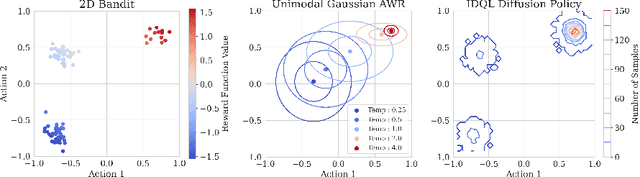
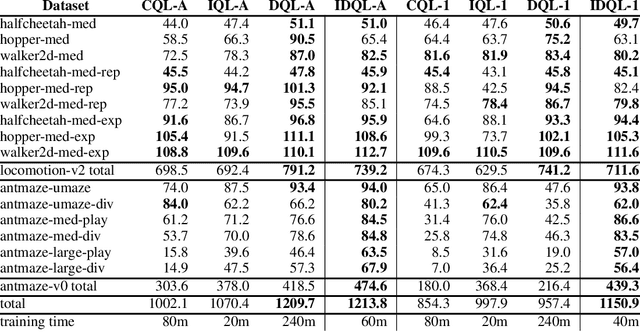

Effective offline RL methods require properly handling out-of-distribution actions. Implicit Q-learning (IQL) addresses this by training a Q-function using only dataset actions through a modified Bellman backup. However, it is unclear which policy actually attains the values represented by this implicitly trained Q-function. In this paper, we reinterpret IQL as an actor-critic method by generalizing the critic objective and connecting it to a behavior-regularized implicit actor. This generalization shows how the induced actor balances reward maximization and divergence from the behavior policy, with the specific loss choice determining the nature of this tradeoff. Notably, this actor can exhibit complex and multimodal characteristics, suggesting issues with the conditional Gaussian actor fit with advantage weighted regression (AWR) used in prior methods. Instead, we propose using samples from a diffusion parameterized behavior policy and weights computed from the critic to then importance sampled our intended policy. We introduce Implicit Diffusion Q-learning (IDQL), combining our general IQL critic with the policy extraction method. IDQL maintains the ease of implementation of IQL while outperforming prior offline RL methods and demonstrating robustness to hyperparameters. Code is available at https://github.com/philippe-eecs/IDQL.
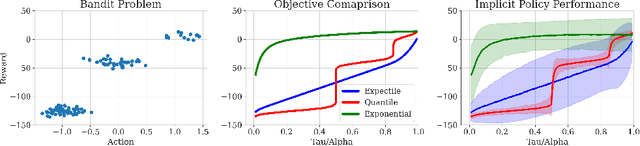
Efficient Deep Reinforcement Learning Requires Regulating Overfitting
Apr 20, 2023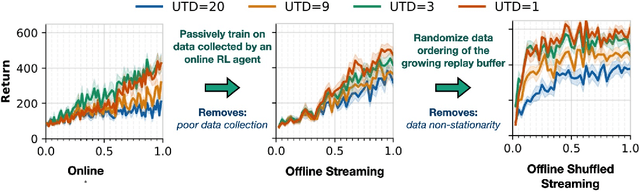

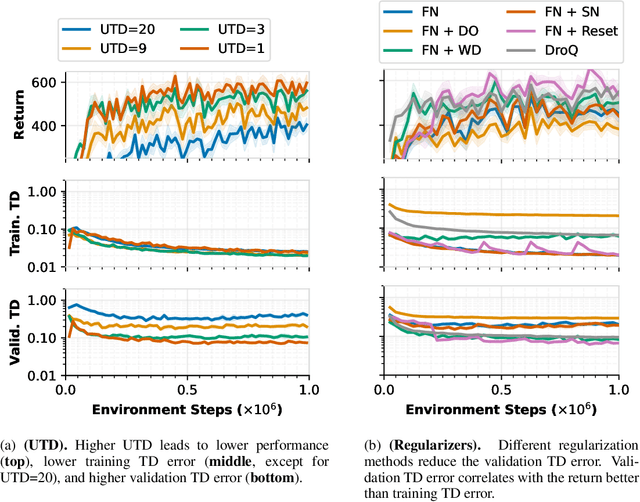

Deep reinforcement learning algorithms that learn policies by trial-and-error must learn from limited amounts of data collected by actively interacting with the environment. While many prior works have shown that proper regularization techniques are crucial for enabling data-efficient RL, a general understanding of the bottlenecks in data-efficient RL has remained unclear. Consequently, it has been difficult to devise a universal technique that works well across all domains. In this paper, we attempt to understand the primary bottleneck in sample-efficient deep RL by examining several potential hypotheses such as non-stationarity, excessive action distribution shift, and overfitting. We perform thorough empirical analysis on state-based DeepMind control suite (DMC) tasks in a controlled and systematic way to show that high temporal-difference (TD) error on the validation set of transitions is the main culprit that severely affects the performance of deep RL algorithms, and prior methods that lead to good performance do in fact, control the validation TD error to be low. This observation gives us a robust principle for making deep RL efficient: we can hill-climb on the validation TD error by utilizing any form of regularization techniques from supervised learning. We show that a simple online model selection method that targets the validation TD error is effective across state-based DMC and Gym tasks.
FastRLAP: A System for Learning High-Speed Driving via Deep RL and Autonomous Practicing
Apr 19, 2023
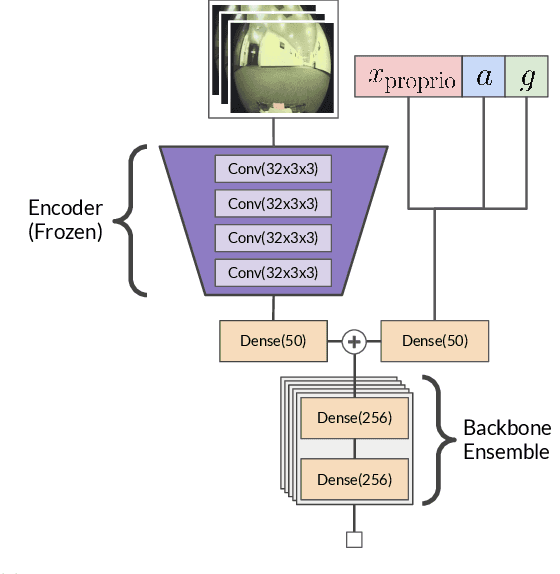
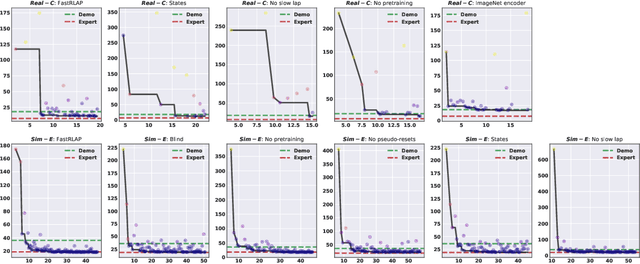

We present a system that enables an autonomous small-scale RC car to drive aggressively from visual observations using reinforcement learning (RL). Our system, FastRLAP (faster lap), trains autonomously in the real world, without human interventions, and without requiring any simulation or expert demonstrations. Our system integrates a number of important components to make this possible: we initialize the representations for the RL policy and value function from a large prior dataset of other robots navigating in other environments (at low speed), which provides a navigation-relevant representation. From here, a sample-efficient online RL method uses a single low-speed user-provided demonstration to determine the desired driving course, extracts a set of navigational checkpoints, and autonomously practices driving through these checkpoints, resetting automatically on collision or failure. Perhaps surprisingly, we find that with appropriate initialization and choice of algorithm, our system can learn to drive over a variety of racing courses with less than 20 minutes of online training. The resulting policies exhibit emergent aggressive driving skills, such as timing braking and acceleration around turns and avoiding areas which impede the robot's motion, approaching the performance of a human driver using a similar first-person interface over the course of training.
Efficient Online Reinforcement Learning with Offline Data
Feb 15, 2023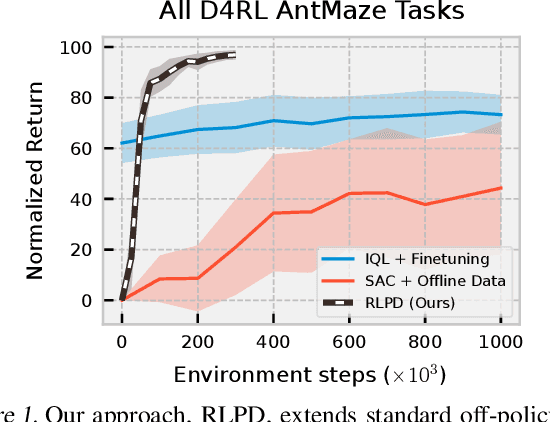

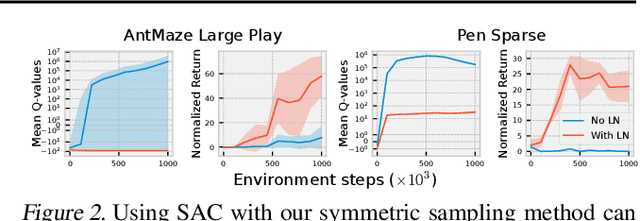

Sample efficiency and exploration remain major challenges in online reinforcement learning (RL). A powerful approach that can be applied to address these issues is the inclusion of offline data, such as prior trajectories from a human expert or a sub-optimal exploration policy. Previous methods have relied on extensive modifications and additional complexity to ensure the effective use of this data. Instead, we ask: can we simply apply existing off-policy methods to leverage offline data when learning online? In this work, we demonstrate that the answer is yes; however, a set of minimal but important changes to existing off-policy RL algorithms are required to achieve reliable performance. We extensively ablate these design choices, demonstrating the key factors that most affect performance, and arrive at a set of recommendations that practitioners can readily apply, whether their data comprise a small number of expert demonstrations or large volumes of sub-optimal trajectories. We see that correct application of these simple recommendations can provide a $\mathbf{2.5\times}$ improvement over existing approaches across a diverse set of competitive benchmarks, with no additional computational overhead.
Offline Reinforcement Learning for Visual Navigation
Dec 16, 2022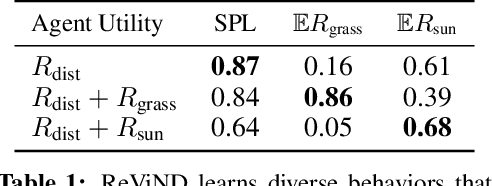
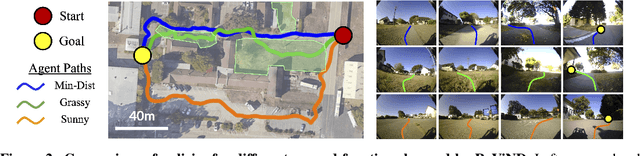
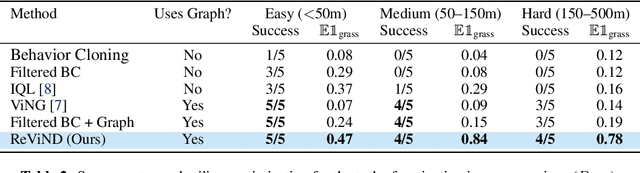
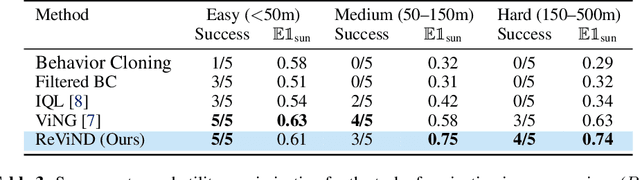
Reinforcement learning can enable robots to navigate to distant goals while optimizing user-specified reward functions, including preferences for following lanes, staying on paved paths, or avoiding freshly mowed grass. However, online learning from trial-and-error for real-world robots is logistically challenging, and methods that instead can utilize existing datasets of robotic navigation data could be significantly more scalable and enable broader generalization. In this paper, we present ReViND, the first offline RL system for robotic navigation that can leverage previously collected data to optimize user-specified reward functions in the real-world. We evaluate our system for off-road navigation without any additional data collection or fine-tuning, and show that it can navigate to distant goals using only offline training from this dataset, and exhibit behaviors that qualitatively differ based on the user-specified reward function.