 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Experience Replay
Mar 12, 2023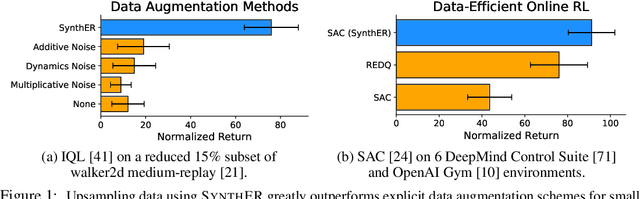



A key theme in the past decade has been that when large neural networks and large datasets combine they can produce remarkable results. In deep reinforcement learning (RL), this paradigm is commonly made possible through experience replay, whereby a dataset of past experiences is used to train a policy or value function. However, unlike in supervised or self-supervised learning, an RL agent has to collect its own data, which is often limited. Thus, it is challenging to reap the benefits of deep learning, and even small neural networks can overfit at the start of training. In this work, we leverage the tremendous recent progress in generative modeling and propose Synthetic Experience Replay (SynthER), a diffusion-based approach to arbitrarily upsample an agent's collected experience. We show that SynthER is an effective method for training RL agents across offline and online settings. In offline settings, we observe drastic improvements both when upsampling small offline datasets and when training larger networks with additional synthetic data. Furthermore, SynthER enables online agents to train with a much higher update-to-data ratio than before, leading to a large increase in sample efficiency, without any algorithmic changes. We believe that synthetic training data could open the door to realizing the full potential of deep learning for replay-based RL algorithms from limited data.
Efficient Online Reinforcement Learning with Offline Data
Feb 15, 2023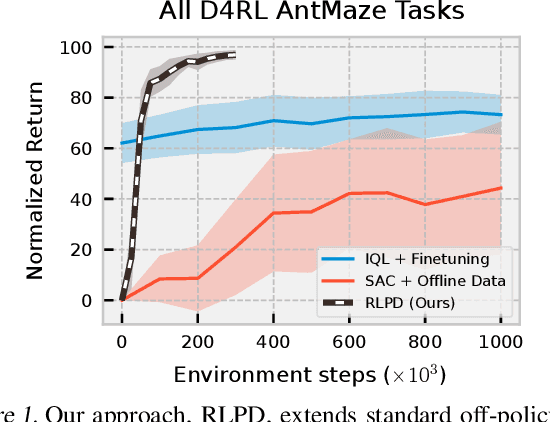

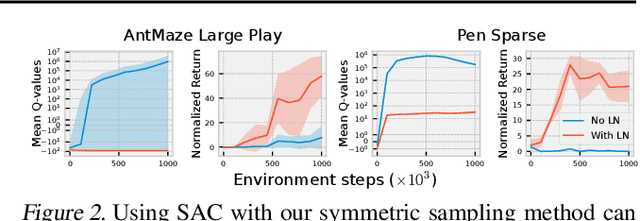

Sample efficiency and exploration remain major challenges in online reinforcement learning (RL). A powerful approach that can be applied to address these issues is the inclusion of offline data, such as prior trajectories from a human expert or a sub-optimal exploration policy. Previous methods have relied on extensive modifications and additional complexity to ensure the effective use of this data. Instead, we ask: can we simply apply existing off-policy methods to leverage offline data when learning online? In this work, we demonstrate that the answer is yes; however, a set of minimal but important changes to existing off-policy RL algorithms are required to achieve reliable performance. We extensively ablate these design choices, demonstrating the key factors that most affect performance, and arrive at a set of recommendations that practitioners can readily apply, whether their data comprise a small number of expert demonstrations or large volumes of sub-optimal trajectories. We see that correct application of these simple recommendations can provide a $\mathbf{2.5\times}$ improvement over existing approaches across a diverse set of competitive benchmarks, with no additional computational overhead.
Learning General World Models in a Handful of Reward-Free Deployments
Oct 23, 2022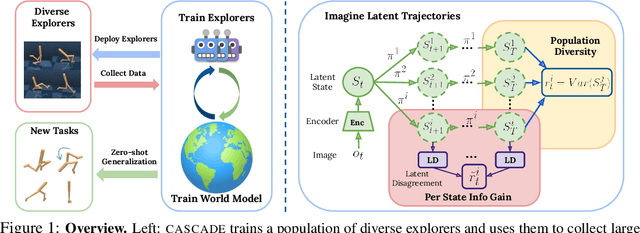
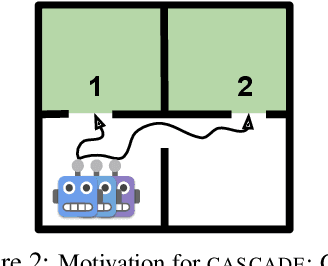
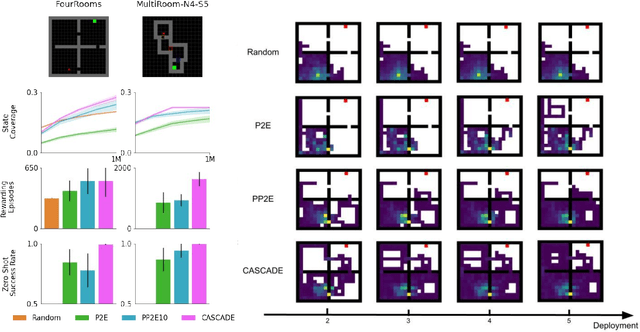
Building generally capable agents is a grand challenge for deep reinforcement learning (RL). To approach this challenge practically, we outline two key desiderata: 1) to facilitate generalization, exploration should be task agnostic; 2) to facilitate scalability, exploration policies should collect large quantities of data without costly centralized retraining. Combining these two properties, we introduce the reward-free deployment efficiency setting, a new paradigm for RL research. We then present CASCADE, a novel approach for self-supervised exploration in this new setting. CASCADE seeks to learn a world model by collecting data with a population of agents, using an information theoretic objective inspired by Bayesian Active Learning. CASCADE achieves this by specifically maximizing the diversity of trajectories sampled by the population through a novel cascading objective. We provide theoretical intuition for CASCADE which we show in a tabular setting improves upon na\"ive approaches that do not account for population diversity. We then demonstrate that CASCADE collects diverse task-agnostic datasets and learns agents that generalize zero-shot to novel, unseen downstream tasks on Atari, MiniGrid, Crafter and the DM Control Suite. Code and videos are available at https://ycxuyingchen.github.io/cascade/
Bayesian Generational Population-Based Training
Jul 19, 2022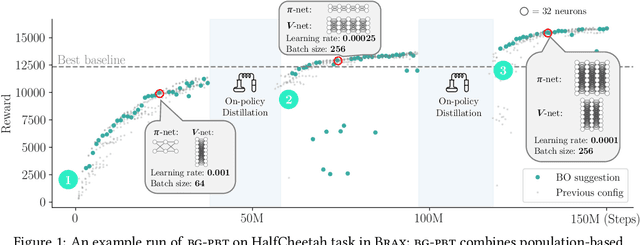

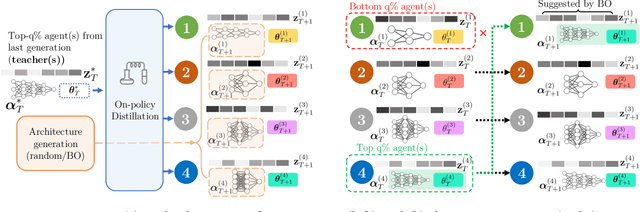
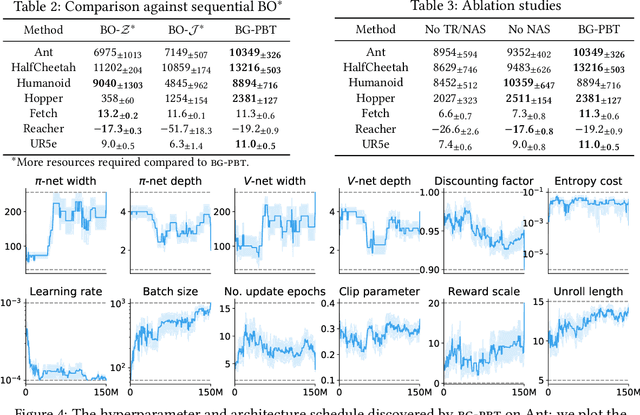
Reinforcement learning (RL) offers the potential for training generally capable agents that can interact autonomously in the real world. However, one key limitation is the brittleness of RL algorithms to core hyperparameters and network architecture choice. Furthermore, non-stationarities such as evolving training data and increased agent complexity mean that different hyperparameters and architectures may be optimal at different points of training. This motivates AutoRL, a class of methods seeking to automate these design choices. One prominent class of AutoRL methods is Population-Based Training (PBT), which have led to impressive performance in several large scale settings. In this paper, we introduce two new innovations in PBT-style methods. First, we employ trust-region based Bayesian Optimization, enabling full coverage of the high-dimensional mixed hyperparameter search space. Second, we show that using a generational approach, we can also learn both architectures and hyperparameters jointly on-the-fly in a single training run. Leveraging the new highly parallelizable Brax physics engine, we show that these innovations lead to large performance gains, significantly outperforming the tuned baseline while learning entire configurations on the fly. Code is available at https://github.com/xingchenwan/bgpbt.
Stabilizing Off-Policy Deep Reinforcement Learning from Pixels
Jul 03, 2022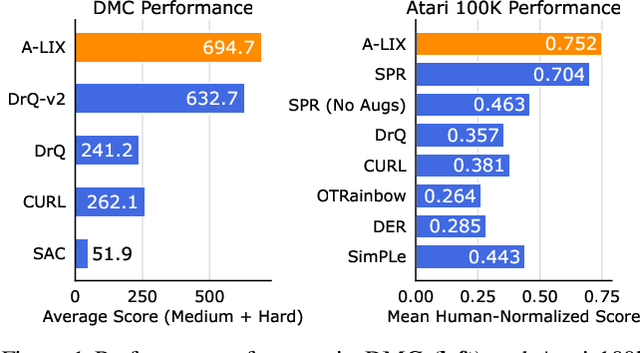

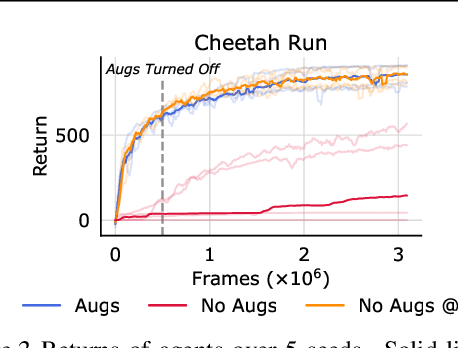
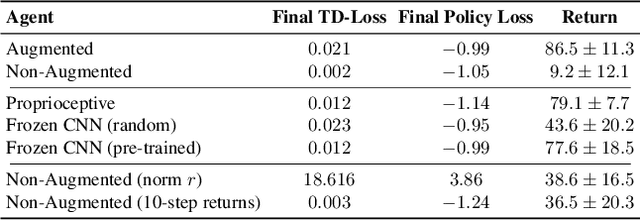
Off-policy reinforcement learning (RL) from pixel observations is notoriously unstable. As a result, many successful algorithms must combine different domain-specific practices and auxiliary losses to learn meaningful behaviors in complex environments. In this work, we provide novel analysis demonstrating that these instabilities arise from performing temporal-difference learning with a convolutional encoder and low-magnitude rewards. We show that this new visual deadly triad causes unstable training and premature convergence to degenerate solutions, a phenomenon we name catastrophic self-overfitting. Based on our analysis, we propose A-LIX, a method providing adaptive regularization to the encoder's gradients that explicitly prevents the occurrence of catastrophic self-overfitting using a dual objective. By applying A-LIX, we significantly outperform the prior state-of-the-art on the DeepMind Control and Atari 100k benchmarks without any data augmentation or auxiliary losses.
Challenges and Opportunities in Offline Reinforcement Learning from Visual Observations
Jun 09, 2022
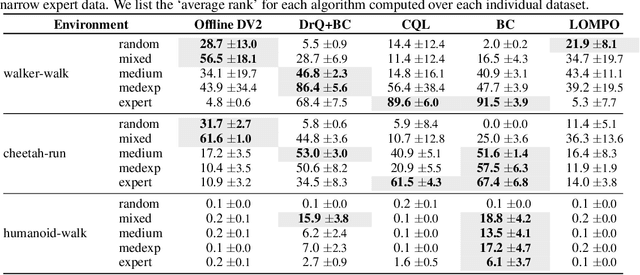
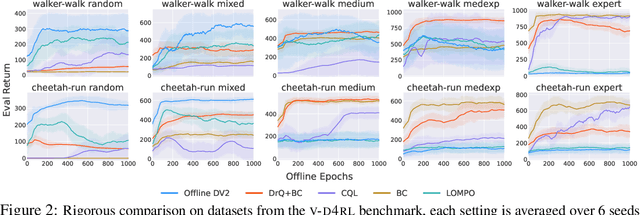

Offline reinforcement learning has shown great promise in leveraging large pre-collected datasets for policy learning, allowing agents to forgo often-expensive online data collection. However, to date, offline reinforcement learning from has been relatively under-explored, and there is a lack of understanding of where the remaining challenges lie. In this paper, we seek to establish simple baselines for continuous control in the visual domain. We show that simple modifications to two state-of-the-art vision-based online reinforcement learning algorithms, DreamerV2 and DrQ-v2, suffice to outperform prior work and establish a competitive baseline. We rigorously evaluate these algorithms on both existing offline datasets and a new testbed for offline reinforcement learning from visual observations that better represents the data distributions present in real-world offline reinforcement learning problems, and open-source our code and data to facilitate progress in this important domain. Finally, we present and analyze several key desiderata unique to offline RL from visual observations, including visual distractions and visually identifiable changes in dynamics.
Revisiting Design Choices in Model-Based Offline Reinforcement Learning
Oct 08, 2021
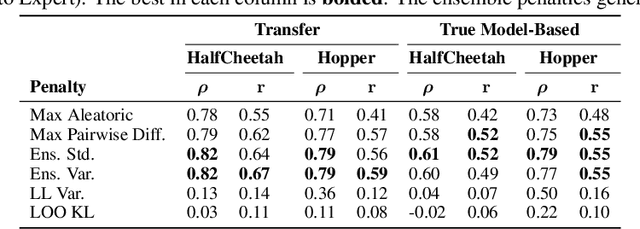
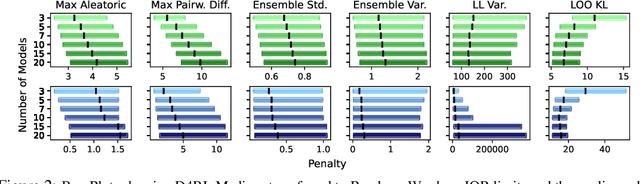
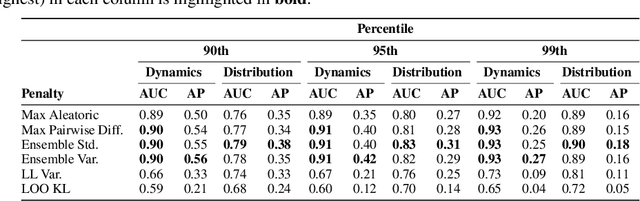
Offline reinforcement learning enables agents to leverage large pre-collected datasets of environment transitions to learn control policies, circumventing the need for potentially expensive or unsafe online data collection. Significant progress has been made recently in offline model-based reinforcement learning, approaches which leverage a learned dynamics model. This typically involves constructing a probabilistic model, and using the model uncertainty to penalize rewards where there is insufficient data, solving for a pessimistic MDP that lower bounds the true MDP. Existing methods, however, exhibit a breakdown between theory and practice, whereby pessimistic return ought to be bounded by the total variation distance of the model from the true dynamics, but is instead implemented through a penalty based on estimated model uncertainty. This has spawned a variety of uncertainty heuristics, with little to no comparison between differing approaches. In this paper, we compare these heuristics, and design novel protocols to investigate their interaction with other hyperparameters, such as the number of models, or imaginary rollout horizon. Using these insights, we show that selecting these key hyperparameters using Bayesian Optimization produces superior configurations that are vastly different to those currently used in existing hand-tuned state-of-the-art methods, and result in drastically stronger performance.
Augmented World Models Facilitate Zero-Shot Dynamics Generalization From a Single Offline Environment
Apr 12, 2021



Reinforcement learning from large-scale offline datasets provides us with the ability to learn policies without potentially unsafe or impractical exploration. Significant progress has been made in the past few years in dealing with the challenge of correcting for differing behavior between the data collection and learned policies. However, little attention has been paid to potentially changing dynamics when transferring a policy to the online setting, where performance can be up to 90% reduced for existing methods. In this paper we address this problem with Augmented World Models (AugWM). We augment a learned dynamics model with simple transformations that seek to capture potential changes in physical properties of the robot, leading to more robust policies. We not only train our policy in this new setting, but also provide it with the sampled augmentation as a context, allowing it to adapt to changes in the environment. At test time we learn the context in a self-supervised fashion by approximating the augmentation which corresponds to the new environment. We rigorously evaluate our approach on over 100 different changed dynamics settings, and show that this simple approach can significantly improve the zero-shot generalization of a recent state-of-the-art baseline, often achieving successful policies where the baseline fails.
OffCon$^3$: What is state of the art anyway?
Jan 27, 2021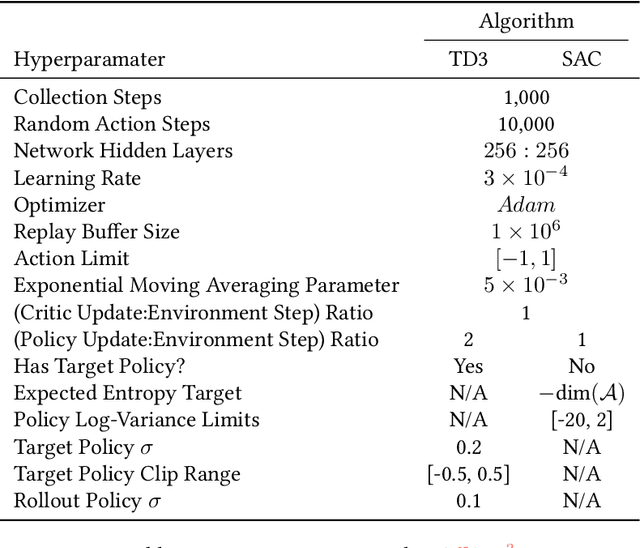

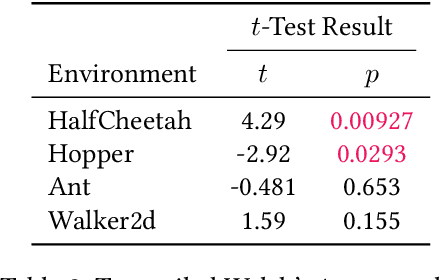
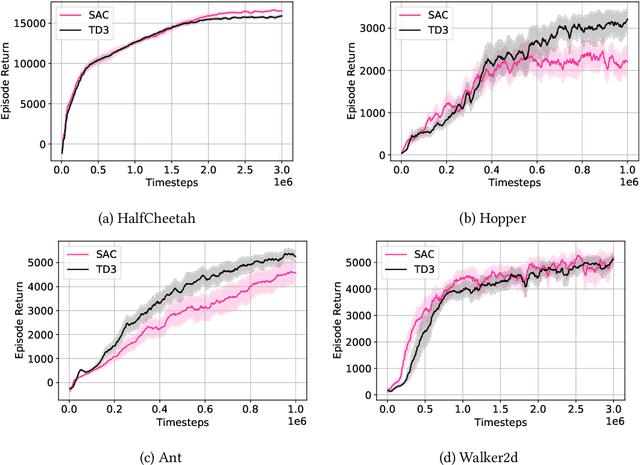
Two popular approaches to model-free continuous control tasks are SAC and TD3. At first glance these approaches seem rather different; SAC aims to solve the entropy-augmented MDP by minimising the KL-divergence between a stochastic proposal policy and a hypotheical energy-basd soft Q-function policy, whereas TD3 is derived from DPG, which uses a deterministic policy to perform policy gradient ascent along the value function. In reality, both approaches are remarkably similar, and belong to a family of approaches we call `Off-Policy Continuous Generalized Policy Iteration'. This illuminates their similar performance in most continuous control benchmarks, and indeed when hyperparameters are matched, their performance can be statistically indistinguishable. To further remove any difference due to implementation, we provide OffCon$^3$ (Off-Policy Continuous Control: Consolidated), a code base featuring state-of-the-art versions of both algorithms.
A Study on Efficiency in Continual Learning Inspired by Human Learning
Oct 28, 2020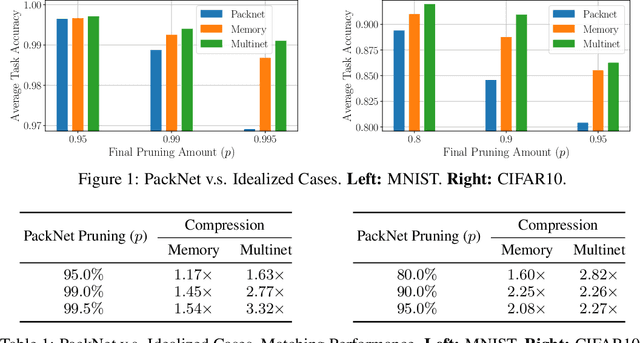

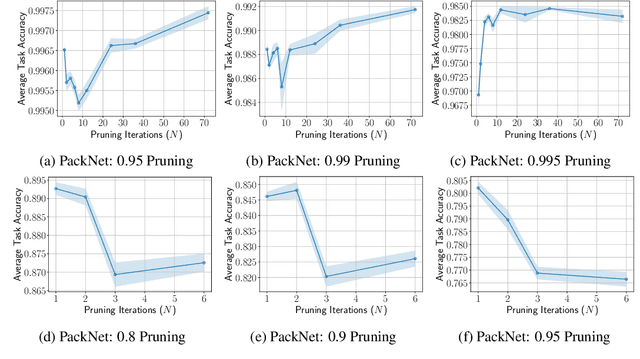
Humans are efficient continual learning systems; we continually learn new skills from birth with finite cells and resources. Our learning is highly optimized both in terms of capacity and time while not suffering from catastrophic forgetting. In this work we study the efficiency of continual learning systems, taking inspiration from human learning. In particular, inspired by the mechanisms of sleep, we evaluate popular pruning-based continual learning algorithms, using PackNet as a case study. First, we identify that weight freezing, which is used in continual learning without biological justification, can result in over $2\times$ as many weights being used for a given level of performance. Secondly, we note the similarity in human day and night time behaviors to the training and pruning phases respectively of PackNet. We study a setting where the pruning phase is given a time budget, and identify connections between iterative pruning and multiple sleep cycles in humans. We show there exists an optimal choice of iteration v.s. epochs given different tasks.