 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffCon$^3$: What is state of the art anyway?
Paper and Code
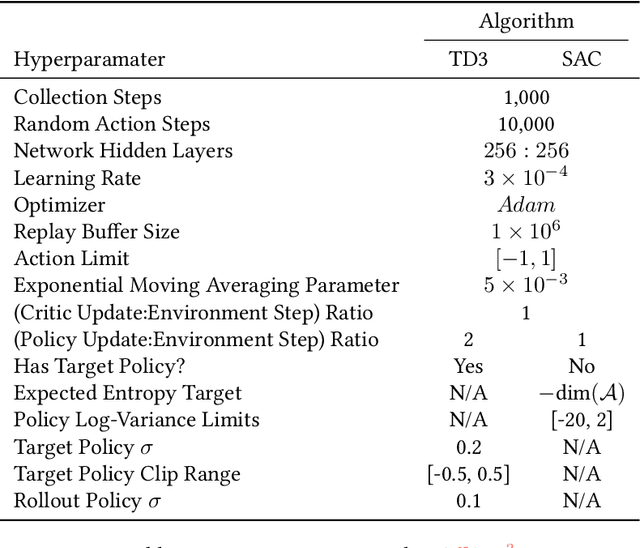

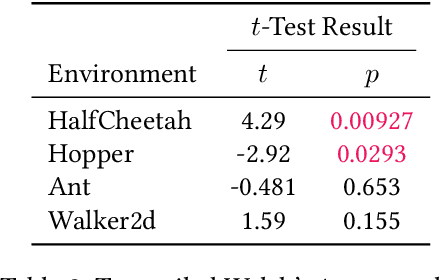
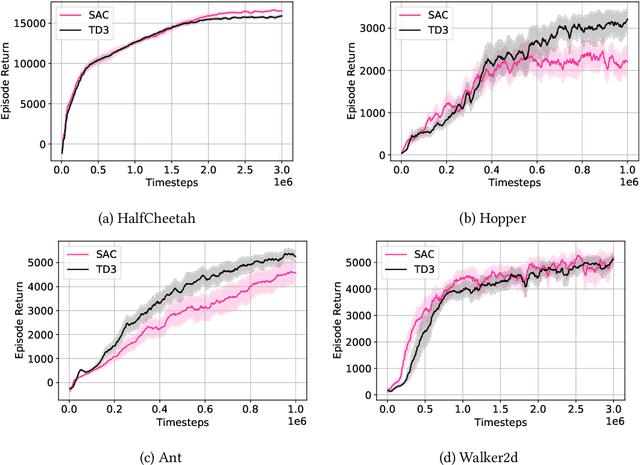
Two popular approaches to model-free continuous control tasks are SAC and TD3. At first glance these approaches seem rather different; SAC aims to solve the entropy-augmented MDP by minimising the KL-divergence between a stochastic proposal policy and a hypotheical energy-basd soft Q-function policy, whereas TD3 is derived from DPG, which uses a deterministic policy to perform policy gradient ascent along the value function. In reality, both approaches are remarkably similar, and belong to a family of approaches we call `Off-Policy Continuous Generalized Policy Iteration'. This illuminates their similar performance in most continuous control benchmarks, and indeed when hyperparameters are matched, their performance can be statistically indistinguishable. To further remove any difference due to implementation, we provide OffCon$^3$ (Off-Policy Continuous Control: Consolidated), a code base featuring state-of-the-art versions of both algorithms.