 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery
May 22, 2026Scientific research is being reshaped by AI systems that move beyond isolated assistance toward longer-horizon workflows spanning literature grounding, hypothesis generation, experimentation, validation, reporting, and revision. This shift marks a transition from task-level AI for science to workflow-level research automation. Yet current systems remain fragmented, differing in autonomy, domain scope, execution environment, validation mechanism, and human oversight, while still struggling with evidence preservation, reproducibility, weak-direction rejection, provenance tracking, cross-domain robustness, and accountable scientific closure. This survey examines these developments through AutoResearch, defined as the developmental spectrum of AI-powered scientific workflow automation. Within it, Vibe Research denotes the human-steered region of prompt-based assistance and human-verified execution, whereas emerging AI-led systems coordinate larger portions of the discovery loop without achieving robust autonomy. We analyze how research systems redistribute control, evidence, execution, validation, and accountability across workflows and organize the field around five workflow conditions: literature and research grounding; hypothesis formation and planning; experimentation and tool use; feedback, validation, and review; and reporting and knowledge communication. We further synthesize AI scientist systems, mixed-initiative co-research frameworks, benchmarks, domain deployments, and open-source infrastructures. Finally, we propose five evaluation dimensions--novelty, validity, impact, reliability, and provenance--and show that AutoResearch autonomy is domain-conditioned, being more credible in structured, executable, and rapidly verifiable settings but limited in embodied, delayed, heterogeneous, ethical, or institutionally accountable contexts.
SkillCraft: Can LLM Agents Learn to Use Tools Skillfully?
Feb 28, 2026Real-world tool-using agents operate over long-horizon workflows with recurring structure and diverse demands, where effective behavior requires not only invoking atomic tools but also abstracting, and reusing higher-level tool compositions. However, existing benchmarks mainly measure instance-level success under static tool sets, offering limited insight into agents' ability to acquire such reusable skills. We address this gap by introducing SkillCraft, a benchmark explicitly stress-test agent ability to form and reuse higher-level tool compositions, where we call Skills. SkillCraft features realistic, highly compositional tool-use scenarios with difficulty scaled along both quantitative and structural dimensions, designed to elicit skill abstraction and cross-task reuse. We further propose a lightweight evaluation protocol that enables agents to auto-compose atomic tools into executable Skills, cache and reuse them inside and across tasks, thereby improving efficiency while accumulating a persistent library of reusable skills. Evaluating state-of-the-art agents on SkillCraft, we observe substantial efficiency gains, with token usage reduced by up to 80% by skill saving and reuse. Moreover, success rate strongly correlates with tool composition ability at test time, underscoring compositional skill acquisition as a core capability.
Foundation Model Self-Play: Open-Ended Strategy Innovation via Foundation Models
Jul 09, 2025Multi-agent interactions have long fueled innovation, from natural predator-prey dynamics to the space race. Self-play (SP) algorithms try to harness these dynamics by pitting agents against ever-improving opponents, thereby creating an implicit curriculum toward learning high-quality solutions. However, SP often fails to produce diverse solutions and can get stuck in locally optimal behaviors. We introduce Foundation-Model Self-Play (FMSP), a new direction that leverages the code-generation capabilities and vast knowledge of foundation models (FMs) to overcome these challenges by leaping across local optima in policy space. We propose a family of approaches: (1) \textbf{Vanilla Foundation-Model Self-Play (vFMSP)} continually refines agent policies via competitive self-play; (2) \textbf{Novelty-Search Self-Play (NSSP)} builds a diverse population of strategies, ignoring performance; and (3) the most promising variant, \textbf{Quality-Diveristy Self-Play (QDSP)}, creates a diverse set of high-quality policies by combining the diversity of NSSP and refinement of vFMSP. We evaluate FMSPs in Car Tag, a continuous-control pursuer-evader setting, and in Gandalf, a simple AI safety simulation in which an attacker tries to jailbreak an LLM's defenses. In Car Tag, FMSPs explore a wide variety of reinforcement learning, tree search, and heuristic-based methods, to name just a few. In terms of discovered policy quality, \ouralgo and vFMSP surpass strong human-designed strategies. In Gandalf, FMSPs can successfully automatically red-team an LLM, breaking through and jailbreaking six different, progressively stronger levels of defense. Furthermore, FMSPs can automatically proceed to patch the discovered vulnerabilities. Overall, FMSPs represent a promising new research frontier of improving self-play with foundation models, opening fresh paths toward more creative and open-ended strategy discovery
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
May 29, 2025Today's AI systems have human-designed, fixed architectures and cannot autonomously and continuously improve themselves. The advance of AI could itself be automated. If done safely, that would accelerate AI development and allow us to reap its benefits much sooner. Meta-learning can automate the discovery of novel algorithms, but is limited by first-order improvements and the human design of a suitable search space. The G\"odel machine proposed a theoretical alternative: a self-improving AI that repeatedly modifies itself in a provably beneficial manner. Unfortunately, proving that most changes are net beneficial is impossible in practice. We introduce the Darwin G\"odel Machine (DGM), a self-improving system that iteratively modifies its own code (thereby also improving its ability to modify its own codebase) and empirically validates each change using coding benchmarks. Inspired by Darwinian evolution and open-endedness research, the DGM maintains an archive of generated coding agents. It grows the archive by sampling an agent from it and using a foundation model to create a new, interesting, version of the sampled agent. This open-ended exploration forms a growing tree of diverse, high-quality agents and allows the parallel exploration of many different paths through the search space. Empirically, the DGM automatically improves its coding capabilities (e.g., better code editing tools, long-context window management, peer-review mechanisms), increasing performance on SWE-bench from 20.0% to 50.0%, and on Polyglot from 14.2% to 30.7%. Furthermore, the DGM significantly outperforms baselines without self-improvement or open-ended exploration. All experiments were done with safety precautions (e.g., sandboxing, human oversight). The DGM is a significant step toward self-improving AI, capable of gathering its own stepping stones along paths that unfold into endless innovation.
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Apr 10, 2025


AI is increasingly playing a pivotal role in transforming how scientific discoveries are made. We introduce The AI Scientist-v2, an end-to-end agentic system capable of producing the first entirely AI generated peer-review-accepted workshop paper. This system iteratively formulates scientific hypotheses, designs and executes experiments, analyzes and visualizes data, and autonomously authors scientific manuscripts. Compared to its predecessor (v1, Lu et al., 2024 arXiv:2408.06292), The AI Scientist-v2 eliminates the reliance on human-authored code templates, generalizes effectively across diverse machine learning domains, and leverages a novel progressive agentic tree-search methodology managed by a dedicated experiment manager agent. Additionally, we enhance the AI reviewer component by integrating a Vision-Language Model (VLM) feedback loop for iterative refinement of content and aesthetics of the figures. We evaluated The AI Scientist-v2 by submitting three fully autonomous manuscripts to a peer-reviewed ICLR workshop. Notably, one manuscript achieved high enough scores to exceed the average human acceptance threshold, marking the first instance of a fully AI-generated paper successfully navigating a peer review. This accomplishment highlights the growing capability of AI in conducting all aspects of scientific research. We anticipate that further advancements in autonomous scientific discovery technologies will profoundly impact human knowledge generation, enabling unprecedented scalability in research productivity and significantly accelerating scientific breakthroughs, greatly benefiting society at large. We have open-sourced the code at https://github.com/SakanaAI/AI-Scientist-v2 to foster the future development of this transformative technology. We also discuss the role of AI in science, including AI safety.
Automated Capability Discovery via Model Self-Exploration
Feb 12, 2025Foundation models have become general-purpose assistants, exhibiting diverse capabilities across numerous domains through training on web-scale data. It remains challenging to precisely characterize even a fraction of the full spectrum of capabilities and potential risks in any new model. Existing evaluation approaches often require significant human effort, and it is taking increasing effort to design ever harder challenges for more capable models. We introduce Automated Capability Discovery (ACD), a framework that designates one foundation model as a scientist to systematically propose open-ended tasks probing the abilities of a subject model (potentially itself). By combining frontier models with ideas from the field of open-endedness, ACD automatically and systematically uncovers both surprising capabilities and failures in the subject model. We demonstrate ACD across a range of foundation models (including the GPT, Claude, and Llama series), showing that it automatically reveals thousands of capabilities that would be challenging for any single team to uncover. We further validate our method's automated scoring with extensive human surveys, observing high agreement between model-generated and human evaluations. By leveraging foundation models' ability to both create tasks and self-evaluate, ACD is a significant step toward scalable, automated evaluation of novel AI systems. All code and evaluation logs are open-sourced at https://github.com/conglu1997/ACD.
IGDrivSim: A Benchmark for the Imitation Gap in Autonomous Driving
Nov 07, 2024



Developing autonomous vehicles that can navigate complex environments with human-level safety and efficiency is a central goal in self-driving research. A common approach to achieving this is imitation learning, where agents are trained to mimic human expert demonstrations collected from real-world driving scenarios. However, discrepancies between human perception and the self-driving car's sensors can introduce an \textit{imitation gap}, leading to imitation learning failures. In this work, we introduce \textbf{IGDrivSim}, a benchmark built on top of the Waymax simulator, designed to investigate the effects of the imitation gap in learning autonomous driving policy from human expert demonstrations. Our experiments show that this perception gap between human experts and self-driving agents can hinder the learning of safe and effective driving behaviors. We further show that combining imitation with reinforcement learning, using a simple penalty reward for prohibited behaviors, effectively mitigates these failures. Our code is open-sourced at: https://github.com/clemgris/IGDrivSim.git.
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Aug 15, 2024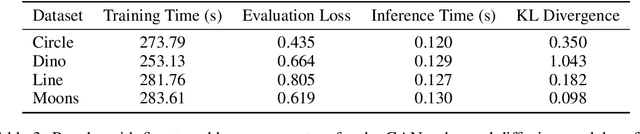


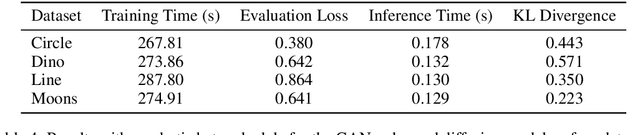
One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been used as aides to human scientists, e.g. for brainstorming ideas, writing code, or prediction tasks, they still conduct only a small part of the scientific process. This paper presents the first comprehensive framework for fully automatic scientific discovery, enabling frontier large language models to perform research independently and communicate their findings. We introduce The AI Scientist, which generates novel research ideas, writes code, executes experiments, visualizes results, describes its findings by writing a full scientific paper, and then runs a simulated review process for evaluation. In principle, this process can be repeated to iteratively develop ideas in an open-ended fashion, acting like the human scientific community. We demonstrate its versatility by applying it to three distinct subfields of machine learning: diffusion modeling, transformer-based language modeling, and learning dynamics. Each idea is implemented and developed into a full paper at a cost of less than $15 per paper. To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores. The AI Scientist can produce papers that exceed the acceptance threshold at a top machine learning conference as judged by our automated reviewer. This approach signifies the beginning of a new era in scientific discovery in machine learning: bringing the transformative benefits of AI agents to the entire research process of AI itself, and taking us closer to a world where endless affordable creativity and innovation can be unleashed on the world's most challenging problems. Our code is open-sourced at https://github.com/SakanaAI/AI-Scientist
Automated Design of Agentic Systems
Aug 15, 2024



Researchers are investing substantial effort in developing powerful general-purpose agents, wherein Foundation Models are used as modules within agentic systems (e.g. Chain-of-Thought, Self-Reflection, Toolformer). However, the history of machine learning teaches us that hand-designed solutions are eventually replaced by learned solutions. We formulate a new research area, Automated Design of Agentic Systems (ADAS), which aims to automatically create powerful agentic system designs, including inventing novel building blocks and/or combining them in new ways. We further demonstrate that there is an unexplored yet promising approach within ADAS where agents can be defined in code and new agents can be automatically discovered by a meta agent programming ever better ones in code. Given that programming languages are Turing Complete, this approach theoretically enables the learning of any possible agentic system: including novel prompts, tool use, control flows, and combinations thereof. We present a simple yet effective algorithm named Meta Agent Search to demonstrate this idea, where a meta agent iteratively programs interesting new agents based on an ever-growing archive of previous discoveries. Through extensive experiments across multiple domains including coding, science, and math, we show that our algorithm can progressively invent agents with novel designs that greatly outperform state-of-the-art hand-designed agents. Importantly, we consistently observe the surprising result that agents invented by Meta Agent Search maintain superior performance even when transferred across domains and models, demonstrating their robustness and generality. Provided we develop it safely, our work illustrates the potential of an exciting new research direction toward automatically designing ever-more powerful agentic systems to benefit humanity.
A Bayesian Solution To The Imitation Gap
Jun 29, 2024



In many real-world settings, an agent must learn to act in environments where no reward signal can be specified, but a set of expert demonstrations is available. Imitation learning (IL) is a popular framework for learning policies from such demonstrations. However, in some cases, differences in observability between the expert and the agent can give rise to an imitation gap such that the expert's policy is not optimal for the agent and a naive application of IL can fail catastrophically. In particular, if the expert observes the Markov state and the agent does not, then the expert will not demonstrate the information-gathering behavior needed by the agent but not the expert. In this paper, we propose a Bayesian solution to the Imitation Gap (BIG), first using the expert demonstrations, together with a prior specifying the cost of exploratory behavior that is not demonstrated, to infer a posterior over rewards with Bayesian inverse reinforcement learning (IRL). BIG then uses the reward posterior to learn a Bayes-optimal policy. Our experiments show that BIG, unlike IL, allows the agent to explore at test time when presented with an imitation gap, whilst still learning to behave optimally using expert demonstrations when no such gap exists.