 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Continually Learn via Meta-learning Agentic Memory Designs
Feb 08, 2026The statelessness of foundation models bottlenecks agentic systems' ability to continually learn, a core capability for long-horizon reasoning and adaptation. To address this limitation, agentic systems commonly incorporate memory modules to retain and reuse past experience, aiming for continual learning during test time. However, most existing memory designs are human-crafted and fixed, which limits their ability to adapt to the diversity and non-stationarity of real-world tasks. In this paper, we introduce ALMA (Automated meta-Learning of Memory designs for Agentic systems), a framework that meta-learns memory designs to replace hand-engineered memory designs, therefore minimizing human effort and enabling agentic systems to be continual learners across diverse domains. Our approach employs a Meta Agent that searches over memory designs expressed as executable code in an open-ended manner, theoretically allowing the discovery of arbitrary memory designs, including database schemas as well as their retrieval and update mechanisms. Extensive experiments across four sequential decision-making domains demonstrate that the learned memory designs enable more effective and efficient learning from experience than state-of-the-art human-crafted memory designs on all benchmarks. When developed and deployed safely, ALMA represents a step toward self-improving AI systems that learn to be adaptive, continual learners.
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
May 29, 2025Today's AI systems have human-designed, fixed architectures and cannot autonomously and continuously improve themselves. The advance of AI could itself be automated. If done safely, that would accelerate AI development and allow us to reap its benefits much sooner. Meta-learning can automate the discovery of novel algorithms, but is limited by first-order improvements and the human design of a suitable search space. The G\"odel machine proposed a theoretical alternative: a self-improving AI that repeatedly modifies itself in a provably beneficial manner. Unfortunately, proving that most changes are net beneficial is impossible in practice. We introduce the Darwin G\"odel Machine (DGM), a self-improving system that iteratively modifies its own code (thereby also improving its ability to modify its own codebase) and empirically validates each change using coding benchmarks. Inspired by Darwinian evolution and open-endedness research, the DGM maintains an archive of generated coding agents. It grows the archive by sampling an agent from it and using a foundation model to create a new, interesting, version of the sampled agent. This open-ended exploration forms a growing tree of diverse, high-quality agents and allows the parallel exploration of many different paths through the search space. Empirically, the DGM automatically improves its coding capabilities (e.g., better code editing tools, long-context window management, peer-review mechanisms), increasing performance on SWE-bench from 20.0% to 50.0%, and on Polyglot from 14.2% to 30.7%. Furthermore, the DGM significantly outperforms baselines without self-improvement or open-ended exploration. All experiments were done with safety precautions (e.g., sandboxing, human oversight). The DGM is a significant step toward self-improving AI, capable of gathering its own stepping stones along paths that unfold into endless innovation.
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Apr 10, 2025


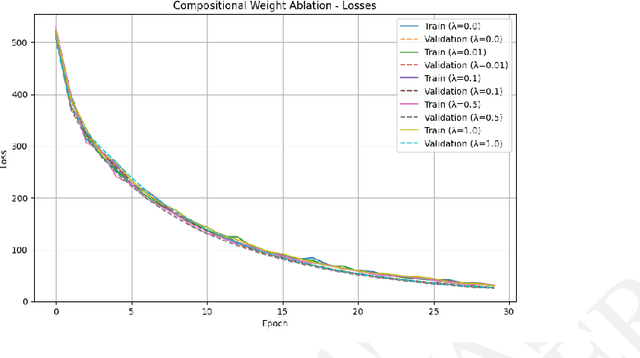
AI is increasingly playing a pivotal role in transforming how scientific discoveries are made. We introduce The AI Scientist-v2, an end-to-end agentic system capable of producing the first entirely AI generated peer-review-accepted workshop paper. This system iteratively formulates scientific hypotheses, designs and executes experiments, analyzes and visualizes data, and autonomously authors scientific manuscripts. Compared to its predecessor (v1, Lu et al., 2024 arXiv:2408.06292), The AI Scientist-v2 eliminates the reliance on human-authored code templates, generalizes effectively across diverse machine learning domains, and leverages a novel progressive agentic tree-search methodology managed by a dedicated experiment manager agent. Additionally, we enhance the AI reviewer component by integrating a Vision-Language Model (VLM) feedback loop for iterative refinement of content and aesthetics of the figures. We evaluated The AI Scientist-v2 by submitting three fully autonomous manuscripts to a peer-reviewed ICLR workshop. Notably, one manuscript achieved high enough scores to exceed the average human acceptance threshold, marking the first instance of a fully AI-generated paper successfully navigating a peer review. This accomplishment highlights the growing capability of AI in conducting all aspects of scientific research. We anticipate that further advancements in autonomous scientific discovery technologies will profoundly impact human knowledge generation, enabling unprecedented scalability in research productivity and significantly accelerating scientific breakthroughs, greatly benefiting society at large. We have open-sourced the code at https://github.com/SakanaAI/AI-Scientist-v2 to foster the future development of this transformative technology. We also discuss the role of AI in science, including AI safety.
Automated Capability Discovery via Model Self-Exploration
Feb 12, 2025Foundation models have become general-purpose assistants, exhibiting diverse capabilities across numerous domains through training on web-scale data. It remains challenging to precisely characterize even a fraction of the full spectrum of capabilities and potential risks in any new model. Existing evaluation approaches often require significant human effort, and it is taking increasing effort to design ever harder challenges for more capable models. We introduce Automated Capability Discovery (ACD), a framework that designates one foundation model as a scientist to systematically propose open-ended tasks probing the abilities of a subject model (potentially itself). By combining frontier models with ideas from the field of open-endedness, ACD automatically and systematically uncovers both surprising capabilities and failures in the subject model. We demonstrate ACD across a range of foundation models (including the GPT, Claude, and Llama series), showing that it automatically reveals thousands of capabilities that would be challenging for any single team to uncover. We further validate our method's automated scoring with extensive human surveys, observing high agreement between model-generated and human evaluations. By leveraging foundation models' ability to both create tasks and self-evaluate, ACD is a significant step toward scalable, automated evaluation of novel AI systems. All code and evaluation logs are open-sourced at https://github.com/conglu1997/ACD.
Automated Design of Agentic Systems
Aug 15, 2024



Researchers are investing substantial effort in developing powerful general-purpose agents, wherein Foundation Models are used as modules within agentic systems (e.g. Chain-of-Thought, Self-Reflection, Toolformer). However, the history of machine learning teaches us that hand-designed solutions are eventually replaced by learned solutions. We formulate a new research area, Automated Design of Agentic Systems (ADAS), which aims to automatically create powerful agentic system designs, including inventing novel building blocks and/or combining them in new ways. We further demonstrate that there is an unexplored yet promising approach within ADAS where agents can be defined in code and new agents can be automatically discovered by a meta agent programming ever better ones in code. Given that programming languages are Turing Complete, this approach theoretically enables the learning of any possible agentic system: including novel prompts, tool use, control flows, and combinations thereof. We present a simple yet effective algorithm named Meta Agent Search to demonstrate this idea, where a meta agent iteratively programs interesting new agents based on an ever-growing archive of previous discoveries. Through extensive experiments across multiple domains including coding, science, and math, we show that our algorithm can progressively invent agents with novel designs that greatly outperform state-of-the-art hand-designed agents. Importantly, we consistently observe the surprising result that agents invented by Meta Agent Search maintain superior performance even when transferred across domains and models, demonstrating their robustness and generality. Provided we develop it safely, our work illustrates the potential of an exciting new research direction toward automatically designing ever-more powerful agentic systems to benefit humanity.
Intelligent Go-Explore: Standing on the Shoulders of Giant Foundation Models
May 30, 2024Go-Explore is a powerful family of algorithms designed to solve hard-exploration problems, built on the principle of archiving discovered states, and iteratively returning to and exploring from the most promising states. This approach has led to superhuman performance across a wide variety of challenging problems including Atari games and robotic control, but requires manually designing heuristics to guide exploration, which is time-consuming and infeasible in general. To resolve this, we propose Intelligent Go-Explore (IGE) which greatly extends the scope of the original Go-Explore by replacing these heuristics with the intelligence and internalized human notions of interestingness captured by giant foundation models (FMs). This provides IGE with a human-like ability to instinctively identify how interesting or promising any new state is (e.g. discovering new objects, locations, or behaviors), even in complex environments where heuristics are hard to define. Moreover, IGE offers the exciting and previously impossible opportunity to recognize and capitalize on serendipitous discoveries that cannot be predicted ahead of time. We evaluate IGE on a range of language-based tasks that require search and exploration. In Game of 24, a multistep mathematical reasoning problem, IGE reaches 100% success rate 70.8% faster than the best classic graph search baseline. Next, in BabyAI-Text, a challenging partially observable gridworld, IGE exceeds the previous SOTA with orders of magnitude fewer online samples. Finally, in TextWorld, we show the unique ability of IGE to succeed in settings requiring long-horizon exploration where prior SOTA FM agents like Reflexion completely fail. Overall, IGE combines the tremendous strengths of FMs and the powerful Go-Explore algorithm, opening up a new frontier of research into creating more generally capable agents with impressive exploration capabilities.
Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
Jun 01, 2023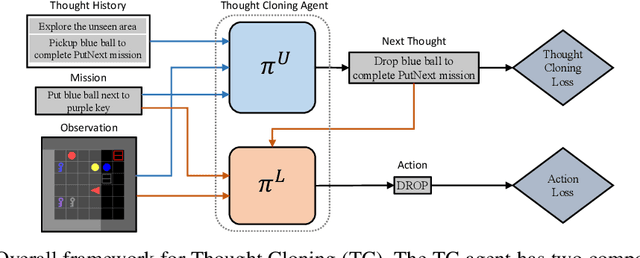
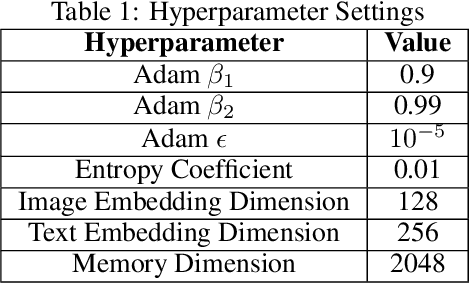
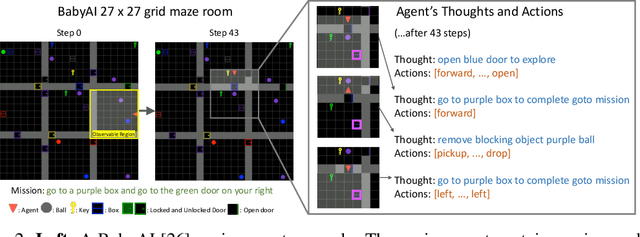
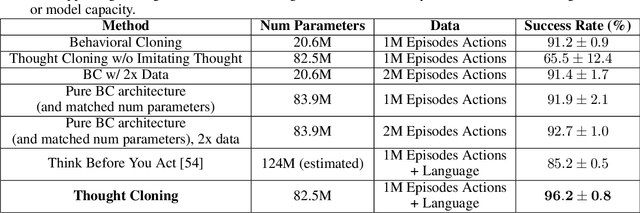
Language is often considered a key aspect of human thinking, providing us with exceptional abilities to generalize, explore, plan, replan, and adapt to new situations. However, Reinforcement Learning (RL) agents are far from human-level performance in any of these abilities. We hypothesize one reason for such cognitive deficiencies is that they lack the benefits of thinking in language and that we can improve AI agents by training them to think like humans do. We introduce a novel Imitation Learning framework, Thought Cloning, where the idea is to not just clone the behaviors of human demonstrators, but also the thoughts humans have as they perform these behaviors. While we expect Thought Cloning to truly shine at scale on internet-sized datasets of humans thinking out loud while acting (e.g. online videos with transcripts), here we conduct experiments in a domain where the thinking and action data are synthetically generated. Results reveal that Thought Cloning learns much faster than Behavioral Cloning and its performance advantage grows the further out of distribution test tasks are, highlighting its ability to better handle novel situations. Thought Cloning also provides important benefits for AI Safety and Interpretability, and makes it easier to debug and improve AI. Because we can observe the agent's thoughts, we can (1) more easily diagnose why things are going wrong, making it easier to fix the problem, (2) steer the agent by correcting its thinking, or (3) prevent it from doing unsafe things it plans to do. Overall, by training agents how to think as well as behave, Thought Cloning creates safer, more powerful agents.
Accelerating Multi-Objective Neural Architecture Search by Random-Weight Evaluation
Oct 08, 2021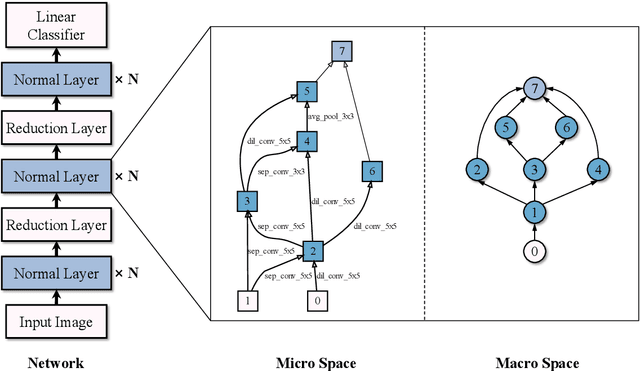
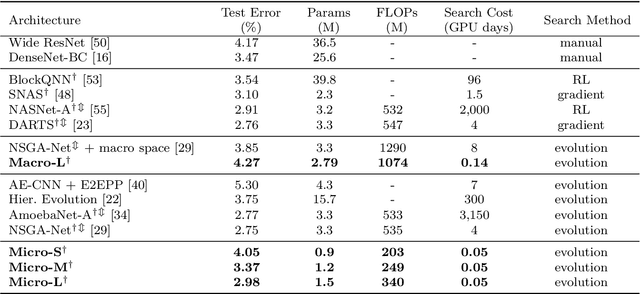
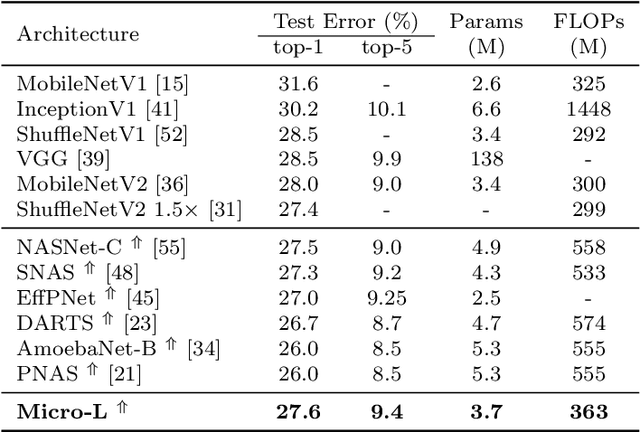
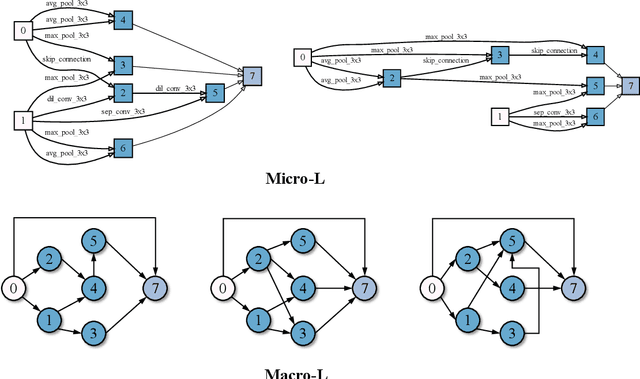
For the goal of automated design of high-performance deep convolutional neural networks (CNNs), Neural Architecture Search (NAS) methodology is becoming increasingly important for both academia and industries.Due to the costly stochastic gradient descent (SGD) training of CNNs for performance evaluation, most existing NAS methods are computationally expensive for real-world deployments. To address this issue, we first introduce a new performance estimation metric, named Random-Weight Evaluation (RWE) to quantify the quality of CNNs in a cost-efficient manner. Instead of fully training the entire CNN, the RWE only trains its last layer and leaves the remainders with randomly initialized weights, which results in a single network evaluation in seconds.Second, a complexity metric is adopted for multi-objective NAS to balance the model size and performance. Overall, our proposed method obtains a set of efficient models with state-of-the-art performance in two real-world search spaces. Then the results obtained on the CIFAR-10 dataset are transferred to the ImageNet dataset to validate the practicality of the proposed algorithm. Moreover, ablation studies on NAS-Bench-301 datasets reveal the effectiveness of the proposed RWE in estimating the performance compared with existing methods.
Multi-objective Neural Architecture Search with Almost No Training
Nov 27, 2020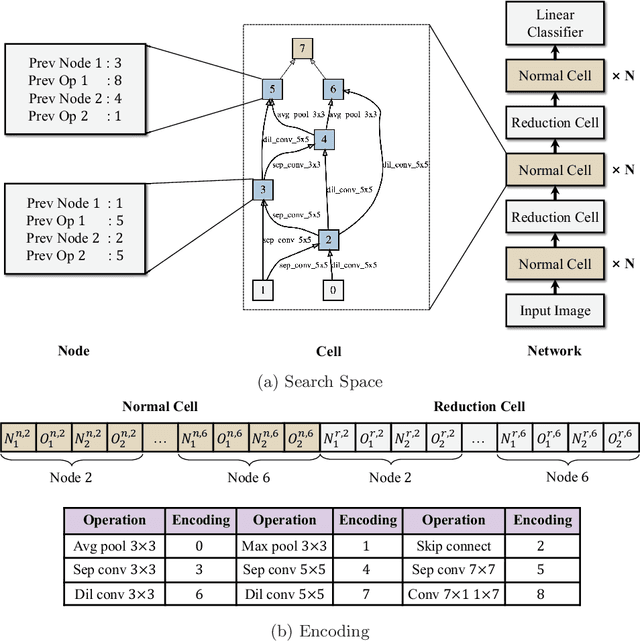
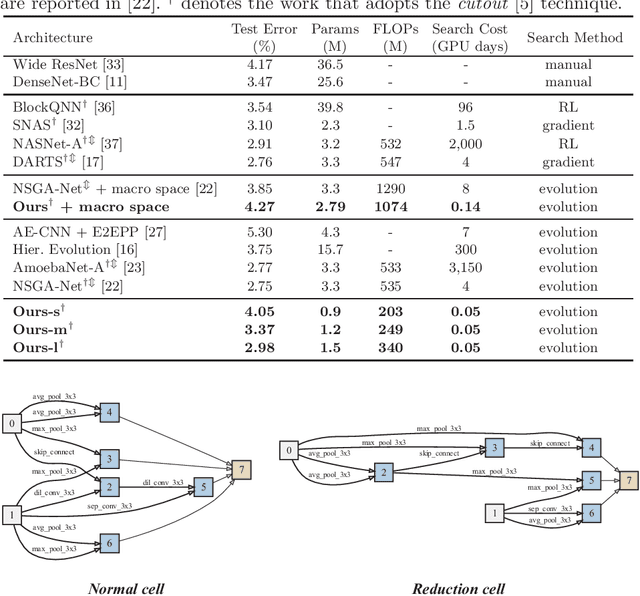
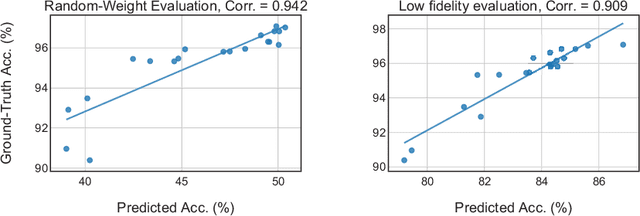

In the recent past, neural architecture search (NAS) has attracted increasing attention from both academia and industries. Despite the steady stream of impressive empirical results, most existing NAS algorithms are computationally prohibitive to execute due to the costly iterations of stochastic gradient descent (SGD) training. In this work, we propose an effective alternative, dubbed Random-Weight Evaluation (RWE), to rapidly estimate the performance of network architectures. By just training the last linear classification layer, RWE reduces the computational cost of evaluating an architecture from hours to seconds. When integrated within an evolutionary multi-objective algorithm, RWE obtains a set of efficient architectures with state-of-the-art performance on CIFAR-10 with less than two hours' searching on a single GPU card. Ablation studies on rank-order correlations and transfer learning experiments to ImageNet have further validated the effectiveness of RWE.