 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Time-series Model for Universal Knowledge Representation of Multivariate Time-Series data
Feb 05, 2025



Universal knowledge representation is a central problem for multivariate time series(MTS) foundation models and yet remains open. This paper investigates this problem from the first principle and it makes four folds of contributions. First, a new empirical finding is revealed: time series with different time granularities (or corresponding frequency resolutions) exhibit distinct joint distributions in the frequency domain. This implies a crucial aspect of learning universal knowledge, one that has been overlooked by previous studies. Second, a novel Fourier knowledge attention mechanism is proposed to enable learning time granularity-aware representations from both the temporal and frequency domains. Third, an autoregressive blank infilling pre-training framework is incorporated to time series analysis for the first time, leading to a generative tasks agnostic pre-training strategy. To this end, we develop the General Time-series Model (GTM), a unified MTS foundation model that addresses the limitation of contemporary time series models, which often require token, pre-training, or model-level customizations for downstream tasks adaption. Fourth, extensive experiments show that GTM outperforms state-of-the-art (SOTA) methods across all generative tasks, including long-term forecasting, anomaly detection, and imputation.
Classification of Power Quality Disturbances Using Resnet with Channel Attention Mechanism
Jul 02, 2024
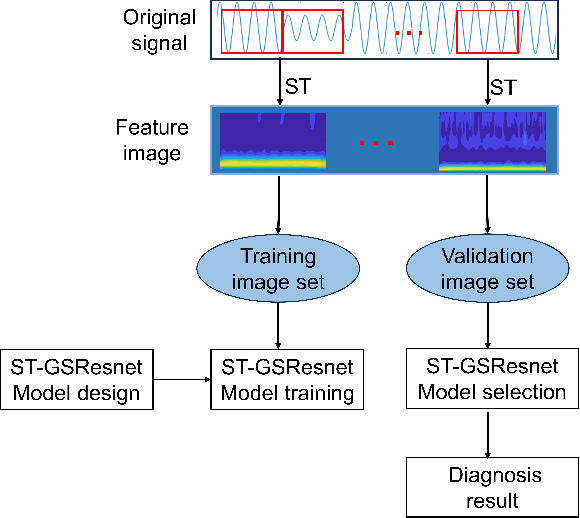
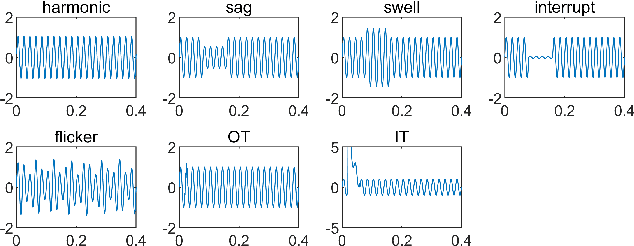
The detection and classification of power quality disturbances (PQDs) carries significant importance for power systems. In response to this imperative, numerous intelligent diagnostic methods have been developed. However, existing identification methods usually concentrate on single-type signals or on complex signals with two types, rendering them susceptible to noisy labels and environmental effects. This study proposes a novel method for the classification of PQDs, termed ST-GSResNet, which utilizes the S-Transform and an improved residual neural network (ResNet) with a channel attention mechanism. The ST-GSResNet approach initially uses the S-Transform to transform a time-series signal into a 2D time-frequency image for feature enhancement. Then, an improved ResNet model is introduced, which employs grouped convolution instead of the traditional convolution operation. This improvement aims to facilitate learning with a block-diagonal structured sparsity on the channel dimension, the highly-correlated filters are learned in a more structured way in the networks with filter groups. By reducing the number of parameters in the network in this significant manner, the model becomes less prone to overfitting. Furthermore, the SE module concentrates on primary components, which enhances the model's robustness in recognition and immunity to noise. Experimental results demonstrate that, compared to existing deep learning models, our approach has advantages in computational efficiency and classification accuracy.
HigeNet: A Highly Efficient Modeling for Long Sequence Time Series Prediction in AIOps
Nov 13, 2022



Modern IT system operation demands the integration of system software and hardware metrics. As a result, it generates a massive amount of data, which can be potentially used to make data-driven operational decisions. In the basic form, the decision model needs to monitor a large set of machine data, such as CPU utilization, allocated memory, disk and network latency, and predicts the system metrics to prevent performance degradation. Nevertheless, building an effective prediction model in this scenario is rather challenging as the model has to accurately capture the long-range coupling dependency in the Multivariate Time-Series (MTS). Moreover, this model needs to have low computational complexity and can scale efficiently to the dimension of data available. In this paper, we propose a highly efficient model named HigeNet to predict the long-time sequence time series. We have deployed the HigeNet on production in the D-matrix platform. We also provide offline evaluations on several publicly available datasets as well as one online dataset to demonstrate the model's efficacy. The extensive experiments show that training time, resource usage and accuracy of the model are found to be significantly better than five state-of-the-art competing models.
Accelerating Multi-Objective Neural Architecture Search by Random-Weight Evaluation
Oct 08, 2021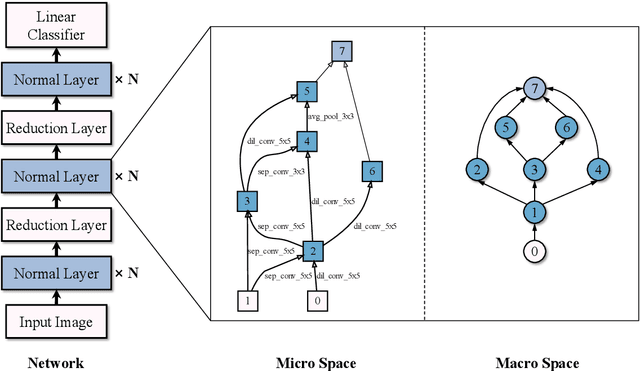
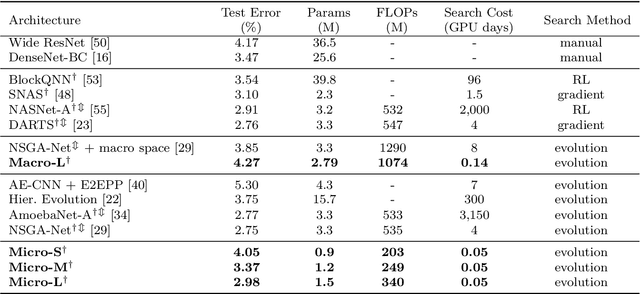
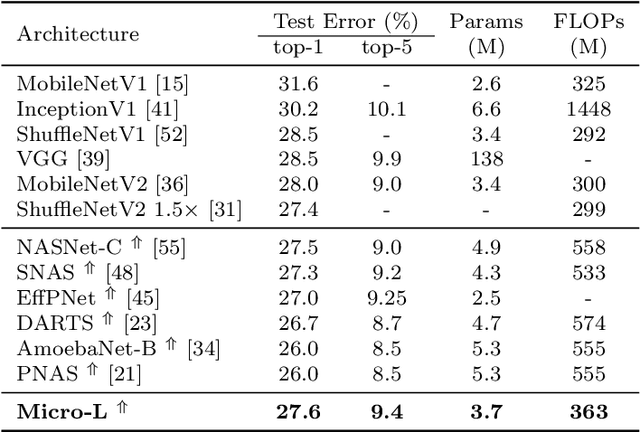
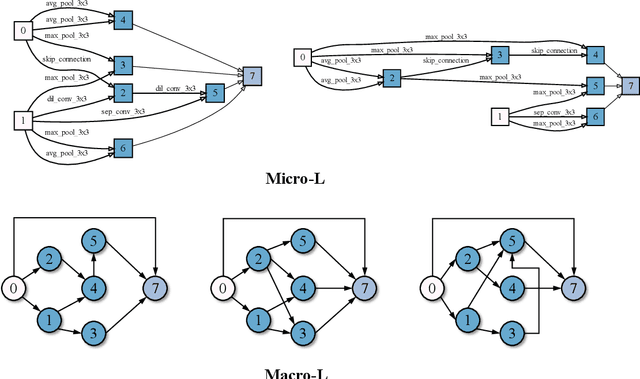
For the goal of automated design of high-performance deep convolutional neural networks (CNNs), Neural Architecture Search (NAS) methodology is becoming increasingly important for both academia and industries.Due to the costly stochastic gradient descent (SGD) training of CNNs for performance evaluation, most existing NAS methods are computationally expensive for real-world deployments. To address this issue, we first introduce a new performance estimation metric, named Random-Weight Evaluation (RWE) to quantify the quality of CNNs in a cost-efficient manner. Instead of fully training the entire CNN, the RWE only trains its last layer and leaves the remainders with randomly initialized weights, which results in a single network evaluation in seconds.Second, a complexity metric is adopted for multi-objective NAS to balance the model size and performance. Overall, our proposed method obtains a set of efficient models with state-of-the-art performance in two real-world search spaces. Then the results obtained on the CIFAR-10 dataset are transferred to the ImageNet dataset to validate the practicality of the proposed algorithm. Moreover, ablation studies on NAS-Bench-301 datasets reveal the effectiveness of the proposed RWE in estimating the performance compared with existing methods.
FaPN: Feature-aligned Pyramid Network for Dense Image Prediction
Aug 17, 2021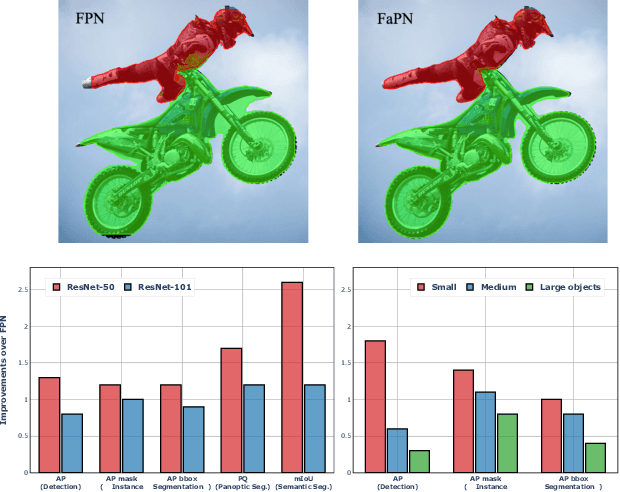
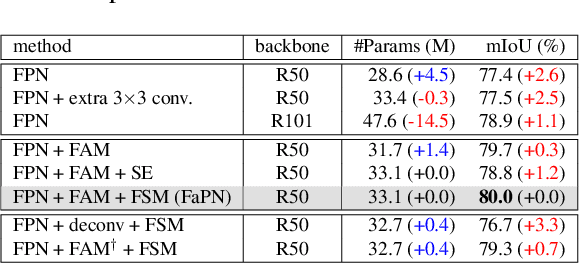
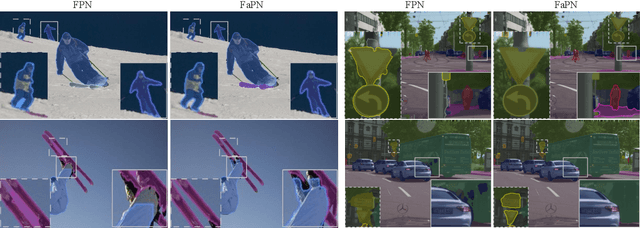
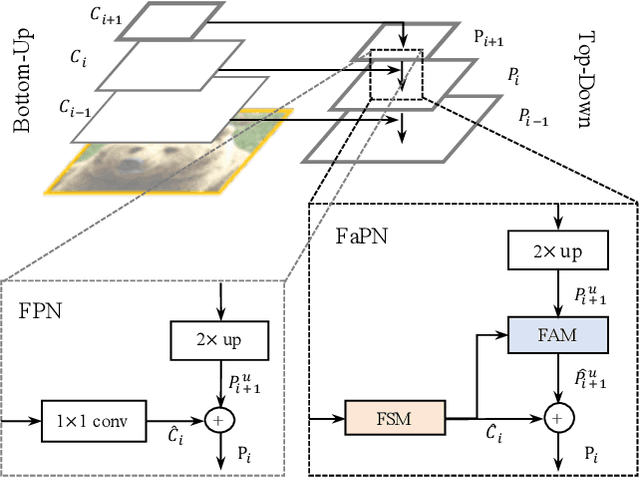
Recent advancements in deep neural networks have made remarkable leap-forwards in dense image prediction. However, the issue of feature alignment remains as neglected by most existing approaches for simplicity. Direct pixel addition between upsampled and local features leads to feature maps with misaligned contexts that, in turn, translate to mis-classifications in prediction, especially on object boundaries. In this paper, we propose a feature alignment module that learns transformation offsets of pixels to contextually align upsampled higher-level features; and another feature selection module to emphasize the lower-level features with rich spatial details. We then integrate these two modules in a top-down pyramidal architecture and present the Feature-aligned Pyramid Network (FaPN). Extensive experimental evaluations on four dense prediction tasks and four datasets have demonstrated the efficacy of FaPN, yielding an overall improvement of 1.2 - 2.6 points in AP / mIoU over FPN when paired with Faster / Mask R-CNN. In particular, our FaPN achieves the state-of-the-art of 56.7% mIoU on ADE20K when integrated within Mask-Former. The code is available from https://github.com/EMI-Group/FaPN.
Principled Design of Translation, Scale, and Rotation Invariant Variation Operators for Metaheuristics
May 22, 2021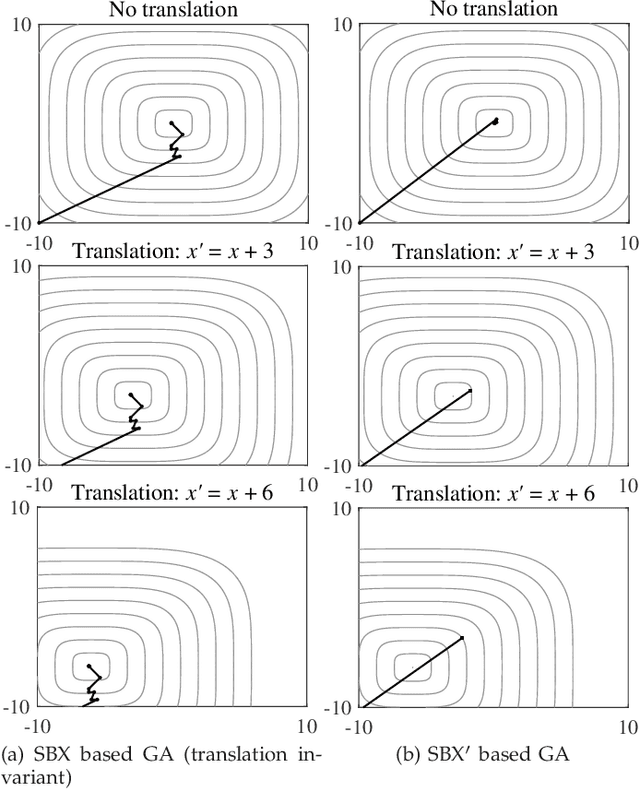

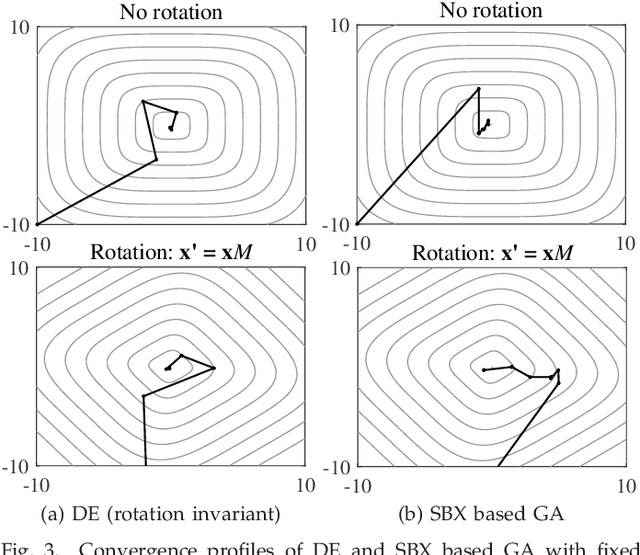

In the past three decades, a large number of metaheuristics have been proposed and shown high performance in solving complex optimization problems. While most variation operators in existing metaheuristics are empirically designed, this paper aims to design new operators automatically, which are expected to be search space independent and thus exhibit robust performance on different problems. For this purpose, this work first investigates the influence of translation invariance, scale invariance, and rotation invariance on the search behavior and performance of some representative operators. Then, we deduce the generic form of translation, scale, and rotation invariant operators. Afterwards, a principled approach is proposed for the automated design of operators, which searches for high-performance operators based on the deduced generic form. The experimental results demonstrate that the operators generated by the proposed approach outperform state-of-the-art ones on a variety of problems with complex landscapes and up to 1000 decision variables.
Multi-objective Neural Architecture Search with Almost No Training
Nov 27, 2020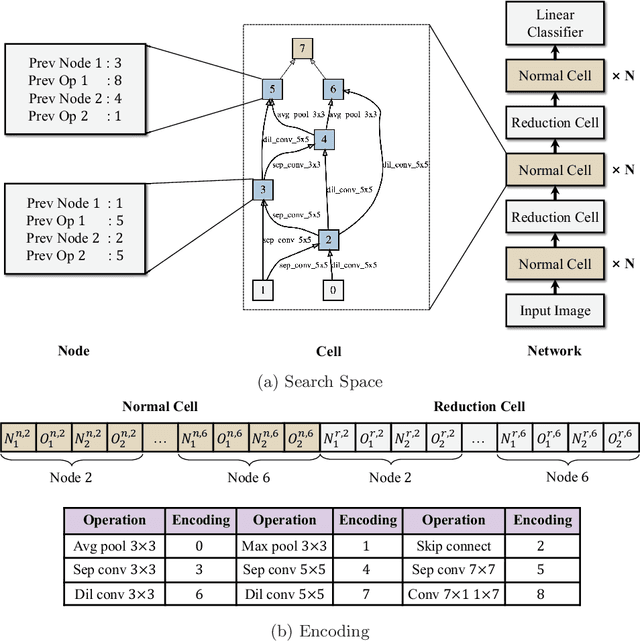
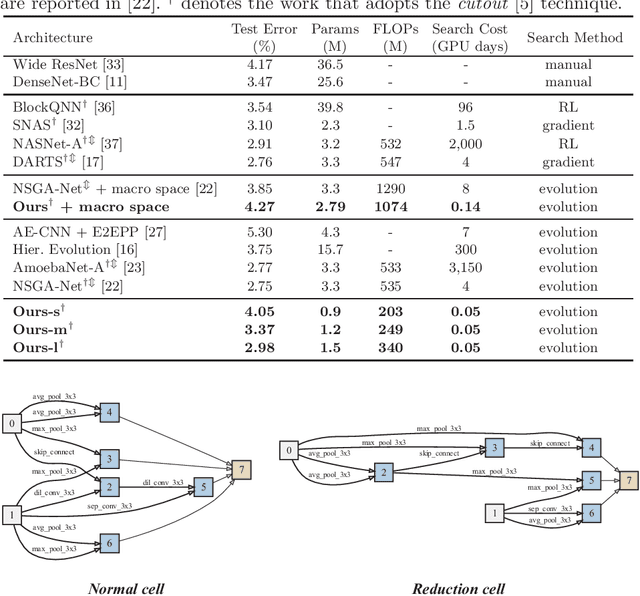
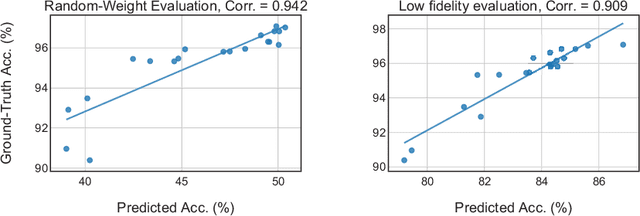

In the recent past, neural architecture search (NAS) has attracted increasing attention from both academia and industries. Despite the steady stream of impressive empirical results, most existing NAS algorithms are computationally prohibitive to execute due to the costly iterations of stochastic gradient descent (SGD) training. In this work, we propose an effective alternative, dubbed Random-Weight Evaluation (RWE), to rapidly estimate the performance of network architectures. By just training the last linear classification layer, RWE reduces the computational cost of evaluating an architecture from hours to seconds. When integrated within an evolutionary multi-objective algorithm, RWE obtains a set of efficient architectures with state-of-the-art performance on CIFAR-10 with less than two hours' searching on a single GPU card. Ablation studies on rank-order correlations and transfer learning experiments to ImageNet have further validated the effectiveness of RWE.
RelativeNAS: Relative Neural Architecture Search via Slow-Fast Learning
Sep 15, 2020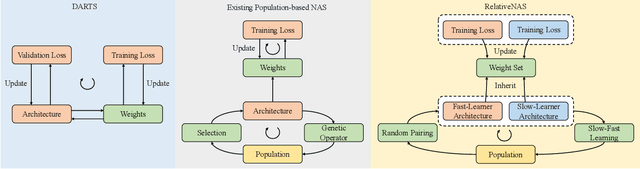
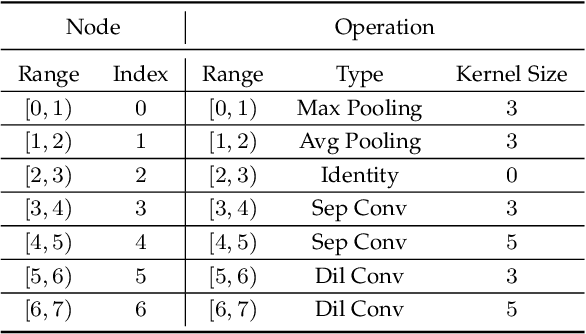
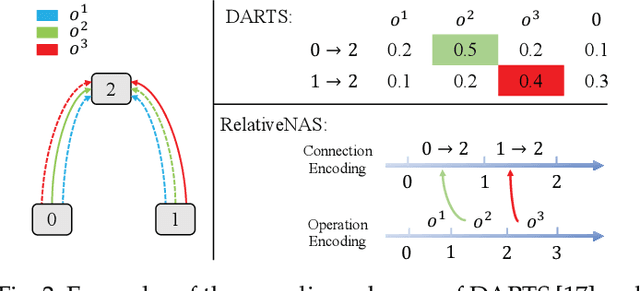
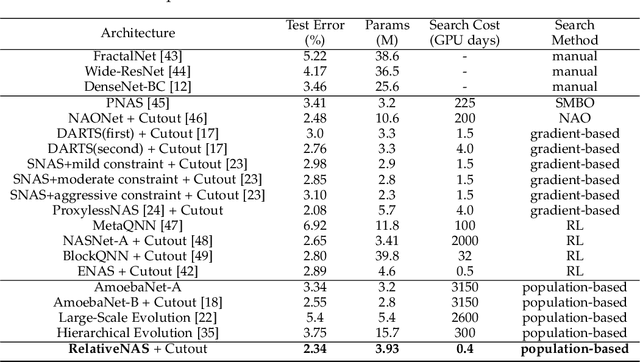
Despite the remarkable successes of Convolutional Neural Networks (CNNs) in computer vision, it is time-consuming and error-prone to manually design a CNN. Among various Neural Architecture Search (NAS) methods that are motivated to automate designs of high-performance CNNs, the differentiable NAS and population-based NAS are attracting increasing interests due to their unique characters. To benefit from the merits while overcoming the deficiencies of both, this work proposes a novel NAS method, RelativeNAS. As the key to efficient search, RelativeNAS performs joint learning between fast-learners (i.e. networks with relatively higher accuracy) and slow-learners in a pairwise manner. Moreover, since RelativeNAS only requires low-fidelity performance estimation to distinguish each pair of fast-learner and slow-learner, it saves certain computation costs for training the candidate architectures. The proposed RelativeNAS brings several unique advantages: (1) it achieves state-of-the-art performance on ImageNet with top-1 error rate of 24.88%, i.e. outperforming DARTS and AmoebaNet-B by 1.82% and 1.12% respectively; (2) it spends only nine hours with a single 1080Ti GPU to obtain the discovered cells, i.e. 3.75x and 7875x faster than DARTS and AmoebaNet respectively; (3) it provides that the discovered cells obtained on CIFAR-10 can be directly transferred to object detection, semantic segmentation, and keypoint detection, yielding competitive results of 73.1% mAP on PASCAL VOC, 78.7% mIoU on Cityscapes, and 68.5% AP on MSCOCO, respectively. The implementation of RelativeNAS is available at https://github.com/EMI-Group/RelativeNAS
Multimodal Image-to-Image Translation via a Single Generative Adversarial Network
Aug 04, 2020
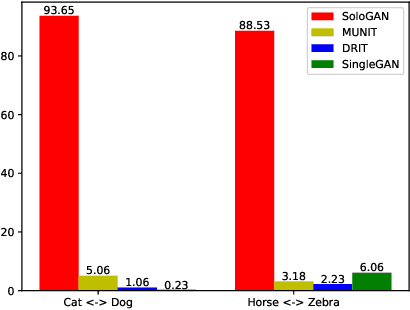


Despite significant advances in image-to-image (I2I) translation with Generative Adversarial Networks (GANs) have been made, it remains challenging to effectively translate an image to a set of diverse images in multiple target domains using a pair of generator and discriminator. Existing multimodal I2I translation methods adopt multiple domain-specific content encoders for different domains, where each domain-specific content encoder is trained with images from the same domain only. Nevertheless, we argue that the content (domain-invariant) features should be learned from images among all the domains. Consequently, each domain-specific content encoder of existing schemes fails to extract the domain-invariant features efficiently. To address this issue, we present a flexible and general SoloGAN model for efficient multimodal I2I translation among multiple domains with unpaired data. In contrast to existing methods, the SoloGAN algorithm uses a single projection discriminator with an additional auxiliary classifier, and shares the encoder and generator for all domains. As such, the SoloGAN model can be trained effectively with images from all domains such that the domain-invariant content representation can be efficiently extracted. Qualitative and quantitative results over a wide range of datasets against several counterparts and variants of the SoloGAN model demonstrate the merits of the method, especially for the challenging I2I translation tasks, i.e., tasks that involve extreme shape variations or need to keep the complex backgrounds unchanged after translations. Furthermore, we demonstrate the contribution of each component using ablation studies.
Robust Data Preprocessing for Machine-Learning-Based Disk Failure Prediction in Cloud Production Environments
Dec 20, 2019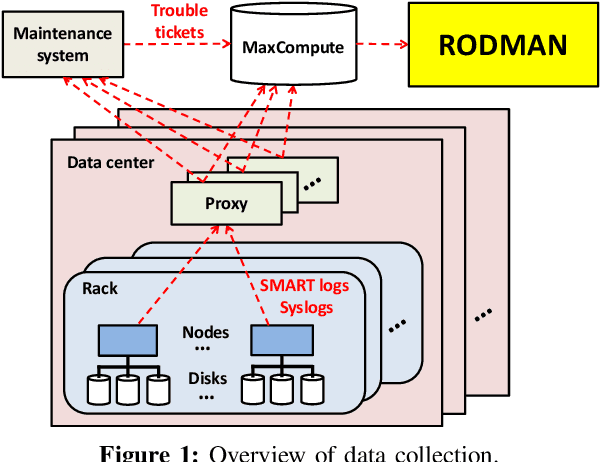
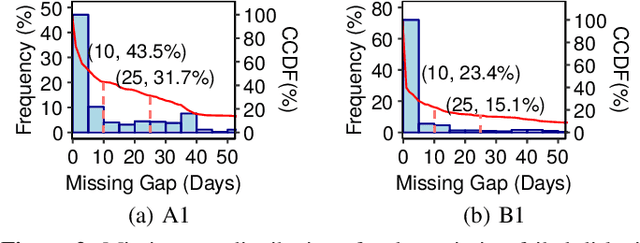


To provide proactive fault tolerance for modern cloud data centers, extensive studies have proposed machine learning (ML) approaches to predict imminent disk failures for early remedy and evaluated their approaches directly on public datasets (e.g., Backblaze SMART logs). However, in real-world production environments, the data quality is imperfect (e.g., inaccurate labeling, missing data samples, and complex failure types), thereby degrading the prediction accuracy. We present RODMAN, a robust data preprocessing pipeline that refines data samples before feeding them into ML models. We start with a large-scale trace-driven study of over three million disks from Alibaba Cloud's data centers, and motivate the practical challenges in ML-based disk failure prediction. We then design RODMAN with three data preprocessing echniques, namely failure-type filtering, spline-based data filling, and automated pre-failure backtracking, that are applicable for general ML models. Evaluation on both the Alibaba and Backblaze datasets shows that RODMAN improves the prediction accuracy compared to without data preprocessing under various settings.