 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoBERT: Plug and Play Toponym Recognition Module Harnessing Fine-tuned BERT
Feb 03, 2023Extracting precise geographical information from textual contents is crucial in a plethora of applications. For example, during hazardous events, a robust and unbiased toponym extraction framework can provide an avenue to tie the location concerned to the topic discussed by news media posts and pinpoint humanitarian help requests or damage reports from social media. Early studies have leveraged rule-based, gazetteer-based, deep learning, and hybrid approaches to address this problem. However, the performance of existing tools is deficient in supporting operations like emergency rescue, which relies on fine-grained, accurate geographic information. The emerging pretrained language models can better capture the underlying characteristics of text information, including place names, offering a promising pathway to optimize toponym recognition to underpin practical applications. In this paper, TopoBERT, a toponym recognition module based on a one dimensional Convolutional Neural Network (CNN1D) and Bidirectional Encoder Representation from Transformers (BERT), is proposed and fine-tuned. Three datasets (CoNLL2003-Train, Wikipedia3000, WNUT2017) are leveraged to tune the hyperparameters, discover the best training strategy, and train the model. Another two datasets (CoNLL2003-Test and Harvey2017) are used to evaluate the performance. Three distinguished classifiers, linear, multi-layer perceptron, and CNN1D, are benchmarked to determine the optimal model architecture. TopoBERT achieves state-of-the-art performance (f1-score=0.865) compared to the other five baseline models and can be applied to diverse toponym recognition tasks without additional training.
Robust Data Preprocessing for Machine-Learning-Based Disk Failure Prediction in Cloud Production Environments
Dec 20, 2019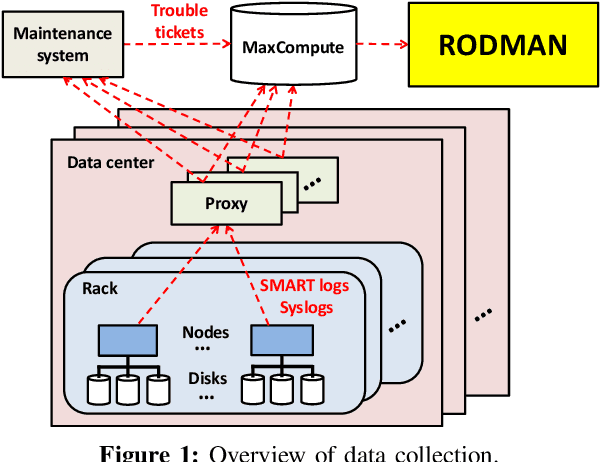
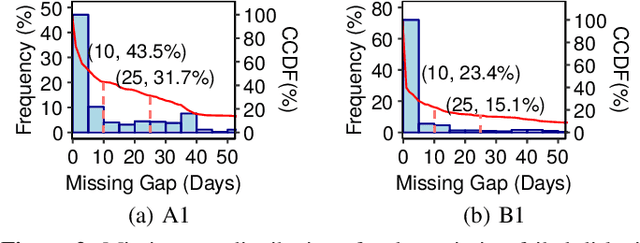


To provide proactive fault tolerance for modern cloud data centers, extensive studies have proposed machine learning (ML) approaches to predict imminent disk failures for early remedy and evaluated their approaches directly on public datasets (e.g., Backblaze SMART logs). However, in real-world production environments, the data quality is imperfect (e.g., inaccurate labeling, missing data samples, and complex failure types), thereby degrading the prediction accuracy. We present RODMAN, a robust data preprocessing pipeline that refines data samples before feeding them into ML models. We start with a large-scale trace-driven study of over three million disks from Alibaba Cloud's data centers, and motivate the practical challenges in ML-based disk failure prediction. We then design RODMAN with three data preprocessing echniques, namely failure-type filtering, spline-based data filling, and automated pre-failure backtracking, that are applicable for general ML models. Evaluation on both the Alibaba and Backblaze datasets shows that RODMAN improves the prediction accuracy compared to without data preprocessing under various settings.