 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimROD: A Simple Baseline for Raw Object Detection with Global and Local Enhancements
Mar 10, 2025


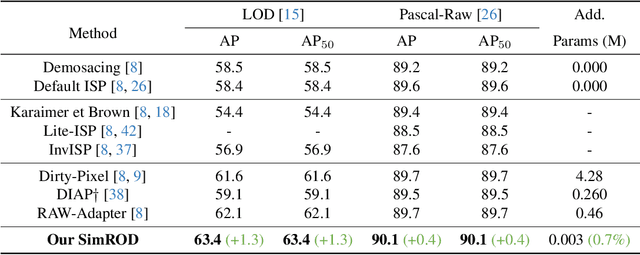
Most visual models are designed for sRGB images, yet RAW data offers significant advantages for object detection by preserving sensor information before ISP processing. This enables improved detection accuracy and more efficient hardware designs by bypassing the ISP. However, RAW object detection is challenging due to limited training data, unbalanced pixel distributions, and sensor noise. To address this, we propose SimROD, a lightweight and effective approach for RAW object detection. We introduce a Global Gamma Enhancement (GGE) module, which applies a learnable global gamma transformation with only four parameters, improving feature representation while keeping the model efficient. Additionally, we leverage the green channel's richer signal to enhance local details, aligning with the human eye's sensitivity and Bayer filter design. Extensive experiments on multiple RAW object detection datasets and detectors demonstrate that SimROD outperforms state-of-the-art methods like RAW-Adapter and DIAP while maintaining efficiency. Our work highlights the potential of RAW data for real-world object detection.
DEIM: DETR with Improved Matching for Fast Convergence
Dec 05, 2024



We introduce DEIM, an innovative and efficient training framework designed to accelerate convergence in real-time object detection with Transformer-based architectures (DETR). To mitigate the sparse supervision inherent in one-to-one (O2O) matching in DETR models, DEIM employs a Dense O2O matching strategy. This approach increases the number of positive samples per image by incorporating additional targets, using standard data augmentation techniques. While Dense O2O matching speeds up convergence, it also introduces numerous low-quality matches that could affect performance. To address this, we propose the Matchability-Aware Loss (MAL), a novel loss function that optimizes matches across various quality levels, enhancing the effectiveness of Dense O2O. Extensive experiments on the COCO dataset validate the efficacy of DEIM. When integrated with RT-DETR and D-FINE, it consistently boosts performance while reducing training time by 50%. Notably, paired with RT-DETRv2, DEIM achieves 53.2% AP in a single day of training on an NVIDIA 4090 GPU. Additionally, DEIM-trained real-time models outperform leading real-time object detectors, with DEIM-D-FINE-L and DEIM-D-FINE-X achieving 54.7% and 56.5% AP at 124 and 78 FPS on an NVIDIA T4 GPU, respectively, without the need for additional data. We believe DEIM sets a new baseline for advancements in real-time object detection. Our code and pre-trained models are available at https://github.com/ShihuaHuang95/DEIM.
From COCO to COCO-FP: A Deep Dive into Background False Positives for COCO Detectors
Sep 12, 2024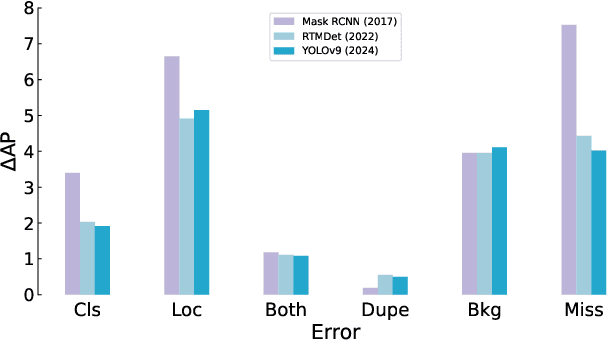
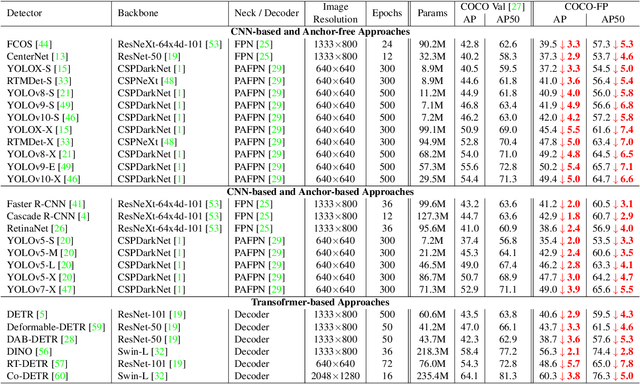
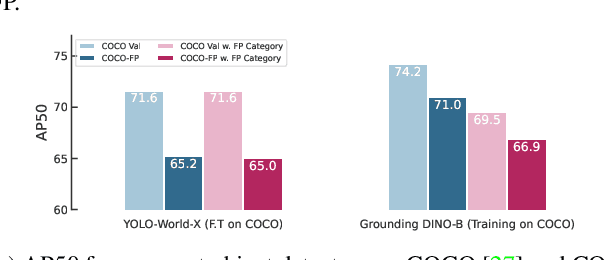
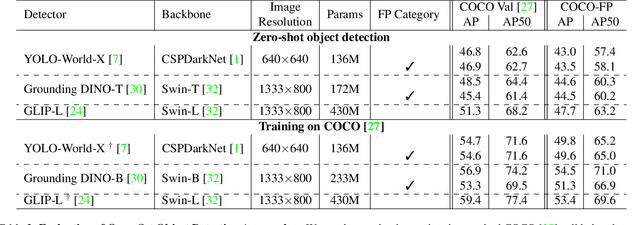
Reducing false positives is essential for enhancing object detector performance, as reflected in the mean Average Precision (mAP) metric. Although object detectors have achieved notable improvements and high mAP scores on the COCO dataset, analysis reveals limited progress in addressing false positives caused by non-target visual clutter-background objects not included in the annotated categories. This issue is particularly critical in real-world applications, such as fire and smoke detection, where minimizing false alarms is crucial. In this study, we introduce COCO-FP, a new evaluation dataset derived from the ImageNet-1K dataset, designed to address this issue. By extending the original COCO validation dataset, COCO-FP specifically assesses object detectors' performance in mitigating background false positives. Our evaluation of both standard and advanced object detectors shows a significant number of false positives in both closed-set and open-set scenarios. For example, the AP50 metric for YOLOv9-E decreases from 72.8 to 65.7 when shifting from COCO to COCO-FP. The dataset is available at https://github.com/COCO-FP/COCO-FP.
Revisiting Residual Networks for Adversarial Robustness: An Architectural Perspective
Dec 21, 2022



Efforts to improve the adversarial robustness of convolutional neural networks have primarily focused on developing more effective adversarial training methods. In contrast, little attention was devoted to analyzing the role of architectural elements (such as topology, depth, and width) on adversarial robustness. This paper seeks to bridge this gap and present a holistic study on the impact of architectural design on adversarial robustness. We focus on residual networks and consider architecture design at the block level, i.e., topology, kernel size, activation, and normalization, as well as at the network scaling level, i.e., depth and width of each block in the network. In both cases, we first derive insights through systematic ablative experiments. Then we design a robust residual block, dubbed RobustResBlock, and a compound scaling rule, dubbed RobustScaling, to distribute depth and width at the desired FLOP count. Finally, we combine RobustResBlock and RobustScaling and present a portfolio of adversarially robust residual networks, RobustResNets, spanning a broad spectrum of model capacities. Experimental validation across multiple datasets and adversarial attacks demonstrate that RobustResNets consistently outperform both the standard WRNs and other existing robust architectures, achieving state-of-the-art AutoAttack robust accuracy of 61.1% without additional data and 63.7% with 500K external data while being $2\times$ more compact in terms of parameters. Code is available at \url{ https://github.com/zhichao-lu/robust-residual-network}
Surrogate-assisted Multi-objective Neural Architecture Search for Real-time Semantic Segmentation
Aug 14, 2022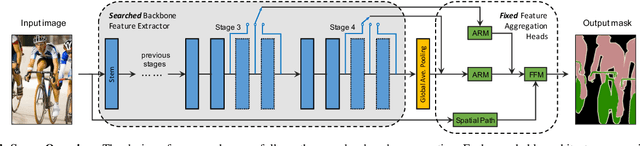
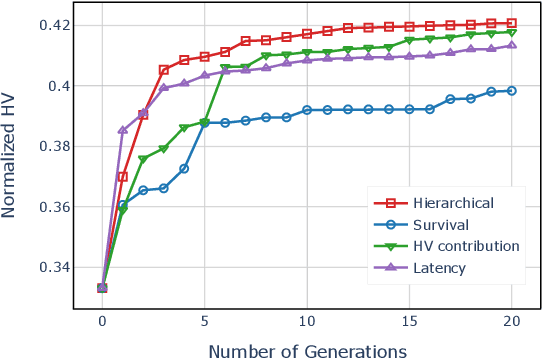
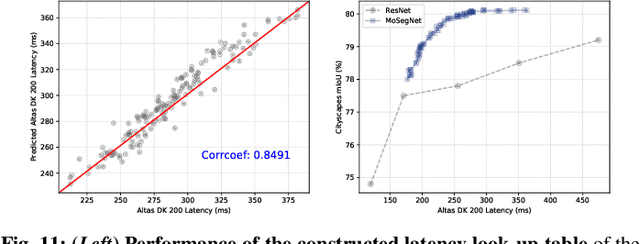
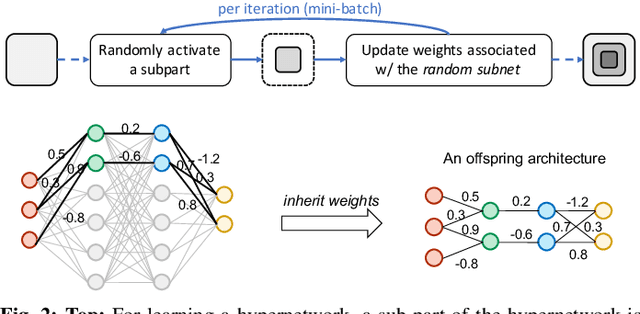
The architectural advancements in deep neural networks have led to remarkable leap-forwards across a broad array of computer vision tasks. Instead of relying on human expertise, neural architecture search (NAS) has emerged as a promising avenue toward automating the design of architectures. While recent achievements in image classification have suggested opportunities, the promises of NAS have yet to be thoroughly assessed on more challenging tasks of semantic segmentation. The main challenges of applying NAS to semantic segmentation arise from two aspects: (i) high-resolution images to be processed; (ii) additional requirement of real-time inference speed (i.e., real-time semantic segmentation) for applications such as autonomous driving. To meet such challenges, we propose a surrogate-assisted multi-objective method in this paper. Through a series of customized prediction models, our method effectively transforms the original NAS task into an ordinary multi-objective optimization problem. Followed by a hierarchical pre-screening criterion for in-fill selection, our method progressively achieves a set of efficient architectures trading-off between segmentation accuracy and inference speed. Empirical evaluations on three benchmark datasets together with an application using Huawei Atlas 200 DK suggest that our method can identify architectures significantly outperforming existing state-of-the-art architectures designed both manually by human experts and automatically by other NAS methods.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022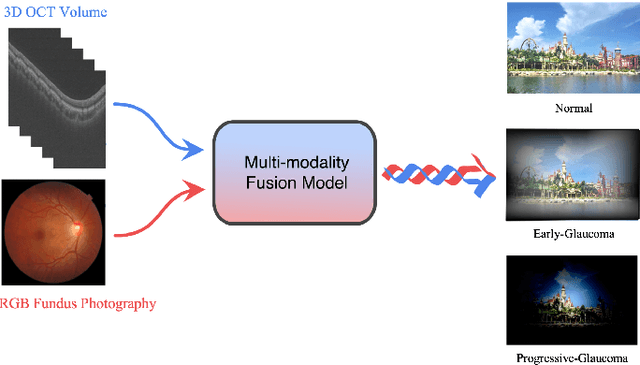
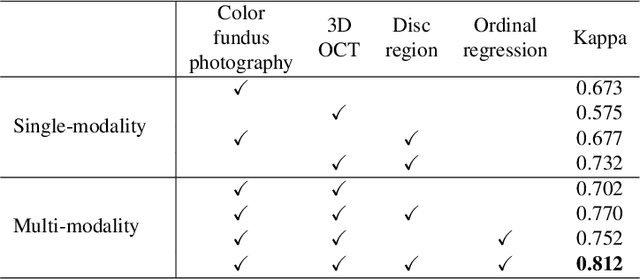
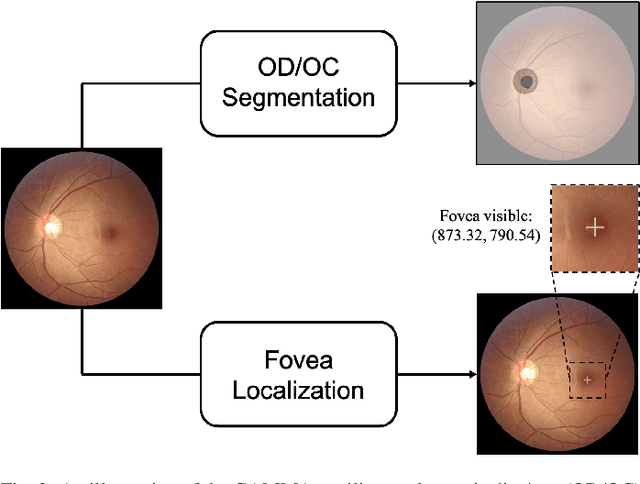
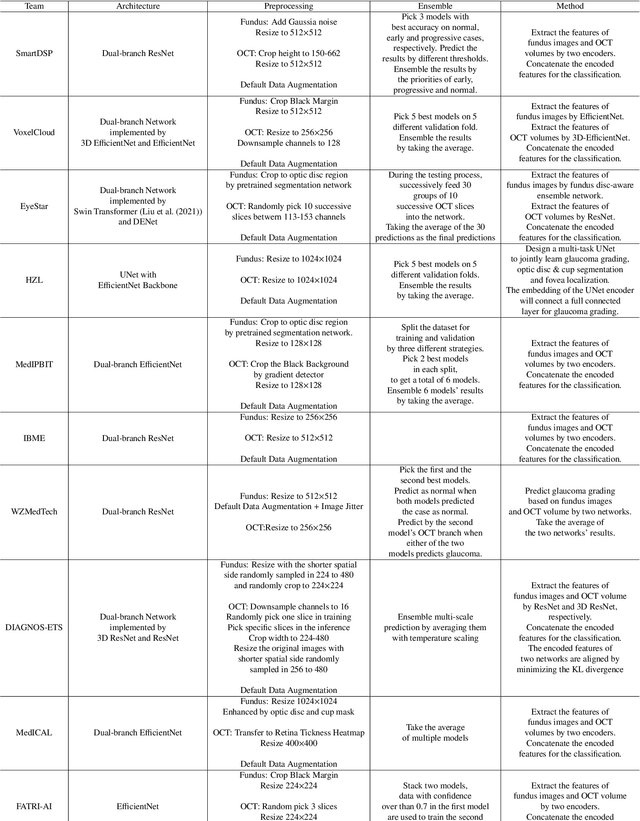
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
FaPN: Feature-aligned Pyramid Network for Dense Image Prediction
Aug 17, 2021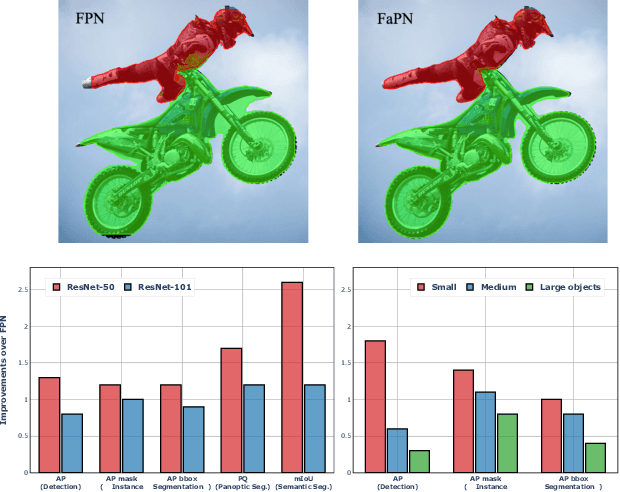
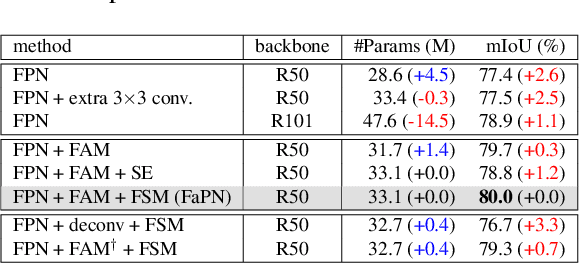
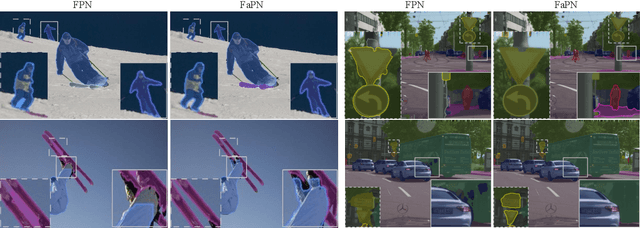
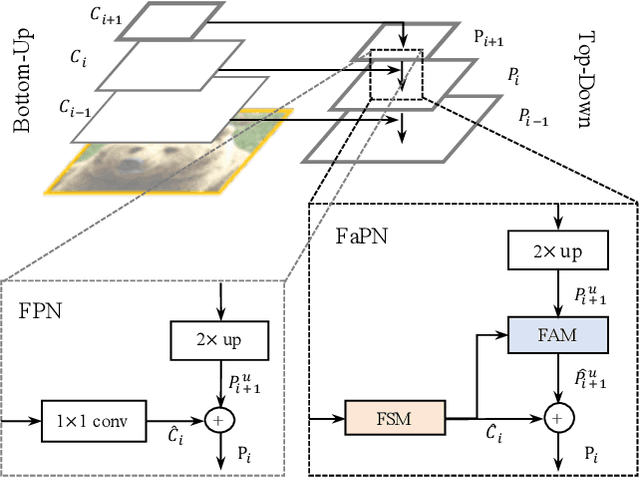
Recent advancements in deep neural networks have made remarkable leap-forwards in dense image prediction. However, the issue of feature alignment remains as neglected by most existing approaches for simplicity. Direct pixel addition between upsampled and local features leads to feature maps with misaligned contexts that, in turn, translate to mis-classifications in prediction, especially on object boundaries. In this paper, we propose a feature alignment module that learns transformation offsets of pixels to contextually align upsampled higher-level features; and another feature selection module to emphasize the lower-level features with rich spatial details. We then integrate these two modules in a top-down pyramidal architecture and present the Feature-aligned Pyramid Network (FaPN). Extensive experimental evaluations on four dense prediction tasks and four datasets have demonstrated the efficacy of FaPN, yielding an overall improvement of 1.2 - 2.6 points in AP / mIoU over FPN when paired with Faster / Mask R-CNN. In particular, our FaPN achieves the state-of-the-art of 56.7% mIoU on ADE20K when integrated within Mask-Former. The code is available from https://github.com/EMI-Group/FaPN.
RelativeNAS: Relative Neural Architecture Search via Slow-Fast Learning
Sep 15, 2020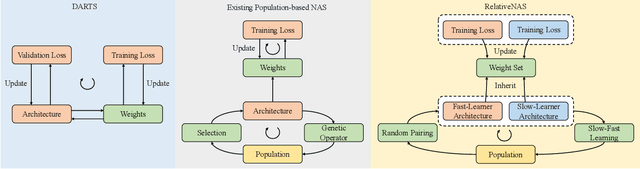
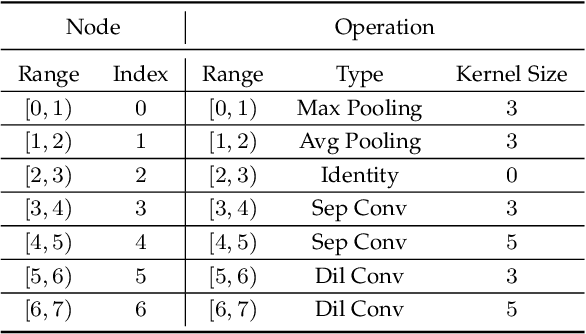
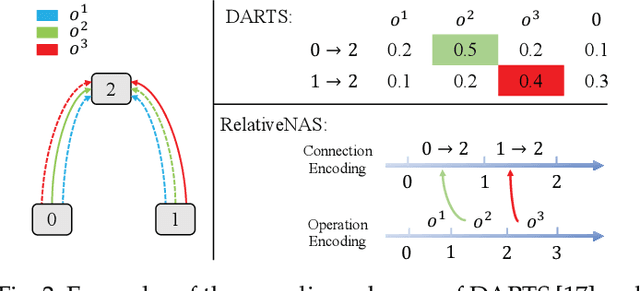
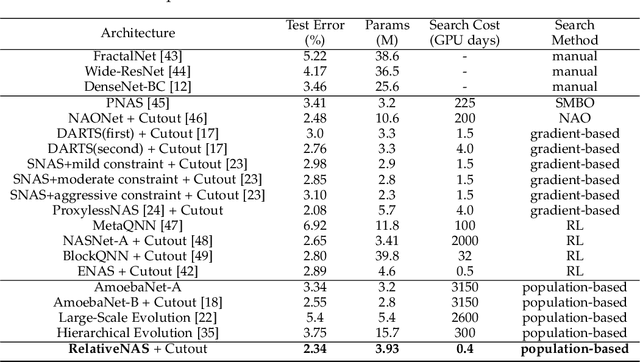
Despite the remarkable successes of Convolutional Neural Networks (CNNs) in computer vision, it is time-consuming and error-prone to manually design a CNN. Among various Neural Architecture Search (NAS) methods that are motivated to automate designs of high-performance CNNs, the differentiable NAS and population-based NAS are attracting increasing interests due to their unique characters. To benefit from the merits while overcoming the deficiencies of both, this work proposes a novel NAS method, RelativeNAS. As the key to efficient search, RelativeNAS performs joint learning between fast-learners (i.e. networks with relatively higher accuracy) and slow-learners in a pairwise manner. Moreover, since RelativeNAS only requires low-fidelity performance estimation to distinguish each pair of fast-learner and slow-learner, it saves certain computation costs for training the candidate architectures. The proposed RelativeNAS brings several unique advantages: (1) it achieves state-of-the-art performance on ImageNet with top-1 error rate of 24.88%, i.e. outperforming DARTS and AmoebaNet-B by 1.82% and 1.12% respectively; (2) it spends only nine hours with a single 1080Ti GPU to obtain the discovered cells, i.e. 3.75x and 7875x faster than DARTS and AmoebaNet respectively; (3) it provides that the discovered cells obtained on CIFAR-10 can be directly transferred to object detection, semantic segmentation, and keypoint detection, yielding competitive results of 73.1% mAP on PASCAL VOC, 78.7% mIoU on Cityscapes, and 68.5% AP on MSCOCO, respectively. The implementation of RelativeNAS is available at https://github.com/EMI-Group/RelativeNAS
Multimodal Image-to-Image Translation via a Single Generative Adversarial Network
Aug 04, 2020
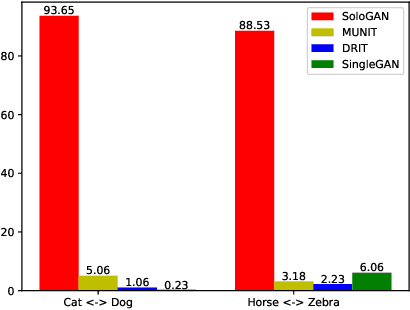


Despite significant advances in image-to-image (I2I) translation with Generative Adversarial Networks (GANs) have been made, it remains challenging to effectively translate an image to a set of diverse images in multiple target domains using a pair of generator and discriminator. Existing multimodal I2I translation methods adopt multiple domain-specific content encoders for different domains, where each domain-specific content encoder is trained with images from the same domain only. Nevertheless, we argue that the content (domain-invariant) features should be learned from images among all the domains. Consequently, each domain-specific content encoder of existing schemes fails to extract the domain-invariant features efficiently. To address this issue, we present a flexible and general SoloGAN model for efficient multimodal I2I translation among multiple domains with unpaired data. In contrast to existing methods, the SoloGAN algorithm uses a single projection discriminator with an additional auxiliary classifier, and shares the encoder and generator for all domains. As such, the SoloGAN model can be trained effectively with images from all domains such that the domain-invariant content representation can be efficiently extracted. Qualitative and quantitative results over a wide range of datasets against several counterparts and variants of the SoloGAN model demonstrate the merits of the method, especially for the challenging I2I translation tasks, i.e., tasks that involve extreme shape variations or need to keep the complex backgrounds unchanged after translations. Furthermore, we demonstrate the contribution of each component using ablation studies.
Evolutionary Multi-Objective Optimization Driven by Generative Adversarial Networks
Oct 11, 2019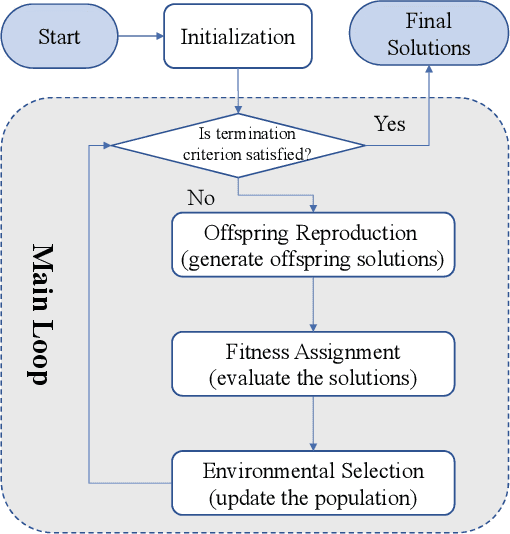
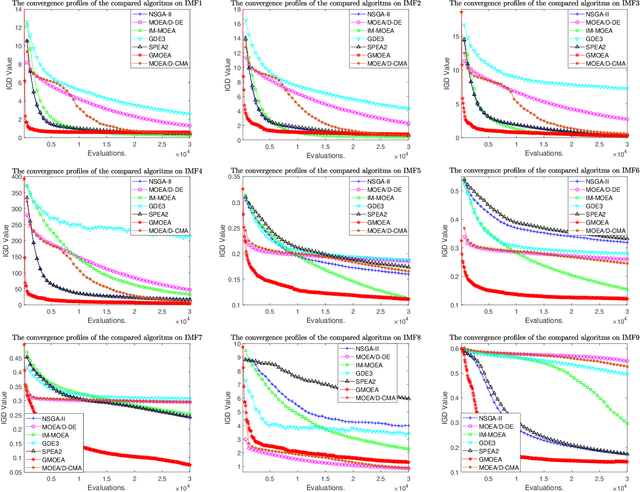
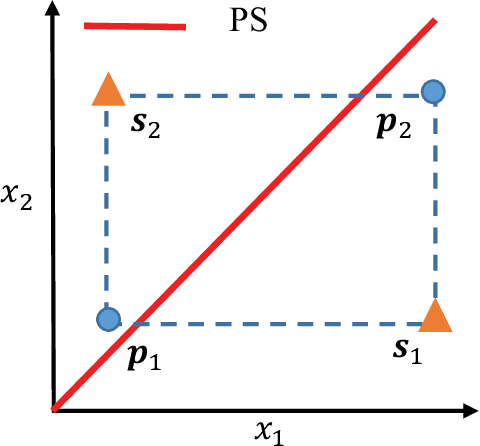
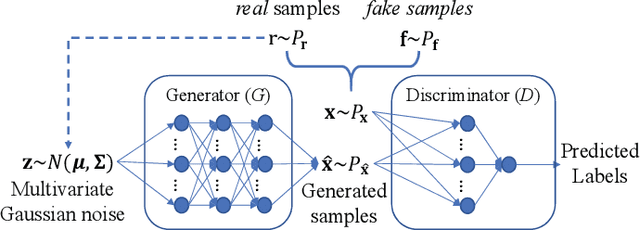
Recently, more and more works have proposed to drive evolutionary algorithms using machine learning models. Usually, the performance of such model based evolutionary algorithms is highly dependent on the training qualities of the adopted models. Since it usually requires a certain amount of data (i.e. the candidate solutions generated by the algorithms) for model training, the performance deteriorates rapidly with the increase of the problem scales, due to the curse of dimensionality. To address this issue, we propose a multi-objective evolutionary algorithm driven by the generative adversarial networks (GANs). At each generation of the proposed algorithm, the parent solutions are first classified into real and fake samples to train the GANs; then the offspring solutions are sampled by the trained GANs. Thanks to the powerful generative ability of the GANs, our proposed algorithm is capable of generating promising offspring solutions in high-dimensional decision space with limited training data. The proposed algorithm is tested on 10 benchmark problems with up to 200 decision variables. Experimental results on these test problems demonstrate the effectiveness of the proposed algorithm.