 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Deep Features to Track: Self-Supervised Feature Extraction and Tracking in Visual Odometry
Sep 10, 2025Visual-based localization has made significant progress, yet its performance often drops in large-scale, outdoor, and long-term settings due to factors like lighting changes, dynamic scenes, and low-texture areas. These challenges degrade feature extraction and tracking, which are critical for accurate motion estimation. While learning-based methods such as SuperPoint and SuperGlue show improved feature coverage and robustness, they still face generalization issues with out-of-distribution data. We address this by enhancing deep feature extraction and tracking through self-supervised learning with task specific feedback. Our method promotes stable and informative features, improving generalization and reliability in challenging environments.
SVN-ICP: Uncertainty Estimation of ICP-based LiDAR Odometry using Stein Variational Newton
Sep 09, 2025This letter introduces SVN-ICP, a novel Iterative Closest Point (ICP) algorithm with uncertainty estimation that leverages Stein Variational Newton (SVN) on manifold. Designed specifically for fusing LiDAR odometry in multisensor systems, the proposed method ensures accurate pose estimation and consistent noise parameter inference, even in LiDAR-degraded environments. By approximating the posterior distribution using particles within the Stein Variational Inference framework, SVN-ICP eliminates the need for explicit noise modeling or manual parameter tuning. To evaluate its effectiveness, we integrate SVN-ICP into a simple error-state Kalman filter alongside an IMU and test it across multiple datasets spanning diverse environments and robot types. Extensive experimental results demonstrate that our approach outperforms best-in-class methods on challenging scenarios while providing reliable uncertainty estimates.
Robust Statistics vs. Machine Learning vs. Bayesian Inference: Insights into Handling Faulty GNSS Measurements in Field Robotics
Apr 08, 2025This paper presents research findings on handling faulty measurements (i.e., outliers) of global navigation satellite systems (GNSS) for robot localization under adverse signal conditions in field applications, where raw GNSS data are frequently corrupted due to environmental interference such as multipath, signal blockage, or non-line-of-sight conditions. In this context, we investigate three strategies applied specifically to GNSS pseudorange observations: robust statistics for error mitigation, machine learning for faulty measurement prediction, and Bayesian inference for noise distribution approximation. Since previous studies have provided limited insight into the theoretical foundations and practical evaluations of these three methodologies within a unified problem statement (i.e., state estimation using ranging sensors), we conduct extensive experiments using real-world sensor data collected in diverse urban environments. Our goal is to examine both established techniques and newly proposed methods, thereby advancing the understanding of how to handle faulty range measurements, such as GNSS, for robust, long-term robot localization. In addition to presenting successful results, this work highlights critical observations and open questions to motivate future research in robust state estimation.
Learning-based GNSS Uncertainty Quantification using Continuous-Time Factor Graph Optimization
Mar 06, 2025This short paper presents research findings on two learning-based methods for quantifying measurement uncertainties in global navigation satellite systems (GNSS). We investigate two learning strategies: offline learning for outlier prediction and online learning for noise distribution approximation, specifically applied to GNSS pseudorange observations. To develop and evaluate these learning methods, we introduce a novel multisensor state estimator that accurately and robustly estimates trajectory from multiple sensor inputs, critical for deriving GNSS measurement residuals used to train the uncertainty models. We validate the proposed learning-based models using real-world sensor data collected in diverse urban environments. Experimental results demonstrate that both models effectively handle GNSS outliers and improve state estimation performance. Furthermore, we provide insightful discussions to motivate future research toward developing a federated framework for robust vehicle localization in challenging environments.
FR-NAS: Forward-and-Reverse Graph Predictor for Efficient Neural Architecture Search
Apr 24, 2024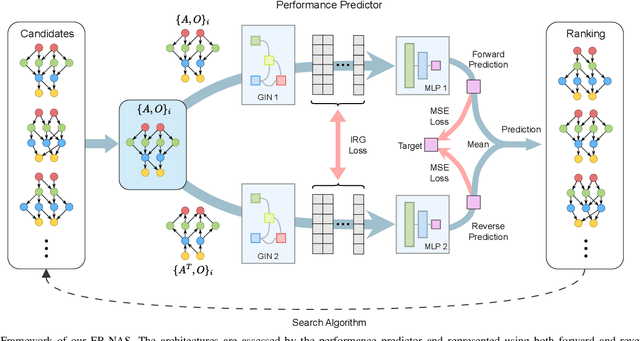
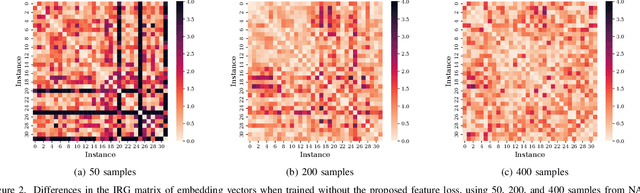
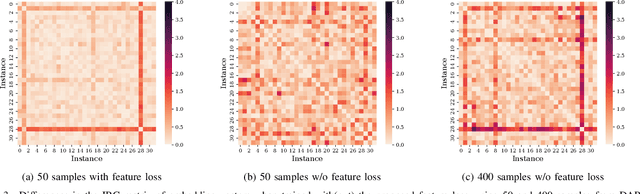

Neural Architecture Search (NAS) has emerged as a key tool in identifying optimal configurations of deep neural networks tailored to specific tasks. However, training and assessing numerous architectures introduces considerable computational overhead. One method to mitigating this is through performance predictors, which offer a means to estimate the potential of an architecture without exhaustive training. Given that neural architectures fundamentally resemble Directed Acyclic Graphs (DAGs), Graph Neural Networks (GNNs) become an apparent choice for such predictive tasks. Nevertheless, the scarcity of training data can impact the precision of GNN-based predictors. To address this, we introduce a novel GNN predictor for NAS. This predictor renders neural architectures into vector representations by combining both the conventional and inverse graph views. Additionally, we incorporate a customized training loss within the GNN predictor to ensure efficient utilization of both types of representations. We subsequently assessed our method through experiments on benchmark datasets including NAS-Bench-101, NAS-Bench-201, and the DARTS search space, with a training dataset ranging from 50 to 400 samples. Benchmarked against leading GNN predictors, the experimental results showcase a significant improvement in prediction accuracy, with a 3%--16% increase in Kendall-tau correlation. Source codes are available at https://github.com/EMI-Group/fr-nas.
Let's Go Shopping -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.
GNSS/Multi-Sensor Fusion Using Continuous-Time Factor Graph Optimization for Robust Localization
Sep 20, 2023



Accurate and robust vehicle localization in highly urbanized areas is challenging. Sensors are often corrupted in those complicated and large-scale environments. This paper introduces GNSS-FGO, an online and global trajectory estimator that fuses GNSS observations alongside multiple sensor measurements for robust vehicle localization. In GNSS-FGO, we fuse asynchronous sensor measurements into the graph with a continuous-time trajectory representation using Gaussian process regression. This enables querying states at arbitrary timestamps so that sensor observations are fused without requiring strict state and measurement synchronization. Thus, the proposed method presents a generalized factor graph for multi-sensor fusion. To evaluate and study different GNSS fusion strategies, we fuse GNSS measurements in loose and tight coupling with a speed sensor, IMU, and lidar-odometry. We employed datasets from measurement campaigns in Aachen, Duesseldorf, and Cologne in experimental studies and presented comprehensive discussions on sensor observations, smoother types, and hyperparameter tuning. Our results show that the proposed approach enables robust trajectory estimation in dense urban areas, where the classic multi-sensor fusion method fails due to sensor degradation. In a test sequence containing a 17km route through Aachen, the proposed method results in a mean 2D positioning error of 0.19m for loosely coupled GNSS fusion and 0.48m while fusing raw GNSS observations with lidar odometry in tight coupling.
Learning-based NLOS Detection and Uncertainty Prediction of GNSS Observations with Transformer-Enhanced LSTM Network
Sep 01, 2023The global navigation satellite systems (GNSS) play a vital role in transport systems for accurate and consistent vehicle localization. However, GNSS observations can be distorted due to multipath effects and non-line-of-sight (NLOS) receptions in challenging environments such as urban canyons. In such cases, traditional methods to classify and exclude faulty GNSS observations may fail, leading to unreliable state estimation and unsafe system operations. This work proposes a Deep-Learning-based method to detect NLOS receptions and predict GNSS pseudorange errors by analyzing GNSS observations as a spatio-temporal modeling problem. Compared to previous works, we construct a transformer-like attention mechanism to enhance the long short-term memory (LSTM) networks, improving model performance and generalization. For the training and evaluation of the proposed network, we used labeled datasets from the cities of Hong Kong and Aachen. We also introduce a dataset generation process to label the GNSS observations using lidar maps. In experimental studies, we compare the proposed network with a deep-learning-based model and classical machine-learning models. Furthermore, we conduct ablation studies of our network components and integrate the NLOS detection with data out-of-distribution in a state estimator. As a result, our network presents improved precision and recall ratios compared to other models. Additionally, we show that the proposed method avoids trajectory divergence in real-world vehicle localization by classifying and excluding NLOS observations.
onlineFGO: Online Continuous-Time Factor Graph Optimization with Time-Centric Multi-Sensor Fusion for Robust Localization in Large-Scale Environments
Nov 10, 2022Accurate and consistent vehicle localization in urban areas is challenging due to the large-scale and complicated environments. In this paper, we propose onlineFGO, a novel time-centric graph-optimization-based localization method that fuses multiple sensor measurements with the continuous-time trajectory representation for vehicle localization tasks. We generalize the graph construction independent of any spatial sensor measurements by creating the states deterministically on time. As the trajectory representation in continuous-time enables querying states at arbitrary times, incoming sensor measurements can be factorized on the graph without requiring state alignment. We integrate different GNSS observations: pseudorange, deltarange, and time-differenced carrier phase (TDCP) to ensure global reference and fuse the relative motion from a LiDAR-odometry to improve the localization consistency while GNSS observations are not available. Experiments on general performance, effects of different factors, and hyper-parameter settings are conducted in a real-world measurement campaign in Aachen city that contains different urban scenarios. Our results show an average 2D error of 0.99m and consistent state estimation in urban scenarios.
Surrogate-assisted Multi-objective Neural Architecture Search for Real-time Semantic Segmentation
Aug 14, 2022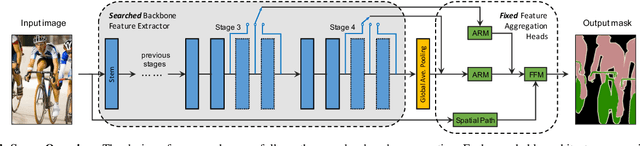
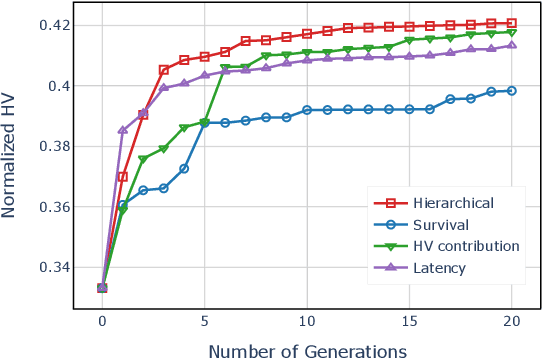
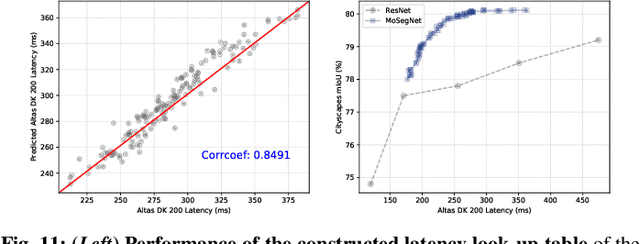
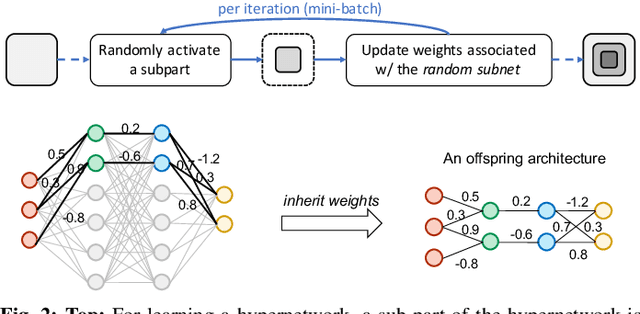
The architectural advancements in deep neural networks have led to remarkable leap-forwards across a broad array of computer vision tasks. Instead of relying on human expertise, neural architecture search (NAS) has emerged as a promising avenue toward automating the design of architectures. While recent achievements in image classification have suggested opportunities, the promises of NAS have yet to be thoroughly assessed on more challenging tasks of semantic segmentation. The main challenges of applying NAS to semantic segmentation arise from two aspects: (i) high-resolution images to be processed; (ii) additional requirement of real-time inference speed (i.e., real-time semantic segmentation) for applications such as autonomous driving. To meet such challenges, we propose a surrogate-assisted multi-objective method in this paper. Through a series of customized prediction models, our method effectively transforms the original NAS task into an ordinary multi-objective optimization problem. Followed by a hierarchical pre-screening criterion for in-fill selection, our method progressively achieves a set of efficient architectures trading-off between segmentation accuracy and inference speed. Empirical evaluations on three benchmark datasets together with an application using Huawei Atlas 200 DK suggest that our method can identify architectures significantly outperforming existing state-of-the-art architectures designed both manually by human experts and automatically by other NAS methods.