 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Let's Go Shopping -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.
On the Performance of Multimodal Language Models
Oct 04, 2023Instruction-tuned large language models (LLMs) have demonstrated promising zero-shot generalization capabilities across various downstream tasks. Recent research has introduced multimodal capabilities to LLMs by integrating independently pretrained vision encoders through model grafting. These multimodal variants undergo instruction tuning, similar to LLMs, enabling effective zero-shot generalization for multimodal tasks. This study conducts a comparative analysis of different multimodal instruction tuning approaches and evaluates their performance across a range of tasks, including complex reasoning, conversation, image captioning, multiple-choice questions (MCQs), and binary classification. Through rigorous benchmarking and ablation experiments, we reveal key insights for guiding architectural choices when incorporating multimodal capabilities into LLMs. However, current approaches have limitations; they do not sufficiently address the need for a diverse multimodal instruction dataset, which is crucial for enhancing task generalization. Additionally, they overlook issues related to truthfulness and factuality when generating responses. These findings illuminate current methodological constraints in adapting language models for image comprehension and provide valuable guidance for researchers and practitioners seeking to harness multimodal versions of LLMs.
Fabrik: An Online Collaborative Neural Network Editor
Oct 27, 2018
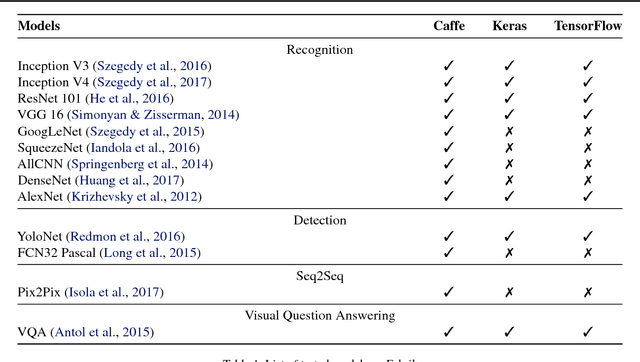
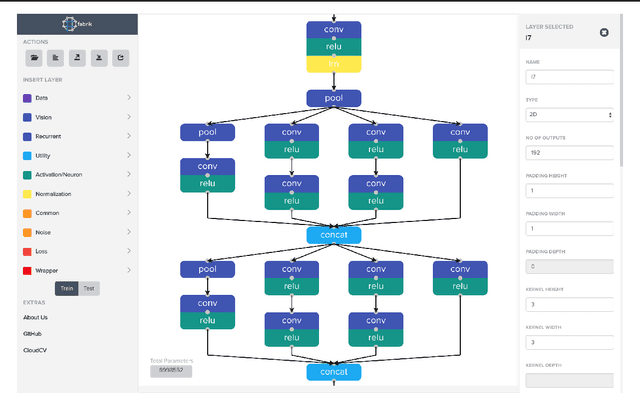

We present Fabrik, an online neural network editor that provides tools to visualize, edit, and share neural networks from within a browser. Fabrik provides a simple and intuitive GUI to import neural networks written in popular deep learning frameworks such as Caffe, Keras, and TensorFlow, and allows users to interact with, build, and edit models via simple drag and drop. Fabrik is designed to be framework agnostic and support high interoperability, and can be used to export models back to any supported framework. Finally, it provides powerful collaborative features to enable users to iterate over model design remotely and at scale.
NAG: Network for Adversary Generation
Mar 28, 2018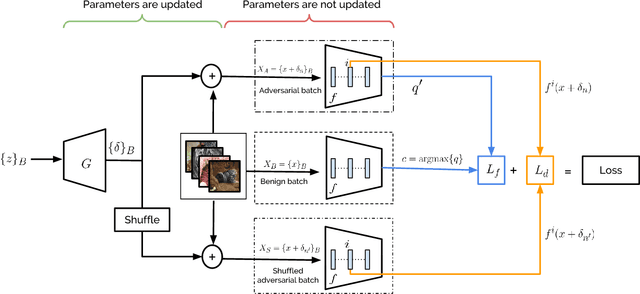
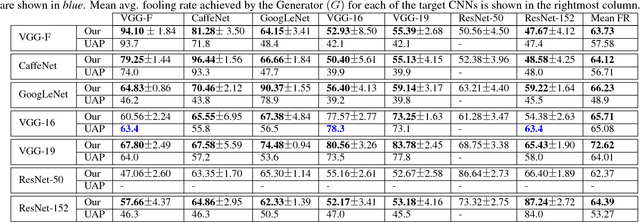

Adversarial perturbations can pose a serious threat for deploying machine learning systems. Recent works have shown existence of image-agnostic perturbations that can fool classifiers over most natural images. Existing methods present optimization approaches that solve for a fooling objective with an imperceptibility constraint to craft the perturbations. However, for a given classifier, they generate one perturbation at a time, which is a single instance from the manifold of adversarial perturbations. Also, in order to build robust models, it is essential to explore the manifold of adversarial perturbations. In this paper, we propose for the first time, a generative approach to model the distribution of adversarial perturbations. The architecture of the proposed model is inspired from that of GANs and is trained using fooling and diversity objectives. Our trained generator network attempts to capture the distribution of adversarial perturbations for a given classifier and readily generates a wide variety of such perturbations. Our experimental evaluation demonstrates that perturbations crafted by our model (i) achieve state-of-the-art fooling rates, (ii) exhibit wide variety and (iii) deliver excellent cross model generalizability. Our work can be deemed as an important step in the process of inferring about the complex manifolds of adversarial perturbations.
CNN Fixations: An unraveling approach to visualize the discriminative image regions
Aug 23, 2017
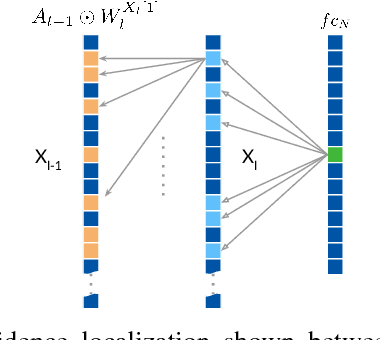
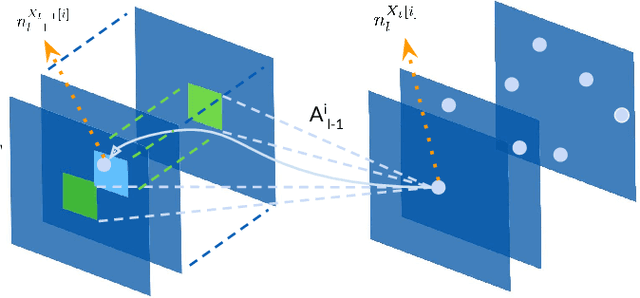
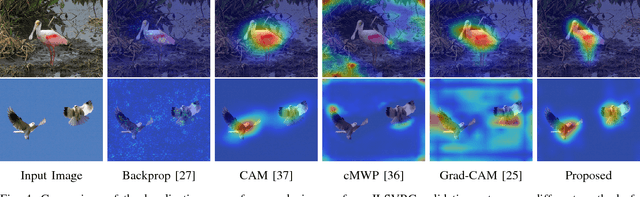
Deep convolutional neural networks (CNN) have revolutionized various fields of vision research and have seen unprecedented adoption for multiple tasks such as classification, detection, captioning, etc. However, they offer little transparency into their inner workings and are often treated as black boxes that deliver excellent performance. In this work, we aim at alleviating this opaqueness of CNNs by providing visual explanations for the network's predictions. Our approach can analyze variety of CNN based models trained for vision applications such as object recognition and caption generation. Unlike existing methods, we achieve this via unraveling the forward pass operation. Proposed method exploits feature dependencies across the layer hierarchy and uncovers the discriminative image locations that guide the network's predictions. We name these locations CNN-Fixations, loosely analogous to human eye fixations. Our approach is a generic method that requires no architectural changes, additional training or gradient computation and computes the important image locations (CNN Fixations). We demonstrate through a variety of applications that our approach is able to localize the discriminative image locations across different network architectures, diverse vision tasks and data modalities.
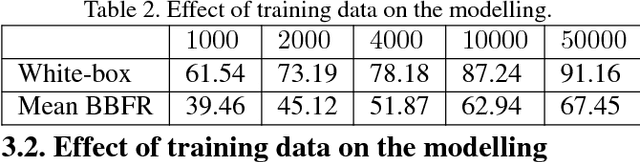
Fast Feature Fool: A data independent approach to universal adversarial perturbations
Jul 18, 2017
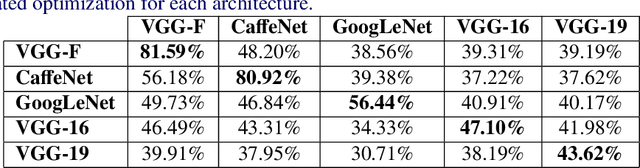


State-of-the-art object recognition Convolutional Neural Networks (CNNs) are shown to be fooled by image agnostic perturbations, called universal adversarial perturbations. It is also observed that these perturbations generalize across multiple networks trained on the same target data. However, these algorithms require training data on which the CNNs were trained and compute adversarial perturbations via complex optimization. The fooling performance of these approaches is directly proportional to the amount of available training data. This makes them unsuitable for practical attacks since its unreasonable for an attacker to have access to the training data. In this paper, for the first time, we propose a novel data independent approach to generate image agnostic perturbations for a range of CNNs trained for object recognition. We further show that these perturbations are transferable across multiple network architectures trained either on same or different data. In the absence of data, our method generates universal adversarial perturbations efficiently via fooling the features learned at multiple layers thereby causing CNNs to misclassify. Experiments demonstrate impressive fooling rates and surprising transferability for the proposed universal perturbations generated without any training data.