 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Go Shopping -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.
GlideNet: Global, Local and Intrinsic based Dense Embedding NETwork for Multi-category Attributes Prediction
Mar 14, 2022



Attaching attributes (such as color, shape, state, action) to object categories is an important computer vision problem. Attribute prediction has seen exciting recent progress and is often formulated as a multi-label classification problem. Yet significant challenges remain in: 1) predicting diverse attributes over multiple categories, 2) modeling attributes-category dependency, 3) capturing both global and local scene context, and 4) predicting attributes of objects with low pixel-count. To address these issues, we propose a novel multi-category attribute prediction deep architecture named GlideNet, which contains three distinct feature extractors. A global feature extractor recognizes what objects are present in a scene, whereas a local one focuses on the area surrounding the object of interest. Meanwhile, an intrinsic feature extractor uses an extension of standard convolution dubbed Informed Convolution to retrieve features of objects with low pixel-count. GlideNet uses gating mechanisms with binary masks and its self-learned category embedding to combine the dense embeddings. Collectively, the Global-Local-Intrinsic blocks comprehend the scene's global context while attending to the characteristics of the local object of interest. Finally, using the combined features, an interpreter predicts the attributes, and the length of the output is determined by the category, thereby removing unnecessary attributes. GlideNet can achieve compelling results on two recent and challenging datasets -- VAW and CAR -- for large-scale attribute prediction. For instance, it obtains more than 5\% gain over state of the art in the mean recall (mR) metric. GlideNet's advantages are especially apparent when predicting attributes of objects with low pixel counts as well as attributes that demand global context understanding. Finally, we show that GlideNet excels in training starved real-world scenarios.
CAR -- Cityscapes Attributes Recognition A Multi-category Attributes Dataset for Autonomous Vehicles
Nov 16, 2021



Self-driving vehicles are the future of transportation. With current advancements in this field, the world is getting closer to safe roads with almost zero probability of having accidents and eliminating human errors. However, there is still plenty of research and development necessary to reach a level of robustness. One important aspect is to understand a scene fully including all details. As some characteristics (attributes) of objects in a scene (drivers' behavior for instance) could be imperative for correct decision making. However, current algorithms suffer from low-quality datasets with such rich attributes. Therefore, in this paper, we present a new dataset for attributes recognition -- Cityscapes Attributes Recognition (CAR). The new dataset extends the well-known dataset Cityscapes by adding an additional yet important annotation layer of attributes of objects in each image. Currently, we have annotated more than 32k instances of various categories (Vehicles, Pedestrians, etc.). The dataset has a structured and tailored taxonomy where each category has its own set of possible attributes. The tailored taxonomy focuses on attributes that is of most beneficent for developing better self-driving algorithms that depend on accurate computer vision and scene comprehension. We have also created an API for the dataset to ease the usage of CAR. The API can be accessed through https://github.com/kareem-metwaly/CAR-API.
Natural Adversarial Objects
Nov 07, 2021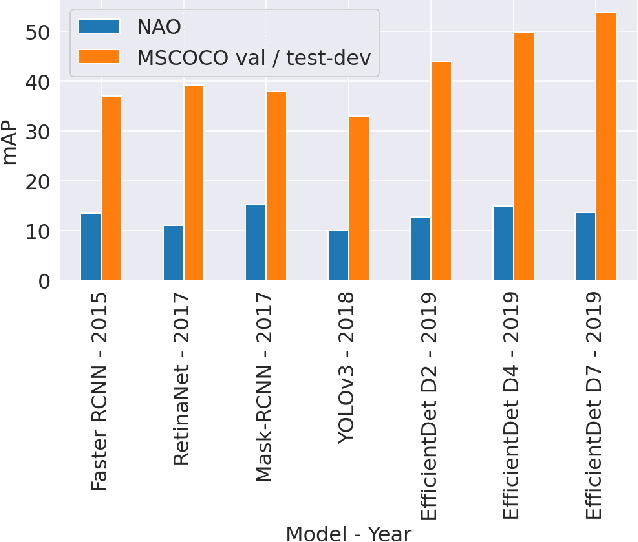


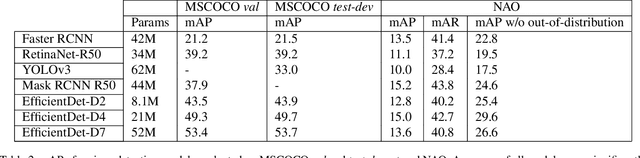
Although state-of-the-art object detection methods have shown compelling performance, models often are not robust to adversarial attacks and out-of-distribution data. We introduce a new dataset, Natural Adversarial Objects (NAO), to evaluate the robustness of object detection models. NAO contains 7,934 images and 9,943 objects that are unmodified and representative of real-world scenarios, but cause state-of-the-art detection models to misclassify with high confidence. The mean average precision (mAP) of EfficientDet-D7 drops 74.5% when evaluated on NAO compared to the standard MSCOCO validation set. Moreover, by comparing a variety of object detection architectures, we find that better performance on MSCOCO validation set does not necessarily translate to better performance on NAO, suggesting that robustness cannot be simply achieved by training a more accurate model. We further investigate why examples in NAO are difficult to detect and classify. Experiments of shuffling image patches reveal that models are overly sensitive to local texture. Additionally, using integrated gradients and background replacement, we find that the detection model is reliant on pixel information within the bounding box, and insensitive to the background context when predicting class labels. NAO can be downloaded at https://drive.google.com/drive/folders/15P8sOWoJku6SSEiHLEts86ORfytGezi8.
On The State of Data In Computer Vision: Human Annotations Remain Indispensable for Developing Deep Learning Models
Jul 31, 2021High-quality labeled datasets play a crucial role in fueling the development of machine learning (ML), and in particular the development of deep learning (DL). However, since the emergence of the ImageNet dataset and the AlexNet model in 2012, the size of new open-source labeled vision datasets has remained roughly constant. Consequently, only a minority of publications in the computer vision community tackle supervised learning on datasets that are orders of magnitude larger than Imagenet. In this paper, we survey computer vision research domains that study the effects of such large datasets on model performance across different vision tasks. We summarize the community's current understanding of those effects, and highlight some open questions related to training with massive datasets. In particular, we tackle: (a) The largest datasets currently used in computer vision research and the interesting takeaways from training on such datasets; (b) The effectiveness of pre-training on large datasets; (c) Recent advancements and hurdles facing synthetic datasets; (d) An overview of double descent and sample non-monotonicity phenomena; and finally, (e) A brief discussion of lifelong/continual learning and how it fares compared to learning from huge labeled datasets in an offline setting. Overall, our findings are that research on optimization for deep learning focuses on perfecting the training routine and thus making DL models less data hungry, while research on synthetic datasets aims to offset the cost of data labeling. However, for the time being, acquiring non-synthetic labeled data remains indispensable to boost performance.