 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Adversarial Objects
Nov 07, 2021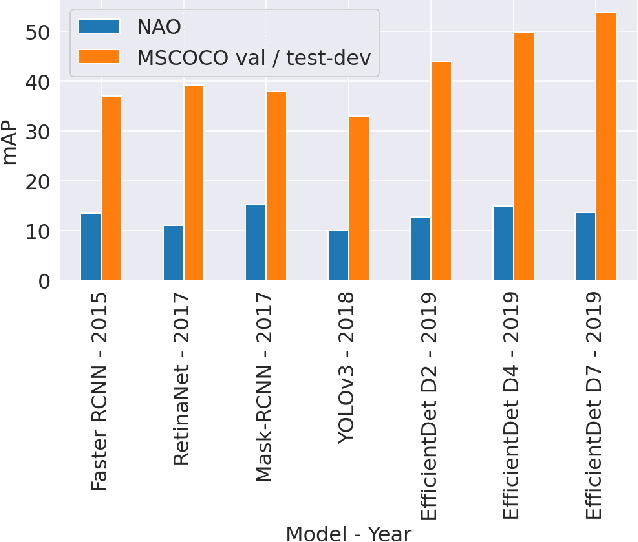


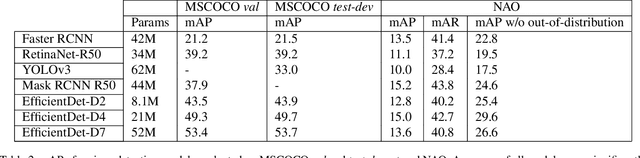
Although state-of-the-art object detection methods have shown compelling performance, models often are not robust to adversarial attacks and out-of-distribution data. We introduce a new dataset, Natural Adversarial Objects (NAO), to evaluate the robustness of object detection models. NAO contains 7,934 images and 9,943 objects that are unmodified and representative of real-world scenarios, but cause state-of-the-art detection models to misclassify with high confidence. The mean average precision (mAP) of EfficientDet-D7 drops 74.5% when evaluated on NAO compared to the standard MSCOCO validation set. Moreover, by comparing a variety of object detection architectures, we find that better performance on MSCOCO validation set does not necessarily translate to better performance on NAO, suggesting that robustness cannot be simply achieved by training a more accurate model. We further investigate why examples in NAO are difficult to detect and classify. Experiments of shuffling image patches reveal that models are overly sensitive to local texture. Additionally, using integrated gradients and background replacement, we find that the detection model is reliant on pixel information within the bounding box, and insensitive to the background context when predicting class labels. NAO can be downloaded at https://drive.google.com/drive/folders/15P8sOWoJku6SSEiHLEts86ORfytGezi8.
On The State of Data In Computer Vision: Human Annotations Remain Indispensable for Developing Deep Learning Models
Jul 31, 2021High-quality labeled datasets play a crucial role in fueling the development of machine learning (ML), and in particular the development of deep learning (DL). However, since the emergence of the ImageNet dataset and the AlexNet model in 2012, the size of new open-source labeled vision datasets has remained roughly constant. Consequently, only a minority of publications in the computer vision community tackle supervised learning on datasets that are orders of magnitude larger than Imagenet. In this paper, we survey computer vision research domains that study the effects of such large datasets on model performance across different vision tasks. We summarize the community's current understanding of those effects, and highlight some open questions related to training with massive datasets. In particular, we tackle: (a) The largest datasets currently used in computer vision research and the interesting takeaways from training on such datasets; (b) The effectiveness of pre-training on large datasets; (c) Recent advancements and hurdles facing synthetic datasets; (d) An overview of double descent and sample non-monotonicity phenomena; and finally, (e) A brief discussion of lifelong/continual learning and how it fares compared to learning from huge labeled datasets in an offline setting. Overall, our findings are that research on optimization for deep learning focuses on perfecting the training routine and thus making DL models less data hungry, while research on synthetic datasets aims to offset the cost of data labeling. However, for the time being, acquiring non-synthetic labeled data remains indispensable to boost performance.