 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Supervised Subspace Learning for Cross-modal Retrieval
Paper and Code
Jan 26, 2022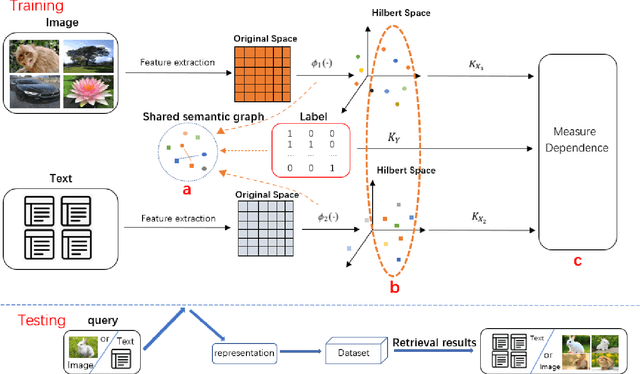
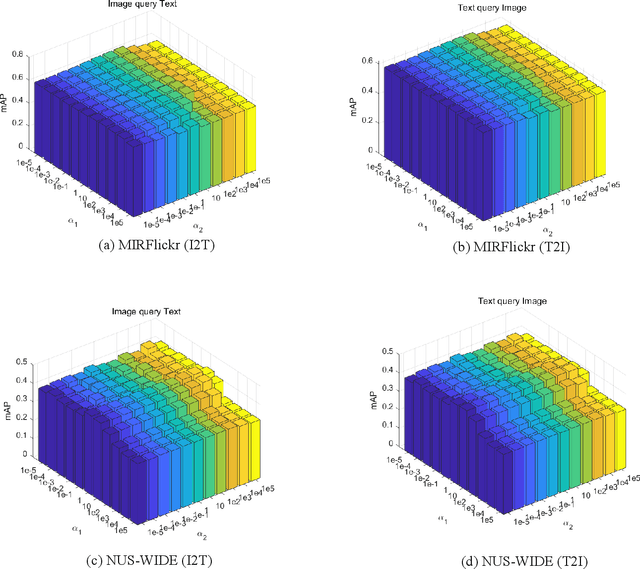
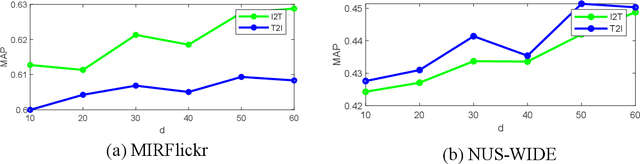
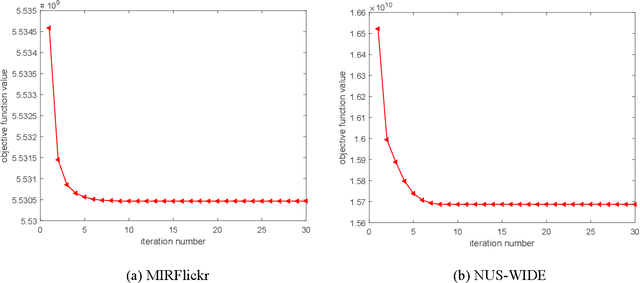
Nowadays the measure between heterogeneous data is still an open problem for cross-modal retrieval. The core of cross-modal retrieval is how to measure the similarity between different types of data. Many approaches have been developed to solve the problem. As one of the mainstream, approaches based on subspace learning pay attention to learning a common subspace where the similarity among multi-modal data can be measured directly. However, many of the existing approaches only focus on learning a latent subspace. They ignore the full use of discriminative information so that the semantically structural information is not well preserved. Therefore satisfactory results can not be achieved as expected. We in this paper propose a discriminative supervised subspace learning for cross-modal retrieval(DS2L), to make full use of discriminative information and better preserve the semantically structural information. Specifically, we first construct a shared semantic graph to preserve the semantic structure within each modality. Subsequently, the Hilbert-Schmidt Independence Criterion(HSIC) is introduced to preserve the consistence between feature-similarity and semantic-similarity of samples. Thirdly, we introduce a similarity preservation term, thus our model can compensate for the shortcomings of insufficient use of discriminative data and better preserve the semantically structural information within each modality. The experimental results obtained on three well-known benchmark datasets demonstrate the effectiveness and competitiveness of the proposed method against the compared classic subspace learning approaches.