 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Knowledge Graph Completion with GNN Distillation and Probabilistic Interaction Modeling
May 18, 2025Knowledge graphs (KGs) serve as fundamental structures for organizing interconnected data across diverse domains. However, most KGs remain incomplete, limiting their effectiveness in downstream applications. Knowledge graph completion (KGC) aims to address this issue by inferring missing links, but existing methods face critical challenges: deep graph neural networks (GNNs) suffer from over-smoothing, while embedding-based models fail to capture abstract relational features. This study aims to overcome these limitations by proposing a unified framework that integrates GNN distillation and abstract probabilistic interaction modeling (APIM). GNN distillation approach introduces an iterative message-feature filtering process to mitigate over-smoothing, preserving the discriminative power of node representations. APIM module complements this by learning structured, abstract interaction patterns through probabilistic signatures and transition matrices, allowing for a richer, more flexible representation of entity and relation interactions. We apply these methods to GNN-based models and the APIM to embedding-based KGC models, conducting extensive evaluations on the widely used WN18RR and FB15K-237 datasets. Our results demonstrate significant performance gains over baseline models, showcasing the effectiveness of the proposed techniques. The findings highlight the importance of both controlling information propagation and leveraging structured probabilistic modeling, offering new avenues for advancing knowledge graph completion. And our codes are available at https://anonymous.4open.science/r/APIM_and_GNN-Distillation-461C.
Discriminative Supervised Subspace Learning for Cross-modal Retrieval
Jan 26, 2022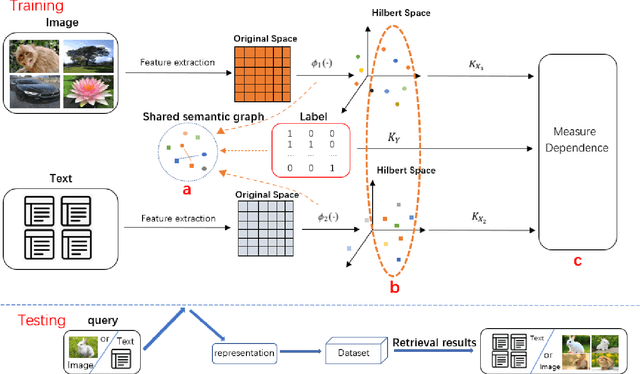
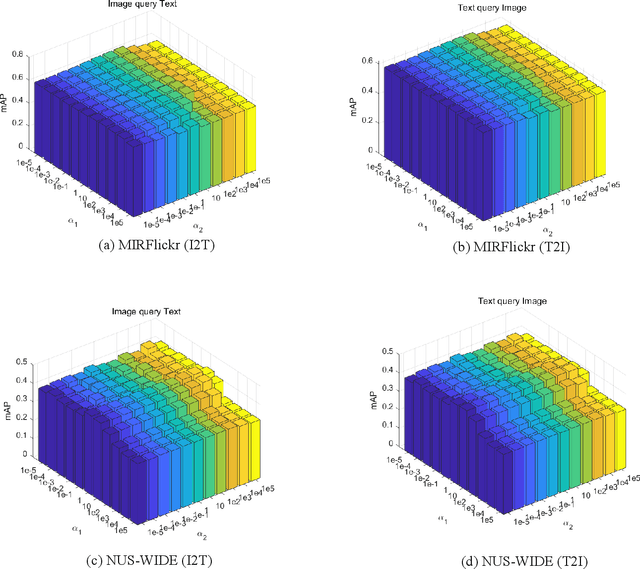
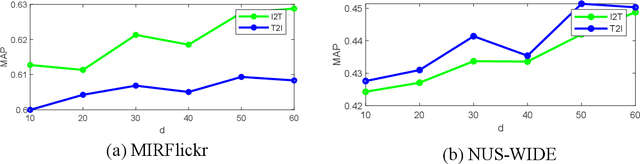
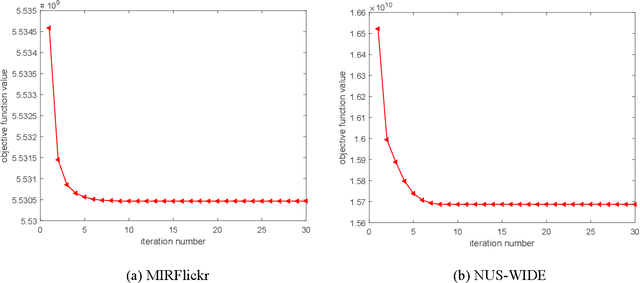
Nowadays the measure between heterogeneous data is still an open problem for cross-modal retrieval. The core of cross-modal retrieval is how to measure the similarity between different types of data. Many approaches have been developed to solve the problem. As one of the mainstream, approaches based on subspace learning pay attention to learning a common subspace where the similarity among multi-modal data can be measured directly. However, many of the existing approaches only focus on learning a latent subspace. They ignore the full use of discriminative information so that the semantically structural information is not well preserved. Therefore satisfactory results can not be achieved as expected. We in this paper propose a discriminative supervised subspace learning for cross-modal retrieval(DS2L), to make full use of discriminative information and better preserve the semantically structural information. Specifically, we first construct a shared semantic graph to preserve the semantic structure within each modality. Subsequently, the Hilbert-Schmidt Independence Criterion(HSIC) is introduced to preserve the consistence between feature-similarity and semantic-similarity of samples. Thirdly, we introduce a similarity preservation term, thus our model can compensate for the shortcomings of insufficient use of discriminative data and better preserve the semantically structural information within each modality. The experimental results obtained on three well-known benchmark datasets demonstrate the effectiveness and competitiveness of the proposed method against the compared classic subspace learning approaches.
MOON: Multi-Hash Codes Joint Learning for Cross-Media Retrieval
Aug 17, 2021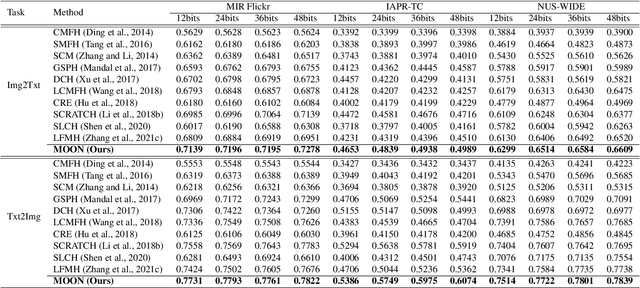
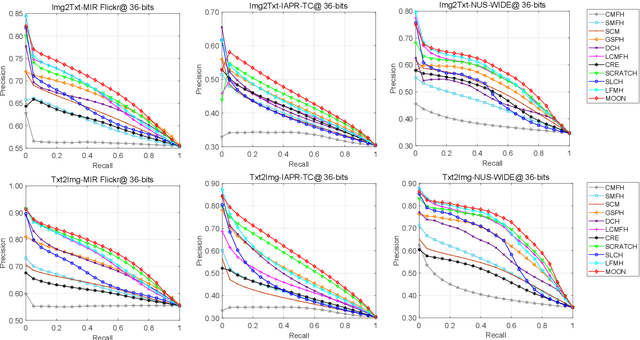
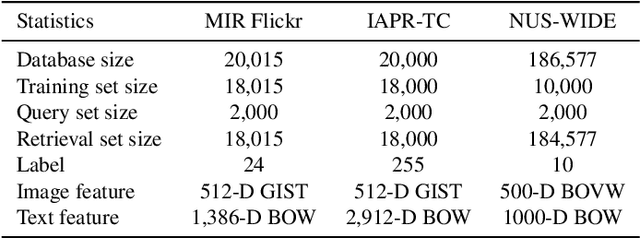
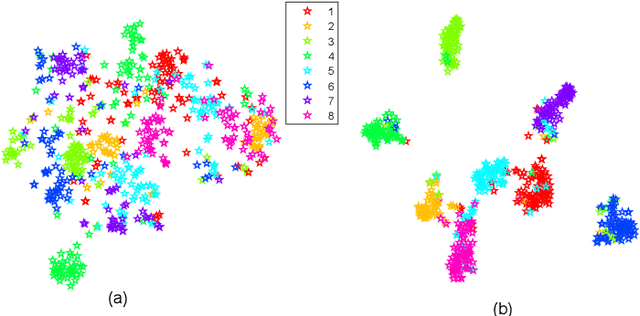
In recent years, cross-media hashing technique has attracted increasing attention for its high computation efficiency and low storage cost. However, the existing approaches still have some limitations, which need to be explored. 1) A fixed hash length (e.g., 16bits or 32bits) is predefined before learning the binary codes. Therefore, these models need to be retrained when the hash length changes, that consumes additional computation power, reducing the scalability in practical applications. 2) Existing cross-modal approaches only explore the information in the original multimedia data to perform the hash learning, without exploiting the semantic information contained in the learned hash codes. To this end, we develop a novel Multiple hash cOdes jOint learNing method (MOON) for cross-media retrieval. Specifically, the developed MOON synchronously learns the hash codes with multiple lengths in a unified framework. Besides, to enhance the underlying discrimination, we combine the clues from the multimodal data, semantic labels and learned hash codes for hash learning. As far as we know, the proposed MOON is the first work to simultaneously learn different length hash codes without retraining in cross-media retrieval. Experiments on several databases show that our MOON can achieve promising performance, outperforming some recent competitive shallow and deep methods.