 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
Jan 20, 2026Standard Vision-Language-Action (VLA) models typically fine-tune a monolithic Vision-Language Model (VLM) backbone explicitly for robotic control. However, this approach creates a critical tension between maintaining high-level general semantic understanding and learning low-level, fine-grained sensorimotor skills, often leading to "catastrophic forgetting" of the model's open-world capabilities. To resolve this conflict, we introduce TwinBrainVLA, a novel architecture that coordinates a generalist VLM retaining universal semantic understanding and a specialist VLM dedicated to embodied proprioception for joint robotic control. TwinBrainVLA synergizes a frozen "Left Brain", which retains robust general visual reasoning, with a trainable "Right Brain", specialized for embodied perception, via a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. This design allows the Right Brain to dynamically query semantic knowledge from the frozen Left Brain and fuse it with proprioceptive states, providing rich conditioning for a Flow-Matching Action Expert to generate precise continuous controls. Extensive experiments on SimplerEnv and RoboCasa benchmarks demonstrate that TwinBrainVLA achieves superior manipulation performance compared to state-of-the-art baselines while explicitly preserving the comprehensive visual understanding capabilities of the pre-trained VLM, offering a promising direction for building general-purpose robots that simultaneously achieve high-level semantic understanding and low-level physical dexterity.
Enhancing Knowledge Graph Completion with GNN Distillation and Probabilistic Interaction Modeling
May 18, 2025Knowledge graphs (KGs) serve as fundamental structures for organizing interconnected data across diverse domains. However, most KGs remain incomplete, limiting their effectiveness in downstream applications. Knowledge graph completion (KGC) aims to address this issue by inferring missing links, but existing methods face critical challenges: deep graph neural networks (GNNs) suffer from over-smoothing, while embedding-based models fail to capture abstract relational features. This study aims to overcome these limitations by proposing a unified framework that integrates GNN distillation and abstract probabilistic interaction modeling (APIM). GNN distillation approach introduces an iterative message-feature filtering process to mitigate over-smoothing, preserving the discriminative power of node representations. APIM module complements this by learning structured, abstract interaction patterns through probabilistic signatures and transition matrices, allowing for a richer, more flexible representation of entity and relation interactions. We apply these methods to GNN-based models and the APIM to embedding-based KGC models, conducting extensive evaluations on the widely used WN18RR and FB15K-237 datasets. Our results demonstrate significant performance gains over baseline models, showcasing the effectiveness of the proposed techniques. The findings highlight the importance of both controlling information propagation and leveraging structured probabilistic modeling, offering new avenues for advancing knowledge graph completion. And our codes are available at https://anonymous.4open.science/r/APIM_and_GNN-Distillation-461C.
Long-Short Chain-of-Thought Mixture Supervised Fine-Tuning Eliciting Efficient Reasoning in Large Language Models
May 06, 2025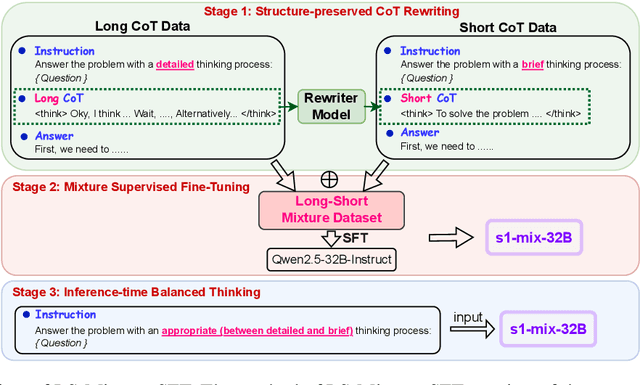
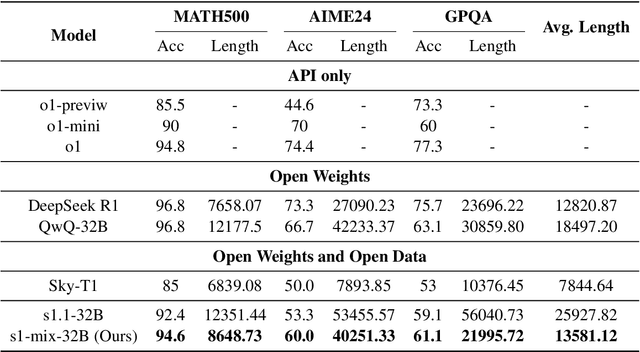
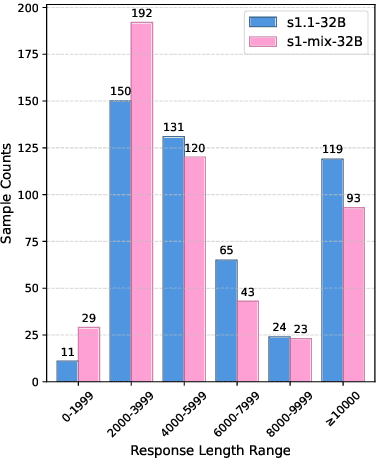
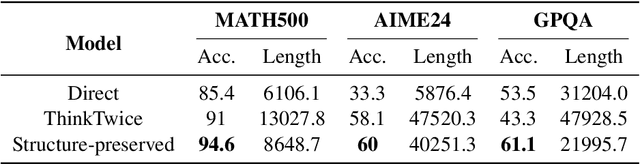
Recent advances in large language models have demonstrated that Supervised Fine-Tuning (SFT) with Chain-of-Thought (CoT) reasoning data distilled from large reasoning models (e.g., DeepSeek R1) can effectively transfer reasoning capabilities to non-reasoning models. However, models fine-tuned with this approach inherit the "overthinking" problem from teacher models, producing verbose and redundant reasoning chains during inference. To address this challenge, we propose \textbf{L}ong-\textbf{S}hort Chain-of-Thought \textbf{Mixture} \textbf{S}upervised \textbf{F}ine-\textbf{T}uning (\textbf{LS-Mixture SFT}), which combines long CoT reasoning dataset with their short counterparts obtained through structure-preserved rewriting. Our experiments demonstrate that models trained using the LS-Mixture SFT method, compared to those trained with direct SFT, achieved an average accuracy improvement of 2.3\% across various benchmarks while substantially reducing model response length by approximately 47.61\%. This work offers an approach to endow non-reasoning models with reasoning capabilities through supervised fine-tuning while avoiding the inherent overthinking problems inherited from teacher models, thereby enabling efficient reasoning in the fine-tuned models.
Deep Sparse Latent Feature Models for Knowledge Graph Completion
Nov 24, 2024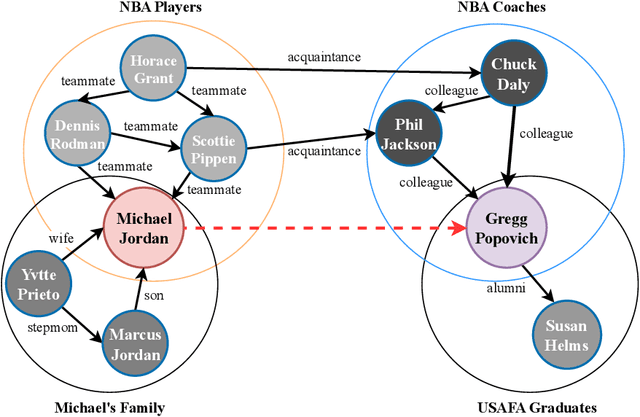

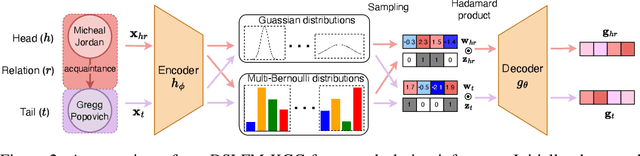

Recent progress in knowledge graph completion (KGC) has focused on text-based approaches to address the challenges of large-scale knowledge graphs (KGs). Despite their achievements, these methods often overlook the intricate interconnections between entities, a key aspect of the underlying topological structure of a KG. Stochastic blockmodels (SBMs), particularly the latent feature relational model (LFRM), offer robust probabilistic frameworks that can dynamically capture latent community structures and enhance link prediction. In this paper, we introduce a novel framework of sparse latent feature models for KGC, optimized through a deep variational autoencoder (VAE). Our approach not only effectively completes missing triples but also provides clear interpretability of the latent structures, leveraging textual information. Comprehensive experiments on the WN18RR, FB15k-237, and Wikidata5M datasets show that our method significantly improves performance by revealing latent communities and producing interpretable representations.
KERMIT: Knowledge Graph Completion of Enhanced Relation Modeling with Inverse Transformation
Sep 26, 2023



Knowledge graph completion is a task that revolves around filling in missing triples based on the information available in a knowledge graph. Among the current studies, text-based methods complete the task by utilizing textual descriptions of triples. However, this modeling approach may encounter limitations, particularly when the description fails to accurately and adequately express the intended meaning. To overcome these challenges, we propose the augmentation of data through two additional mechanisms. Firstly, we employ ChatGPT as an external knowledge base to generate coherent descriptions to bridge the semantic gap between the queries and answers. Secondly, we leverage inverse relations to create a symmetric graph, thereby creating extra labeling and providing supplementary information for link prediction. This approach offers additional insights into the relationships between entities. Through these efforts, we have observed significant improvements in knowledge graph completion, as these mechanisms enhance the richness and diversity of the available data, leading to more accurate results.
DegreEmbed: incorporating entity embedding into logic rule learning for knowledge graph reasoning
Dec 18, 2021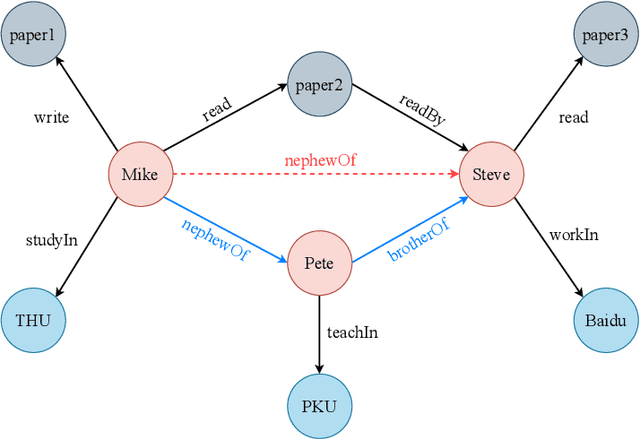
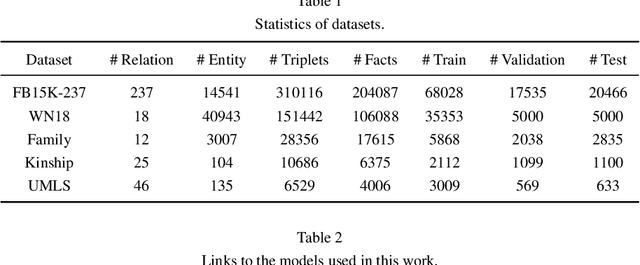
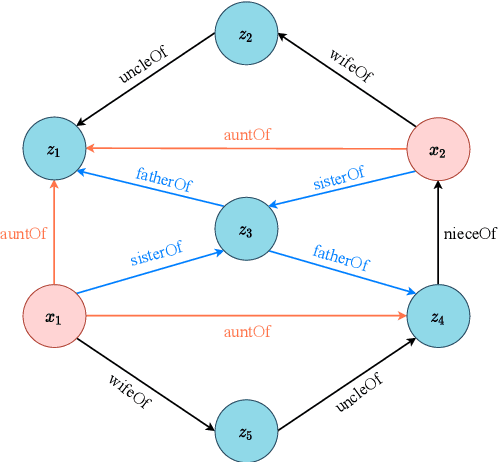

Knowledge graphs (KGs), as structured representations of real world facts, are intelligent databases incorporating human knowledge that can help machine imitate the way of human problem solving. However, due to the nature of rapid iteration as well as incompleteness of data, KGs are usually huge and there are inevitably missing facts in KGs. Link prediction for knowledge graphs is the task aiming to complete missing facts by reasoning based on the existing knowledge. Two main streams of research are widely studied: one learns low-dimensional embeddings for entities and relations that can capture latent patterns, and the other gains good interpretability by mining logical rules. Unfortunately, previous studies rarely pay attention to heterogeneous KGs. In this paper, we propose DegreEmbed, a model that combines embedding-based learning and logic rule mining for inferring on KGs. Specifically, we study the problem of predicting missing links in heterogeneous KGs that involve entities and relations of various types from the perspective of the degrees of nodes. Experimentally, we demonstrate that our DegreEmbed model outperforms the state-of-the-art methods on real world datasets. Meanwhile, the rules mined by our model are of high quality and interpretability.
MPLR: a novel model for multi-target learning of logical rules for knowledge graph reasoning
Dec 12, 2021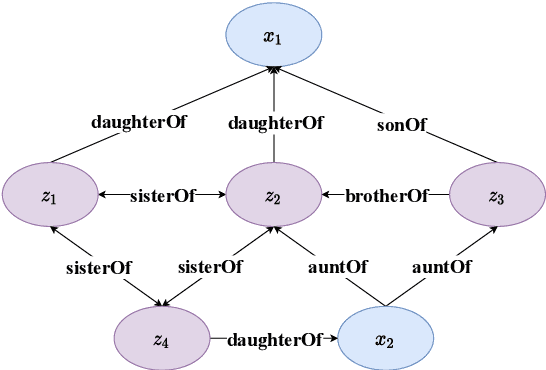


Large-scale knowledge graphs (KGs) provide structured representations of human knowledge. However, as it is impossible to contain all knowledge, KGs are usually incomplete. Reasoning based on existing facts paves a way to discover missing facts. In this paper, we study the problem of learning logic rules for reasoning on knowledge graphs for completing missing factual triplets. Learning logic rules equips a model with strong interpretability as well as the ability to generalize to similar tasks. We propose a model called MPLR that improves the existing models to fully use training data and multi-target scenarios are considered. In addition, considering the deficiency in evaluating the performance of models and the quality of mined rules, we further propose two novel indicators to help with the problem. Experimental results empirically demonstrate that our MPLR model outperforms state-of-the-art methods on five benchmark datasets. The results also prove the effectiveness of the indicators.