 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
Jan 20, 2026Standard Vision-Language-Action (VLA) models typically fine-tune a monolithic Vision-Language Model (VLM) backbone explicitly for robotic control. However, this approach creates a critical tension between maintaining high-level general semantic understanding and learning low-level, fine-grained sensorimotor skills, often leading to "catastrophic forgetting" of the model's open-world capabilities. To resolve this conflict, we introduce TwinBrainVLA, a novel architecture that coordinates a generalist VLM retaining universal semantic understanding and a specialist VLM dedicated to embodied proprioception for joint robotic control. TwinBrainVLA synergizes a frozen "Left Brain", which retains robust general visual reasoning, with a trainable "Right Brain", specialized for embodied perception, via a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. This design allows the Right Brain to dynamically query semantic knowledge from the frozen Left Brain and fuse it with proprioceptive states, providing rich conditioning for a Flow-Matching Action Expert to generate precise continuous controls. Extensive experiments on SimplerEnv and RoboCasa benchmarks demonstrate that TwinBrainVLA achieves superior manipulation performance compared to state-of-the-art baselines while explicitly preserving the comprehensive visual understanding capabilities of the pre-trained VLM, offering a promising direction for building general-purpose robots that simultaneously achieve high-level semantic understanding and low-level physical dexterity.
Information-Dense Reasoning for Efficient and Auditable Security Alert Triage
Dec 09, 2025Security Operations Centers face massive, heterogeneous alert streams under minute-level service windows, creating the Alert Triage Latency Paradox: verbose reasoning chains ensure accuracy and compliance but incur prohibitive latency and token costs, while minimal chains sacrifice transparency and auditability. Existing solutions fail: signature systems are brittle, anomaly methods lack actionability, and fully cloud-hosted LLMs raise latency, cost, and privacy concerns. We propose AIDR, a hybrid cloud-edge framework that addresses this trade-off through constrained information-density optimization. The core innovation is gradient-based compression of reasoning chains to retain only decision-critical steps--minimal evidence sufficient to justify predictions while respecting token and latency budgets. We demonstrate that this approach preserves decision-relevant information while minimizing complexity. We construct compact datasets by distilling alerts into 3-5 high-information bullets (68% token reduction), train domain-specialized experts via LoRA, and deploy a cloud-edge architecture: a cloud LLM routes alerts to on-premises experts generating SOAR-ready JSON. Experiments demonstrate AIDR achieves higher accuracy and 40.6% latency reduction versus Chain-of-Thought, with robustness to data corruption and out-of-distribution generalization, enabling auditable and efficient SOC triage with full data residency compliance.
Long-Short Chain-of-Thought Mixture Supervised Fine-Tuning Eliciting Efficient Reasoning in Large Language Models
May 06, 2025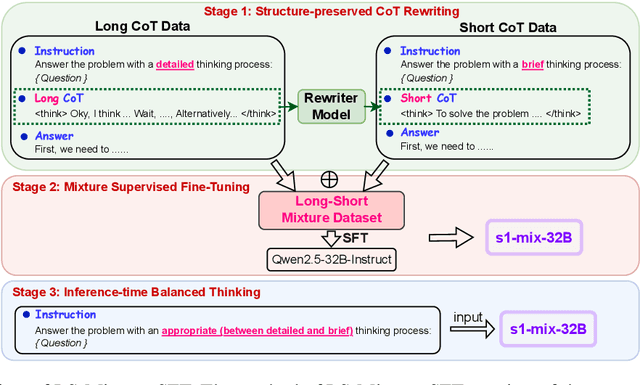
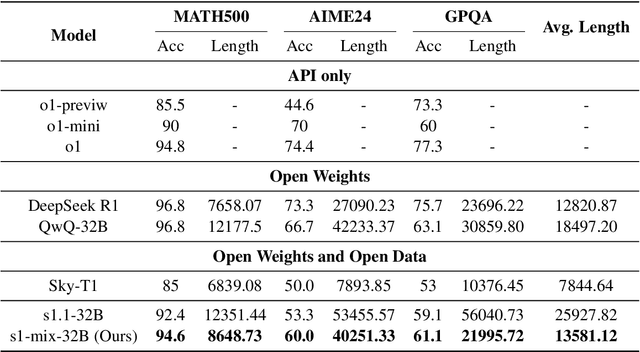
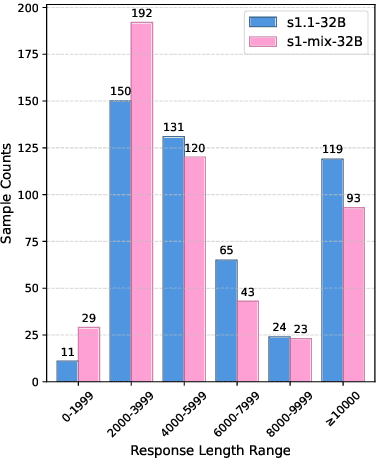
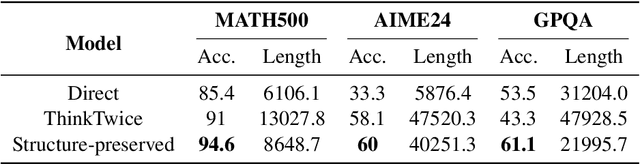
Recent advances in large language models have demonstrated that Supervised Fine-Tuning (SFT) with Chain-of-Thought (CoT) reasoning data distilled from large reasoning models (e.g., DeepSeek R1) can effectively transfer reasoning capabilities to non-reasoning models. However, models fine-tuned with this approach inherit the "overthinking" problem from teacher models, producing verbose and redundant reasoning chains during inference. To address this challenge, we propose \textbf{L}ong-\textbf{S}hort Chain-of-Thought \textbf{Mixture} \textbf{S}upervised \textbf{F}ine-\textbf{T}uning (\textbf{LS-Mixture SFT}), which combines long CoT reasoning dataset with their short counterparts obtained through structure-preserved rewriting. Our experiments demonstrate that models trained using the LS-Mixture SFT method, compared to those trained with direct SFT, achieved an average accuracy improvement of 2.3\% across various benchmarks while substantially reducing model response length by approximately 47.61\%. This work offers an approach to endow non-reasoning models with reasoning capabilities through supervised fine-tuning while avoiding the inherent overthinking problems inherited from teacher models, thereby enabling efficient reasoning in the fine-tuned models.
Deep Sparse Latent Feature Models for Knowledge Graph Completion
Nov 24, 2024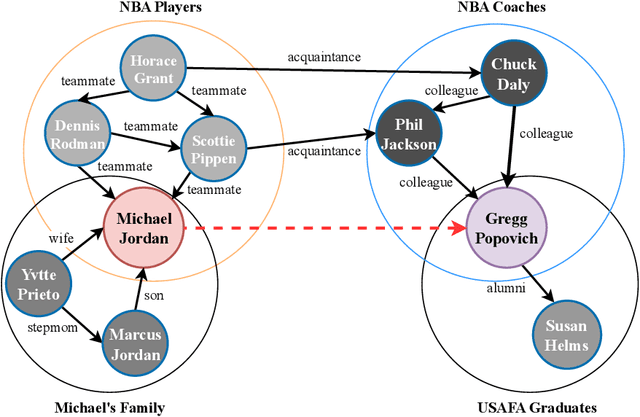

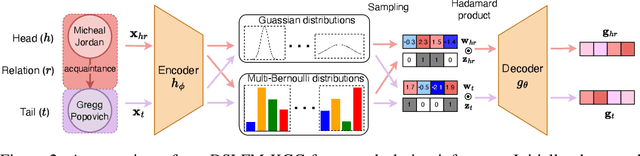

Recent progress in knowledge graph completion (KGC) has focused on text-based approaches to address the challenges of large-scale knowledge graphs (KGs). Despite their achievements, these methods often overlook the intricate interconnections between entities, a key aspect of the underlying topological structure of a KG. Stochastic blockmodels (SBMs), particularly the latent feature relational model (LFRM), offer robust probabilistic frameworks that can dynamically capture latent community structures and enhance link prediction. In this paper, we introduce a novel framework of sparse latent feature models for KGC, optimized through a deep variational autoencoder (VAE). Our approach not only effectively completes missing triples but also provides clear interpretability of the latent structures, leveraging textual information. Comprehensive experiments on the WN18RR, FB15k-237, and Wikidata5M datasets show that our method significantly improves performance by revealing latent communities and producing interpretable representations.
LiPar: A Lightweight Parallel Learning Model for Practical In-Vehicle Network Intrusion Detection
Nov 14, 2023



With the development of intelligent transportation systems, vehicles are exposed to a complex network environment. As the main network of in-vehicle networks, the controller area network (CAN) has many potential security hazards, resulting in higher requirements for intrusion detection systems to ensure safety. Among intrusion detection technologies, methods based on deep learning work best without prior expert knowledge. However, they all have a large model size and rely on cloud computing, and are therefore not suitable to be installed on the in-vehicle network. Therefore, we propose a lightweight parallel neural network structure, LiPar, to allocate task loads to multiple electronic control units (ECU). The LiPar model consists of multi-dimensional branch convolution networks, spatial and temporal feature fusion learning, and a resource adaptation algorithm. Through experiments, we prove that LiPar has great detection performance, running efficiency, and lightweight model size, which can be well adapted to the in-vehicle environment practically and protect the in-vehicle CAN bus security.
Effective In-vehicle Intrusion Detection via Multi-view Statistical Graph Learning on CAN Messages
Nov 13, 2023



As an important component of internet of vehicles (IoV), intelligent connected vehicles (ICVs) have to communicate with external networks frequently. In this case, the resource-constrained in-vehicle network (IVN) is facing a wide variety of complex and changing external cyber-attacks, especially the masquerade attack with high difficulty of detection while serious damaging effects that few counter measures can identify successfully. Moreover, only coarse-grained recognition can be achieved in current mainstream intrusion detection mechanisms, i.e., whether a whole data flow observation window contains attack labels rather than fine-grained recognition on every single data item within this window. In this paper, we propose StatGraph: an Effective Multi-view Statistical Graph Learning Intrusion Detection to implement the fine-grained intrusion detection. Specifically, StatGraph generates two statistical graphs, timing correlation graph (TCG) and coupling relationship graph (CRG), based on data streams. In given message observation windows, edge attributes in TCGs represent temporal correlation between different message IDs, while edge attributes in CRGs denote the neighbour relationship and contextual similarity. Besides, a lightweight shallow layered GCN network is trained based graph property of TCGs and CRGs, which can learn the universal laws of various patterns more effectively and further enhance the performance of detection. To address the problem of insufficient attack types in previous intrusion detection, we select two real in-vehicle CAN datasets that cover four new attacks never investigated before. Experimental result shows StatGraph improves both detection granularity and detection performance over state-of-the-art intrusion detection methods.
KERMIT: Knowledge Graph Completion of Enhanced Relation Modeling with Inverse Transformation
Sep 26, 2023



Knowledge graph completion is a task that revolves around filling in missing triples based on the information available in a knowledge graph. Among the current studies, text-based methods complete the task by utilizing textual descriptions of triples. However, this modeling approach may encounter limitations, particularly when the description fails to accurately and adequately express the intended meaning. To overcome these challenges, we propose the augmentation of data through two additional mechanisms. Firstly, we employ ChatGPT as an external knowledge base to generate coherent descriptions to bridge the semantic gap between the queries and answers. Secondly, we leverage inverse relations to create a symmetric graph, thereby creating extra labeling and providing supplementary information for link prediction. This approach offers additional insights into the relationships between entities. Through these efforts, we have observed significant improvements in knowledge graph completion, as these mechanisms enhance the richness and diversity of the available data, leading to more accurate results.
MPLR: a novel model for multi-target learning of logical rules for knowledge graph reasoning
Dec 12, 2021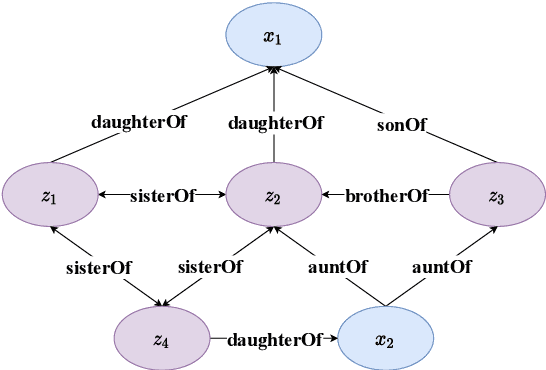
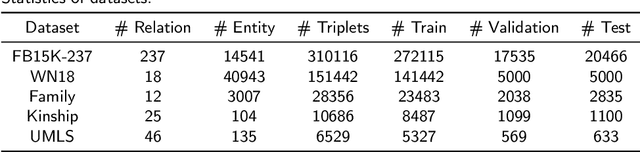


Large-scale knowledge graphs (KGs) provide structured representations of human knowledge. However, as it is impossible to contain all knowledge, KGs are usually incomplete. Reasoning based on existing facts paves a way to discover missing facts. In this paper, we study the problem of learning logic rules for reasoning on knowledge graphs for completing missing factual triplets. Learning logic rules equips a model with strong interpretability as well as the ability to generalize to similar tasks. We propose a model called MPLR that improves the existing models to fully use training data and multi-target scenarios are considered. In addition, considering the deficiency in evaluating the performance of models and the quality of mined rules, we further propose two novel indicators to help with the problem. Experimental results empirically demonstrate that our MPLR model outperforms state-of-the-art methods on five benchmark datasets. The results also prove the effectiveness of the indicators.
Verification Code Recognition Based on Active and Deep Learning
Feb 12, 2019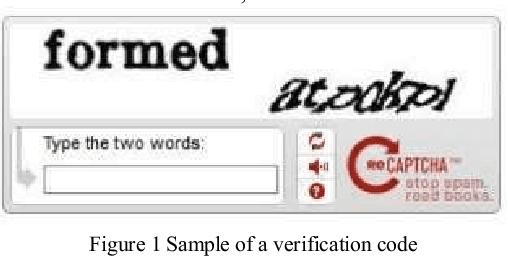
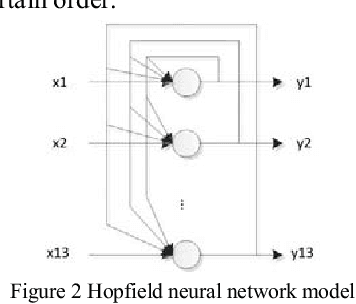
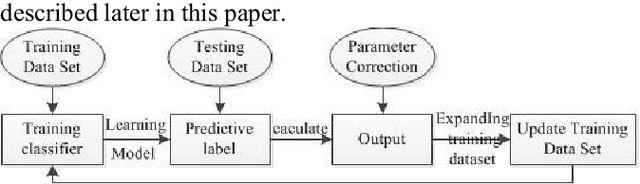
A verification code is an automated test method used to distinguish between humans and computers. Humans can easily identify verification codes, whereas machines cannot. With the development of convolutional neural networks, automatically recognizing a verification code is now possible for machines. However, the advantages of convolutional neural networks depend on the data used by the training classifier, particularly the size of the training set. Therefore, identifying a verification code using a convolutional neural network is difficult when training data are insufficient. This study proposes an active and deep learning strategy to obtain new training data on a special verification code set without manual intervention. A feature learning model for a scene with less training data is presented in this work, and the verification code is identified by the designed convolutional neural network. Experiments show that the method can considerably improve the recognition accuracy of a neural network when the amount of initial training data is small.