 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigeNet: A Highly Efficient Modeling for Long Sequence Time Series Prediction in AIOps
Nov 13, 2022



Modern IT system operation demands the integration of system software and hardware metrics. As a result, it generates a massive amount of data, which can be potentially used to make data-driven operational decisions. In the basic form, the decision model needs to monitor a large set of machine data, such as CPU utilization, allocated memory, disk and network latency, and predicts the system metrics to prevent performance degradation. Nevertheless, building an effective prediction model in this scenario is rather challenging as the model has to accurately capture the long-range coupling dependency in the Multivariate Time-Series (MTS). Moreover, this model needs to have low computational complexity and can scale efficiently to the dimension of data available. In this paper, we propose a highly efficient model named HigeNet to predict the long-time sequence time series. We have deployed the HigeNet on production in the D-matrix platform. We also provide offline evaluations on several publicly available datasets as well as one online dataset to demonstrate the model's efficacy. The extensive experiments show that training time, resource usage and accuracy of the model are found to be significantly better than five state-of-the-art competing models.
Analytical SLAM Without Linearization
Dec 29, 2016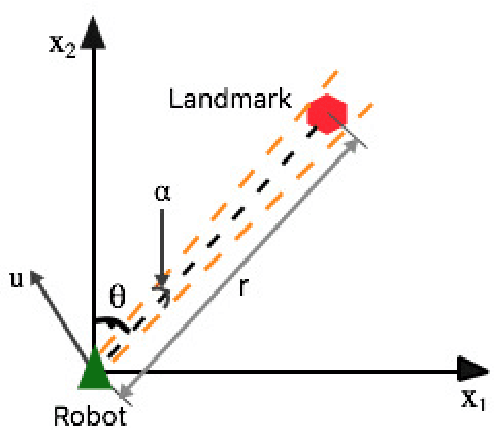
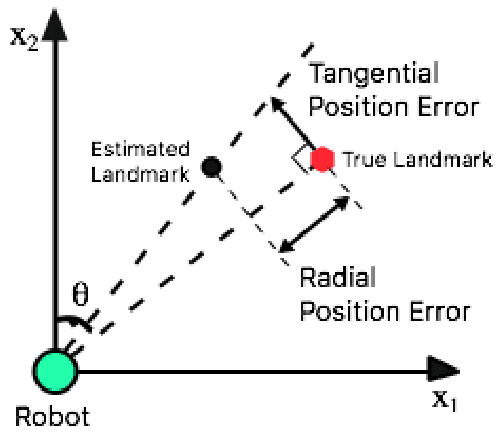
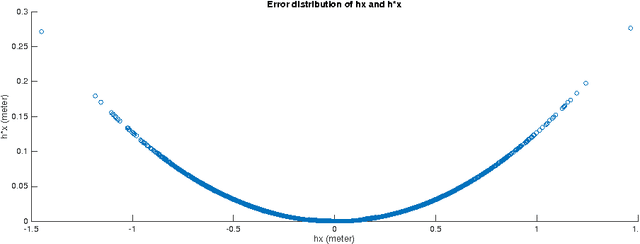
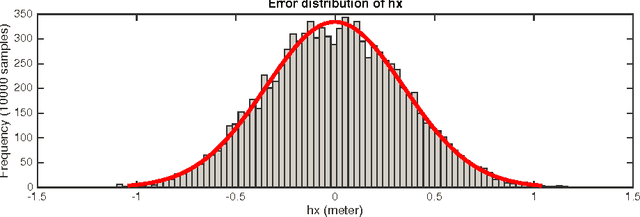
This paper solves the classical problem of simultaneous localization and mapping (SLAM) in a fashion which avoids linearized approximations altogether. Based on creating virtual synthetic measurements, the algorithm uses a linear time- varying (LTV) Kalman observer, bypassing errors and approximations brought by the linearization process in traditional extended Kalman filtering (EKF) SLAM. Convergence rates of the algorithm are established using contraction analysis. Different combinations of sensor information can be exploited, such as bearing measurements, range measurements, optical flow, or time-to-contact. As illustrated in simulations, the proposed algorithm can solve SLAM problems in both 2D and 3D scenarios with guaranteed convergence rates in a full nonlinear context.
A Quorum Sensing Inspired Algorithm for Dynamic Clustering
Oct 06, 2015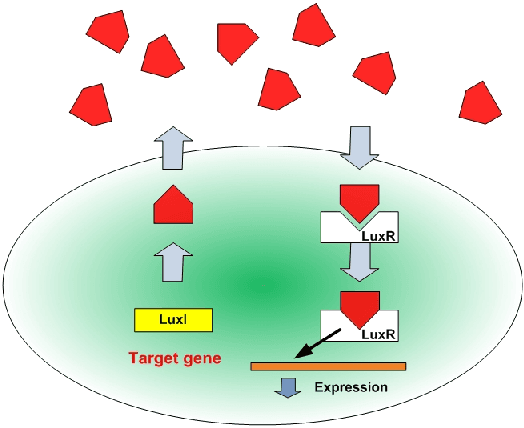
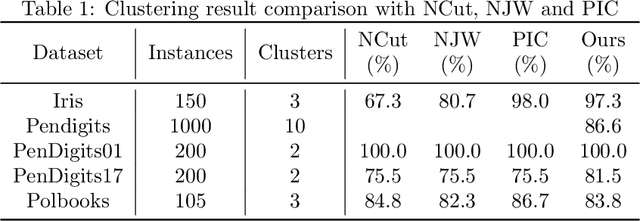
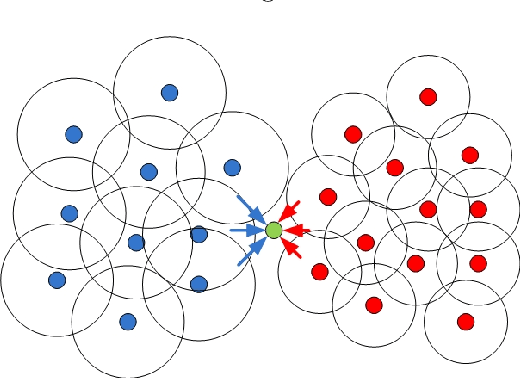

Quorum sensing is a decentralized biological process, through which a community of cells with no global awareness coordinate their functional behaviors based solely on cell-medium interactions and local decisions. This paper draws inspirations from quorum sensing and colony competition to derive a new algorithm for data clustering. The algorithm treats each data as a single cell, and uses knowledge of local connectivity to cluster cells into multiple colonies simultaneously. It simulates auto-inducers secretion in quorum sensing to tune the influence radius for each cell. At the same time, sparsely distributed core cells spread their influences to form colonies, and interactions between colonies eventually determine each cell's identity. The algorithm has the flexibility to analyze not only static but also time-varying data, which surpasses the capacity of many existing algorithms. Its stability and convergence properties are established. The algorithm is tested on several applications, including both synthetic and real benchmarks data sets, alleles clustering, community detection, image segmentation. In particular, the algorithm's distinctive capability to deal with time-varying data allows us to experiment it on novel applications such as robotic swarms grouping and switching model identification. We believe that the algorithm's promising performance would stimulate many more exciting applications.