 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigeNet: A Highly Efficient Modeling for Long Sequence Time Series Prediction in AIOps
Nov 13, 2022



Modern IT system operation demands the integration of system software and hardware metrics. As a result, it generates a massive amount of data, which can be potentially used to make data-driven operational decisions. In the basic form, the decision model needs to monitor a large set of machine data, such as CPU utilization, allocated memory, disk and network latency, and predicts the system metrics to prevent performance degradation. Nevertheless, building an effective prediction model in this scenario is rather challenging as the model has to accurately capture the long-range coupling dependency in the Multivariate Time-Series (MTS). Moreover, this model needs to have low computational complexity and can scale efficiently to the dimension of data available. In this paper, we propose a highly efficient model named HigeNet to predict the long-time sequence time series. We have deployed the HigeNet on production in the D-matrix platform. We also provide offline evaluations on several publicly available datasets as well as one online dataset to demonstrate the model's efficacy. The extensive experiments show that training time, resource usage and accuracy of the model are found to be significantly better than five state-of-the-art competing models.
Diversifying Dialogue Generation with Non-Conversational Text
May 13, 2020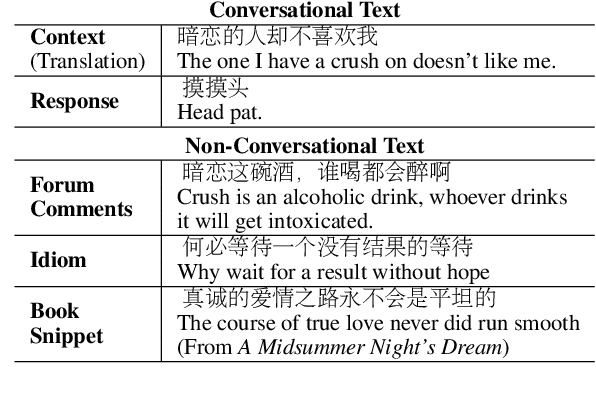
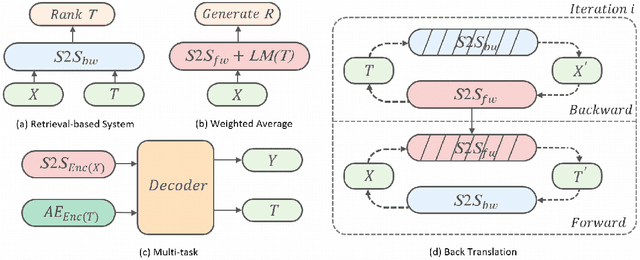
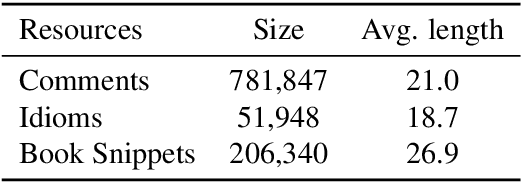
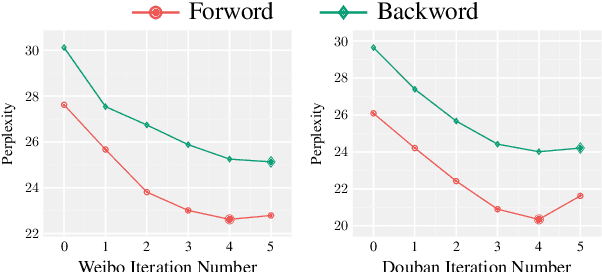
Neural network-based sequence-to-sequence (seq2seq) models strongly suffer from the low-diversity problem when it comes to open-domain dialogue generation. As bland and generic utterances usually dominate the frequency distribution in our daily chitchat, avoiding them to generate more interesting responses requires complex data filtering, sampling techniques or modifying the training objective. In this paper, we propose a new perspective to diversify dialogue generation by leveraging non-conversational text. Compared with bilateral conversations, non-conversational text are easier to obtain, more diverse and cover a much broader range of topics. We collect a large-scale non-conversational corpus from multi sources including forum comments, idioms and book snippets. We further present a training paradigm to effectively incorporate these text via iterative back translation. The resulting model is tested on two conversational datasets and is shown to produce significantly more diverse responses without sacrificing the relevance with context.
Improving Multi-turn Dialogue Modelling with Utterance ReWriter
Jun 14, 2019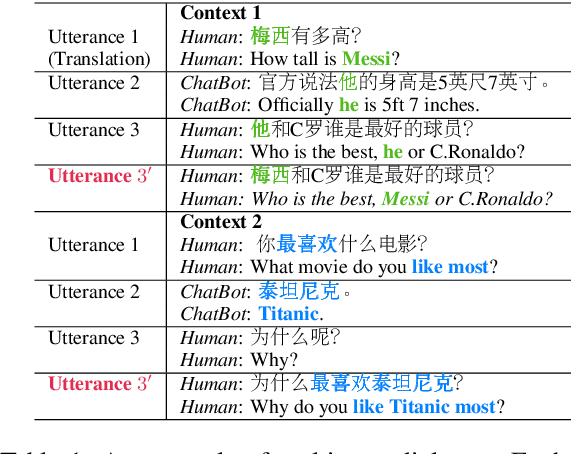
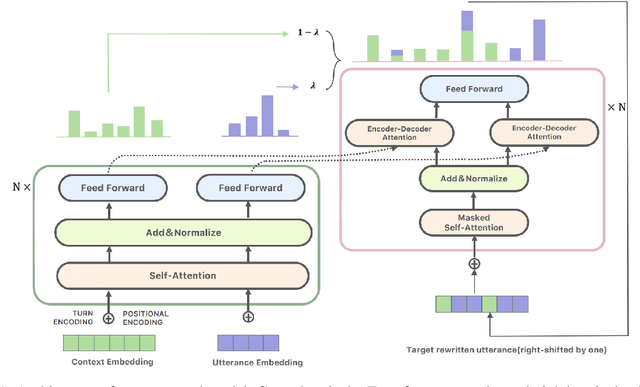
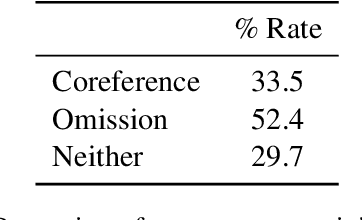
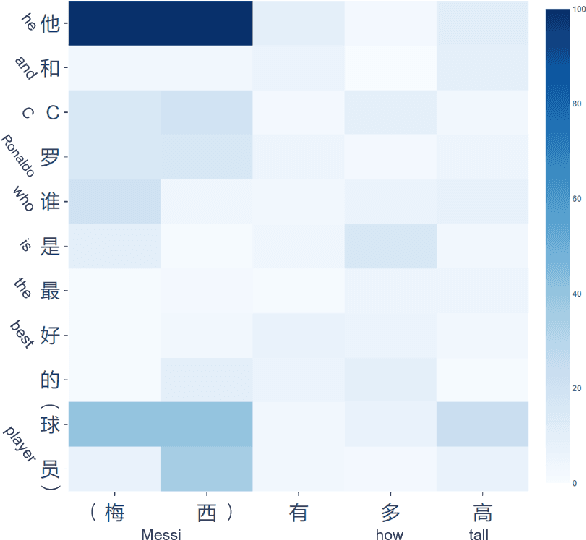
Recent research has made impressive progress in single-turn dialogue modelling. In the multi-turn setting, however, current models are still far from satisfactory. One major challenge is the frequently occurred coreference and information omission in our daily conversation, making it hard for machines to understand the real intention. In this paper, we propose rewriting the human utterance as a pre-process to help multi-turn dialgoue modelling. Each utterance is first rewritten to recover all coreferred and omitted information. The next processing steps are then performed based on the rewritten utterance. To properly train the utterance rewriter, we collect a new dataset with human annotations and introduce a Transformer-based utterance rewriting architecture using the pointer network. We show the proposed architecture achieves remarkably good performance on the utterance rewriting task. The trained utterance rewriter can be easily integrated into online chatbots and brings general improvement over different domains.