 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute-Optimal Scaling for Value-Based Deep RL
Aug 20, 2025As models grow larger and training them becomes expensive, it becomes increasingly important to scale training recipes not just to larger models and more data, but to do so in a compute-optimal manner that extracts maximal performance per unit of compute. While such scaling has been well studied for language modeling, reinforcement learning (RL) has received less attention in this regard. In this paper, we investigate compute scaling for online, value-based deep RL. These methods present two primary axes for compute allocation: model capacity and the update-to-data (UTD) ratio. Given a fixed compute budget, we ask: how should resources be partitioned across these axes to maximize sample efficiency? Our analysis reveals a nuanced interplay between model size, batch size, and UTD. In particular, we identify a phenomenon we call TD-overfitting: increasing the batch quickly harms Q-function accuracy for small models, but this effect is absent in large models, enabling effective use of large batch size at scale. We provide a mental model for understanding this phenomenon and build guidelines for choosing batch size and UTD to optimize compute usage. Our findings provide a grounded starting point for compute-optimal scaling in deep RL, mirroring studies in supervised learning but adapted to TD learning.
Latent Diffusion Planning for Imitation Learning
Apr 23, 2025Recent progress in imitation learning has been enabled by policy architectures that scale to complex visuomotor tasks, multimodal distributions, and large datasets. However, these methods often rely on learning from large amount of expert demonstrations. To address these shortcomings, we propose Latent Diffusion Planning (LDP), a modular approach consisting of a planner which can leverage action-free demonstrations, and an inverse dynamics model which can leverage suboptimal data, that both operate over a learned latent space. First, we learn a compact latent space through a variational autoencoder, enabling effective forecasting of future states in image-based domains. Then, we train a planner and an inverse dynamics model with diffusion objectives. By separating planning from action prediction, LDP can benefit from the denser supervision signals of suboptimal and action-free data. On simulated visual robotic manipulation tasks, LDP outperforms state-of-the-art imitation learning approaches, as they cannot leverage such additional data.
Value-Based Deep RL Scales Predictably
Feb 06, 2025Scaling data and compute is critical to the success of machine learning. However, scaling demands predictability: we want methods to not only perform well with more compute or data, but also have their performance be predictable from small-scale runs, without running the large-scale experiment. In this paper, we show that value-based off-policy RL methods are predictable despite community lore regarding their pathological behavior. First, we show that data and compute requirements to attain a given performance level lie on a Pareto frontier, controlled by the updates-to-data (UTD) ratio. By estimating this frontier, we can predict this data requirement when given more compute, and this compute requirement when given more data. Second, we determine the optimal allocation of a total resource budget across data and compute for a given performance and use it to determine hyperparameters that maximize performance for a given budget. Third, this scaling behavior is enabled by first estimating predictable relationships between hyperparameters, which is used to manage effects of overfitting and plasticity loss unique to RL. We validate our approach using three algorithms: SAC, BRO, and PQL on DeepMind Control, OpenAI gym, and IsaacGym, when extrapolating to higher levels of data, compute, budget, or performance.
Privileged Sensing Scaffolds Reinforcement Learning
May 23, 2024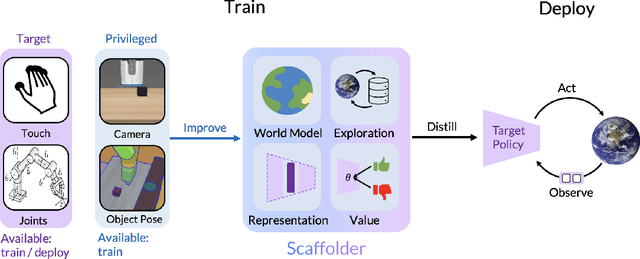
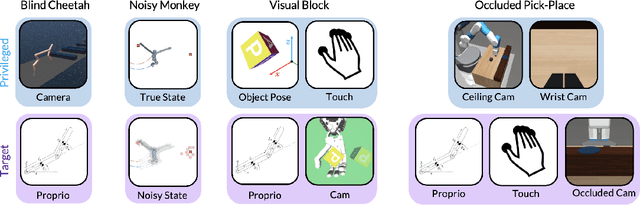
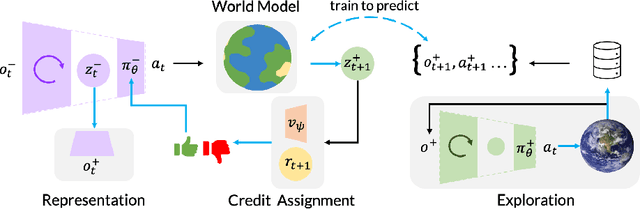

We need to look at our shoelaces as we first learn to tie them but having mastered this skill, can do it from touch alone. We call this phenomenon "sensory scaffolding": observation streams that are not needed by a master might yet aid a novice learner. We consider such sensory scaffolding setups for training artificial agents. For example, a robot arm may need to be deployed with just a low-cost, robust, general-purpose camera; yet its performance may improve by having privileged training-time-only access to informative albeit expensive and unwieldy motion capture rigs or fragile tactile sensors. For these settings, we propose "Scaffolder", a reinforcement learning approach which effectively exploits privileged sensing in critics, world models, reward estimators, and other such auxiliary components that are only used at training time, to improve the target policy. For evaluating sensory scaffolding agents, we design a new "S3" suite of ten diverse simulated robotic tasks that explore a wide range of practical sensor setups. Agents must use privileged camera sensing to train blind hurdlers, privileged active visual perception to help robot arms overcome visual occlusions, privileged touch sensors to train robot hands, and more. Scaffolder easily outperforms relevant prior baselines and frequently performs comparably even to policies that have test-time access to the privileged sensors. Website: https://penn-pal-lab.github.io/scaffolder/
METRA: Scalable Unsupervised RL with Metric-Aware Abstraction
Oct 13, 2023Unsupervised pre-training strategies have proven to be highly effective in natural language processing and computer vision. Likewise, unsupervised reinforcement learning (RL) holds the promise of discovering a variety of potentially useful behaviors that can accelerate the learning of a wide array of downstream tasks. Previous unsupervised RL approaches have mainly focused on pure exploration and mutual information skill learning. However, despite the previous attempts, making unsupervised RL truly scalable still remains a major open challenge: pure exploration approaches might struggle in complex environments with large state spaces, where covering every possible transition is infeasible, and mutual information skill learning approaches might completely fail to explore the environment due to the lack of incentives. To make unsupervised RL scalable to complex, high-dimensional environments, we propose a novel unsupervised RL objective, which we call Metric-Aware Abstraction (METRA). Our main idea is, instead of directly covering the entire state space, to only cover a compact latent space $Z$ that is metrically connected to the state space $S$ by temporal distances. By learning to move in every direction in the latent space, METRA obtains a tractable set of diverse behaviors that approximately cover the state space, being scalable to high-dimensional environments. Through our experiments in five locomotion and manipulation environments, we demonstrate that METRA can discover a variety of useful behaviors even in complex, pixel-based environments, being the first unsupervised RL method that discovers diverse locomotion behaviors in pixel-based Quadruped and Humanoid. Our code and videos are available at https://seohong.me/projects/metra/
Planning Goals for Exploration
Mar 23, 2023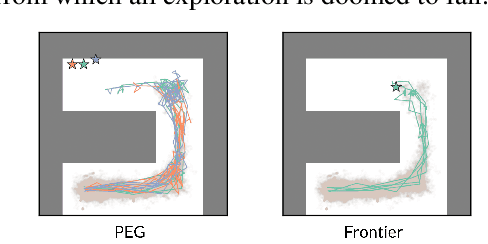
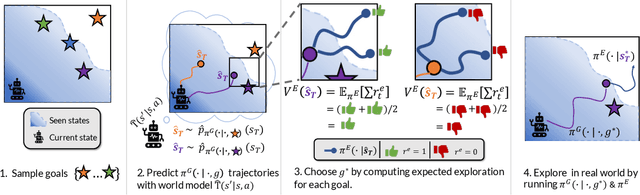
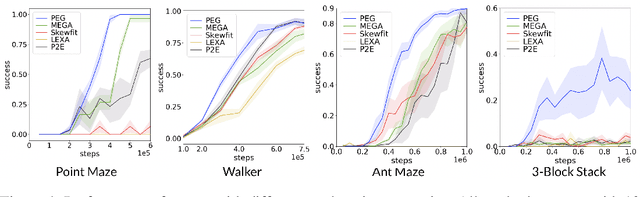
Dropped into an unknown environment, what should an agent do to quickly learn about the environment and how to accomplish diverse tasks within it? We address this question within the goal-conditioned reinforcement learning paradigm, by identifying how the agent should set its goals at training time to maximize exploration. We propose "Planning Exploratory Goals" (PEG), a method that sets goals for each training episode to directly optimize an intrinsic exploration reward. PEG first chooses goal commands such that the agent's goal-conditioned policy, at its current level of training, will end up in states with high exploration potential. It then launches an exploration policy starting at those promising states. To enable this direct optimization, PEG learns world models and adapts sampling-based planning algorithms to "plan goal commands". In challenging simulated robotics environments including a multi-legged ant robot in a maze, and a robot arm on a cluttered tabletop, PEG exploration enables more efficient and effective training of goal-conditioned policies relative to baselines and ablations. Our ant successfully navigates a long maze, and the robot arm successfully builds a stack of three blocks upon command. Website: https://penn-pal-lab.github.io/peg/
Learning General World Models in a Handful of Reward-Free Deployments
Oct 23, 2022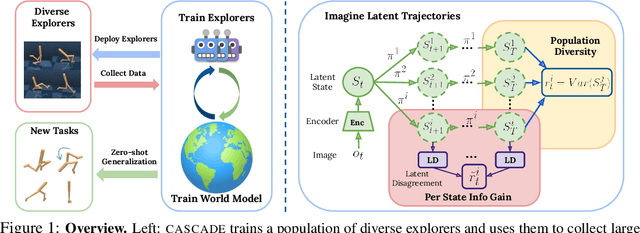
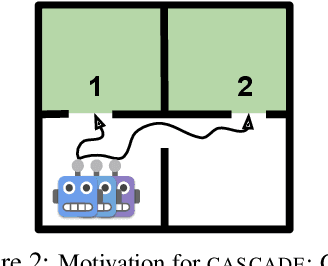
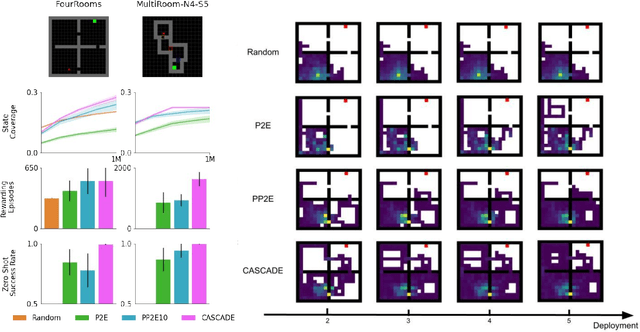
Building generally capable agents is a grand challenge for deep reinforcement learning (RL). To approach this challenge practically, we outline two key desiderata: 1) to facilitate generalization, exploration should be task agnostic; 2) to facilitate scalability, exploration policies should collect large quantities of data without costly centralized retraining. Combining these two properties, we introduce the reward-free deployment efficiency setting, a new paradigm for RL research. We then present CASCADE, a novel approach for self-supervised exploration in this new setting. CASCADE seeks to learn a world model by collecting data with a population of agents, using an information theoretic objective inspired by Bayesian Active Learning. CASCADE achieves this by specifically maximizing the diversity of trajectories sampled by the population through a novel cascading objective. We provide theoretical intuition for CASCADE which we show in a tabular setting improves upon na\"ive approaches that do not account for population diversity. We then demonstrate that CASCADE collects diverse task-agnostic datasets and learns agents that generalize zero-shot to novel, unseen downstream tasks on Atari, MiniGrid, Crafter and the DM Control Suite. Code and videos are available at https://ycxuyingchen.github.io/cascade/
Discovering and Achieving Goals via World Models
Oct 18, 2021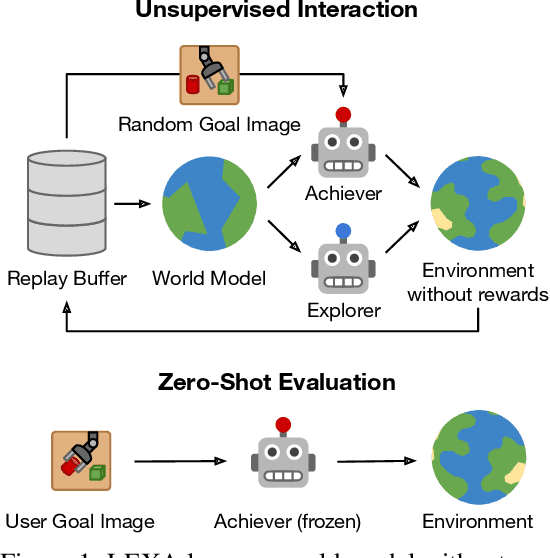
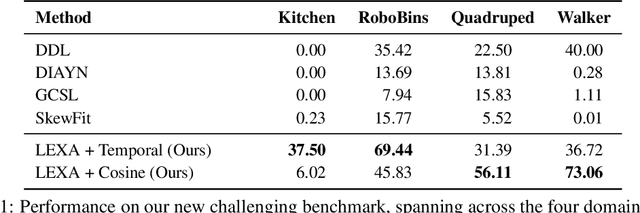
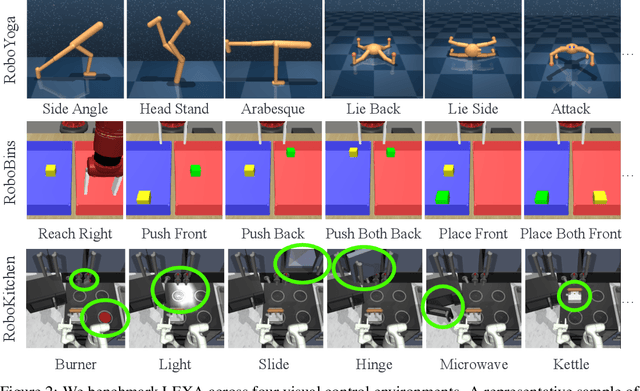
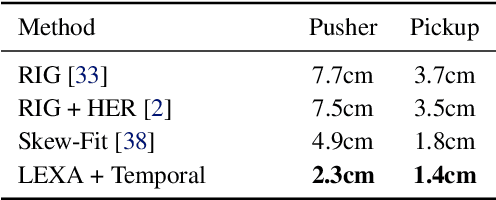
How can artificial agents learn to solve many diverse tasks in complex visual environments in the absence of any supervision? We decompose this question into two problems: discovering new goals and learning to reliably achieve them. We introduce Latent Explorer Achiever (LEXA), a unified solution to these that learns a world model from image inputs and uses it to train an explorer and an achiever policy from imagined rollouts. Unlike prior methods that explore by reaching previously visited states, the explorer plans to discover unseen surprising states through foresight, which are then used as diverse targets for the achiever to practice. After the unsupervised phase, LEXA solves tasks specified as goal images zero-shot without any additional learning. LEXA substantially outperforms previous approaches to unsupervised goal-reaching, both on prior benchmarks and on a new challenging benchmark with a total of 40 test tasks spanning across four standard robotic manipulation and locomotion domains. LEXA further achieves goals that require interacting with multiple objects in sequence. Finally, to demonstrate the scalability and generality of LEXA, we train a single general agent across four distinct environments. Code and videos at https://orybkin.github.io/lexa/
Know Thyself: Transferable Visuomotor Control Through Robot-Awareness
Jul 28, 2021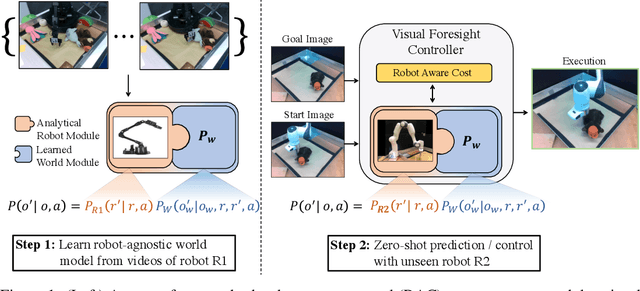

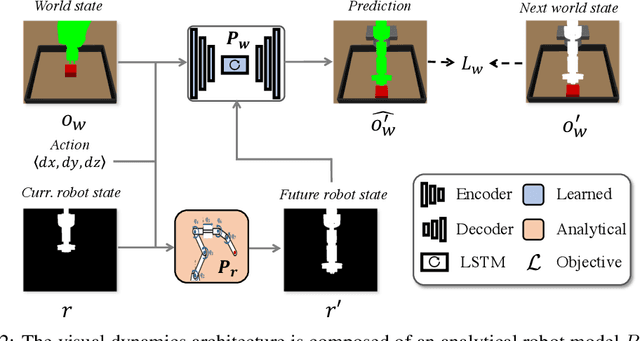
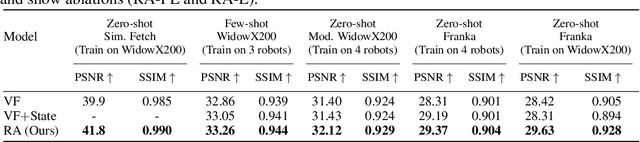
Training visuomotor robot controllers from scratch on a new robot typically requires generating large amounts of robot-specific data. Could we leverage data previously collected on another robot to reduce or even completely remove this need for robot-specific data? We propose a "robot-aware" solution paradigm that exploits readily available robot "self-knowledge" such as proprioception, kinematics, and camera calibration to achieve this. First, we learn modular dynamics models that pair a transferable, robot-agnostic world dynamics module with a robot-specific, analytical robot dynamics module. Next, we set up visual planning costs that draw a distinction between the robot self and the world. Our experiments on tabletop manipulation tasks in simulation and on real robots demonstrate that these plug-in improvements dramatically boost the transferability of visuomotor controllers, even permitting zero-shot transfer onto new robots for the very first time. Project website: https://hueds.github.io/rac/
Model-Based Reinforcement Learning via Latent-Space Collocation
Jun 24, 2021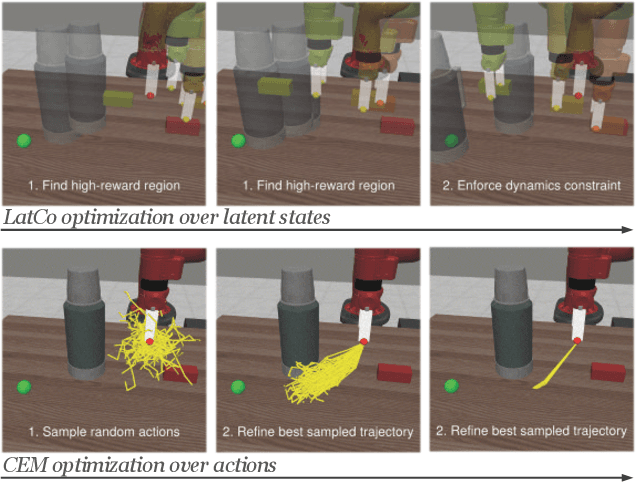
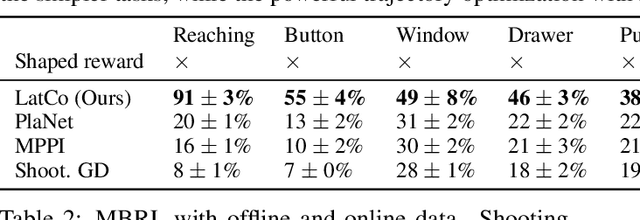
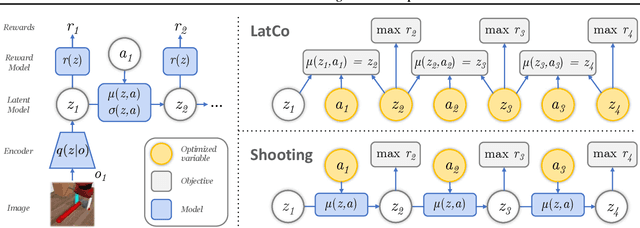

The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals. Videos and code at https://orybkin.github.io/latco/.