 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering and Achieving Goals via World Models
Paper and Code
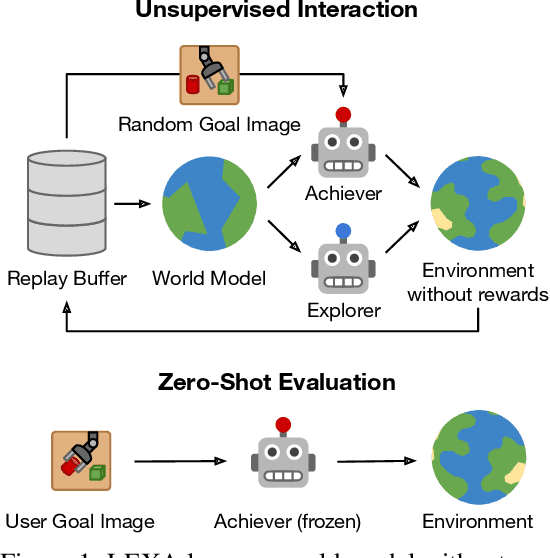
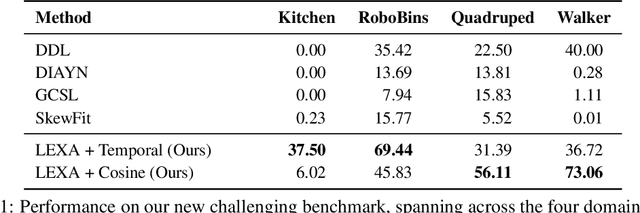
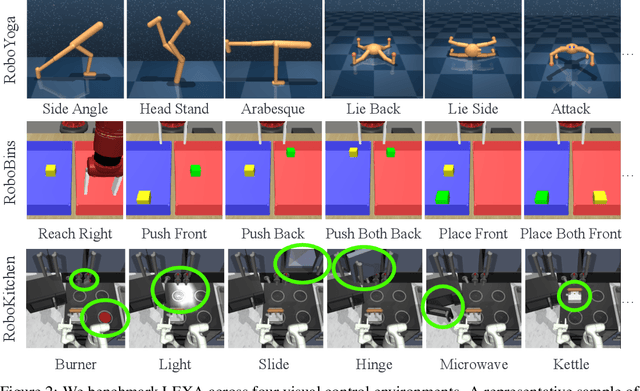
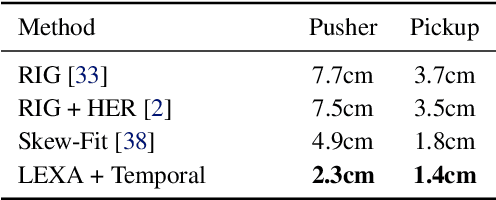
How can artificial agents learn to solve many diverse tasks in complex visual environments in the absence of any supervision? We decompose this question into two problems: discovering new goals and learning to reliably achieve them. We introduce Latent Explorer Achiever (LEXA), a unified solution to these that learns a world model from image inputs and uses it to train an explorer and an achiever policy from imagined rollouts. Unlike prior methods that explore by reaching previously visited states, the explorer plans to discover unseen surprising states through foresight, which are then used as diverse targets for the achiever to practice. After the unsupervised phase, LEXA solves tasks specified as goal images zero-shot without any additional learning. LEXA substantially outperforms previous approaches to unsupervised goal-reaching, both on prior benchmarks and on a new challenging benchmark with a total of 40 test tasks spanning across four standard robotic manipulation and locomotion domains. LEXA further achieves goals that require interacting with multiple objects in sequence. Finally, to demonstrate the scalability and generality of LEXA, we train a single general agent across four distinct environments. Code and videos at https://orybkin.github.io/lexa/