 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Videos: Combining Offline Observations with Interaction
Paper and Code
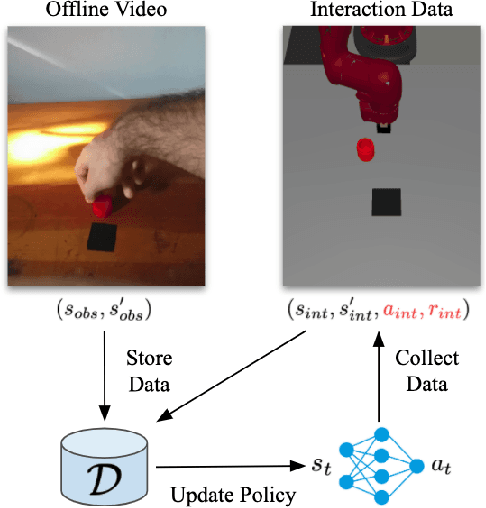



Reinforcement learning is a powerful framework for robots to acquire skills from experience, but often requires a substantial amount of online data collection. As a result, it is difficult to collect sufficiently diverse experiences that are needed for robots to generalize broadly. Videos of humans, on the other hand, are a readily available source of broad and interesting experiences. In this paper, we consider the question: can we perform reinforcement learning directly on experience collected by humans? This problem is particularly difficult, as such videos are not annotated with actions and exhibit substantial visual domain shift relative to the robot's embodiment. To address these challenges, we propose a framework for reinforcement learning with videos (RLV). RLV learns a policy and value function using experience collected by humans in combination with data collected by robots. In our experiments, we find that RLV is able to leverage such videos to learn challenging vision-based skills with less than half as many samples as RL methods that learn from scratch.