 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Action Models are Zero-shot Policies
Feb 17, 2026State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from other robots or humans yield a relative improvement of over 42% on unseen task performance with just 10-20 minutes of data. More surprisingly, DreamZero enables few-shot embodiment adaptation, transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.
Semantic World Models
Oct 22, 2025Planning with world models offers a powerful paradigm for robotic control. Conventional approaches train a model to predict future frames conditioned on current frames and actions, which can then be used for planning. However, the objective of predicting future pixels is often at odds with the actual planning objective; strong pixel reconstruction does not always correlate with good planning decisions. This paper posits that instead of reconstructing future frames as pixels, world models only need to predict task-relevant semantic information about the future. For such prediction the paper poses world modeling as a visual question answering problem about semantic information in future frames. This perspective allows world modeling to be approached with the same tools underlying vision language models. Thus vision language models can be trained as "semantic" world models through a supervised finetuning process on image-action-text data, enabling planning for decision-making while inheriting many of the generalization and robustness properties from the pretrained vision-language models. The paper demonstrates how such a semantic world model can be used for policy improvement on open-ended robotics tasks, leading to significant generalization improvements over typical paradigms of reconstruction-based action-conditional world modeling. Website available at https://weirdlabuw.github.io/swm.
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Apr 03, 2025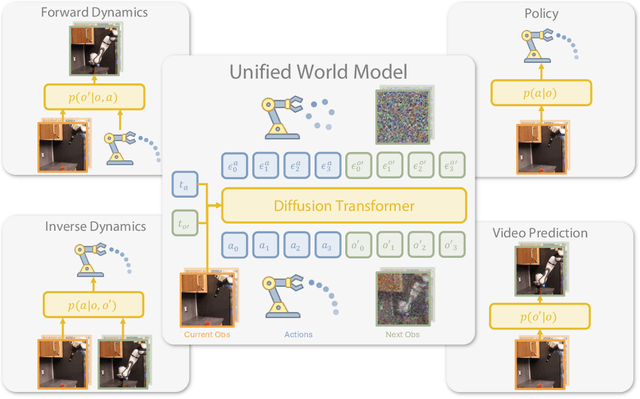
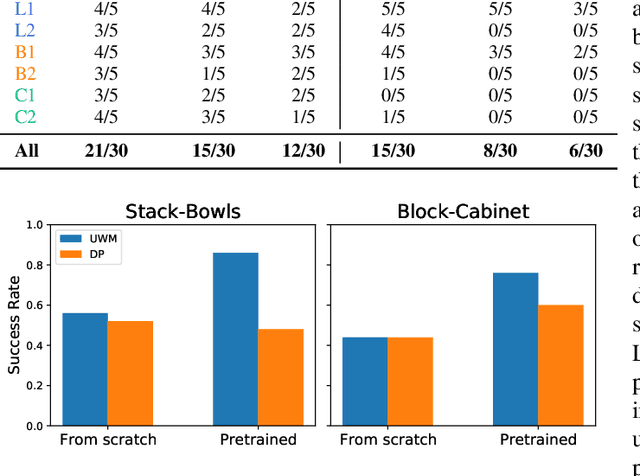


Imitation learning has emerged as a promising approach towards building generalist robots. However, scaling imitation learning for large robot foundation models remains challenging due to its reliance on high-quality expert demonstrations. Meanwhile, large amounts of video data depicting a wide range of environments and diverse behaviors are readily available. This data provides a rich source of information about real-world dynamics and agent-environment interactions. Leveraging this data directly for imitation learning, however, has proven difficult due to the lack of action annotation required for most contemporary methods. In this work, we present Unified World Models (UWM), a framework that allows for leveraging both video and action data for policy learning. Specifically, a UWM integrates an action diffusion process and a video diffusion process within a unified transformer architecture, where independent diffusion timesteps govern each modality. We show that by simply controlling each diffusion timestep, UWM can flexibly represent a policy, a forward dynamics, an inverse dynamics, and a video generator. Through simulated and real-world experiments, we show that: (1) UWM enables effective pretraining on large-scale multitask robot datasets with both dynamics and action predictions, resulting in more generalizable and robust policies than imitation learning, (2) UWM naturally facilitates learning from action-free video data through independent control of modality-specific diffusion timesteps, further improving the performance of finetuned policies. Our results suggest that UWM offers a promising step toward harnessing large, heterogeneous datasets for scalable robot learning, and provides a simple unification between the often disparate paradigms of imitation learning and world modeling. Videos and code are available at https://weirdlabuw.github.io/uwm/.
ASID: Active Exploration for System Identification in Robotic Manipulation
Apr 18, 2024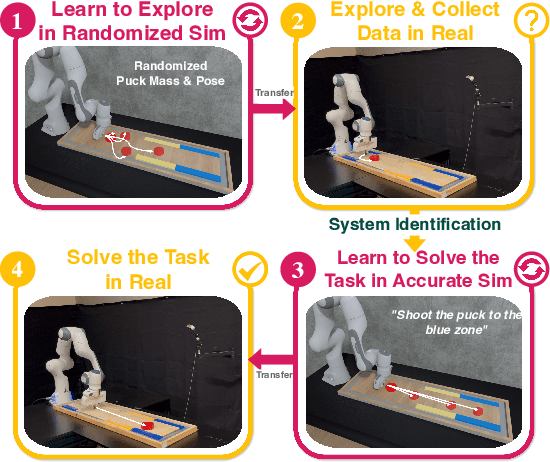

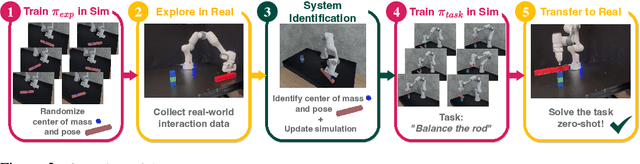

Model-free control strategies such as reinforcement learning have shown the ability to learn control strategies without requiring an accurate model or simulator of the world. While this is appealing due to the lack of modeling requirements, such methods can be sample inefficient, making them impractical in many real-world domains. On the other hand, model-based control techniques leveraging accurate simulators can circumvent these challenges and use a large amount of cheap simulation data to learn controllers that can effectively transfer to the real world. The challenge with such model-based techniques is the requirement for an extremely accurate simulation, requiring both the specification of appropriate simulation assets and physical parameters. This requires considerable human effort to design for every environment being considered. In this work, we propose a learning system that can leverage a small amount of real-world data to autonomously refine a simulation model and then plan an accurate control strategy that can be deployed in the real world. Our approach critically relies on utilizing an initial (possibly inaccurate) simulator to design effective exploration policies that, when deployed in the real world, collect high-quality data. We demonstrate the efficacy of this paradigm in identifying articulation, mass, and other physical parameters in several challenging robotic manipulation tasks, and illustrate that only a small amount of real-world data can allow for effective sim-to-real transfer. Project website at https://weirdlabuw.github.io/asid
Transferable Reinforcement Learning via Generalized Occupancy Models
Mar 10, 2024Intelligent agents must be generalists - showing the ability to quickly adapt and generalize to varying tasks. Within the framework of reinforcement learning (RL), model-based RL algorithms learn a task-agnostic dynamics model of the world, in principle allowing them to generalize to arbitrary rewards. However, one-step models naturally suffer from compounding errors, making them ineffective for problems with long horizons and large state spaces. In this work, we propose a novel class of models - generalized occupancy models (GOMs) - that retain the generality of model-based RL while avoiding compounding error. The key idea behind GOMs is to model the distribution of all possible long-term outcomes from a given state under the coverage of a stationary dataset, along with a policy that realizes a particular outcome from the given state. These models can then quickly be used to select the optimal action for arbitrary new tasks, without having to redo policy optimization. By directly modeling long-term outcomes, GOMs avoid compounding error while retaining generality across arbitrary reward functions. We provide a practical instantiation of GOMs using diffusion models and show its efficacy as a new class of transferable models, both theoretically and empirically across a variety of simulated robotics problems. Videos and code at https://weirdlabuw.github.io/gom/.
Free from Bellman Completeness: Trajectory Stitching via Model-based Return-conditioned Supervised Learning
Oct 30, 2023



Off-policy dynamic programming (DP) techniques such as $Q$-learning have proven to be an important technique for solving sequential decision-making problems. However, in the presence of function approximation such algorithms are not guaranteed to converge, often diverging due to the absence of Bellman-completeness in the function classes considered, a crucial condition for the success of DP-based methods. In this paper, we show how off-policy learning techniques based on return-conditioned supervised learning (RCSL) are able to circumvent these challenges of Bellman completeness, converging under significantly more relaxed assumptions inherited from supervised learning. We prove there exists a natural environment in which if one uses two-layer multilayer perceptron as the function approximator, the layer width needs to grow linearly with the state space size to satisfy Bellman-completeness while a constant layer width is enough for RCSL. These findings take a step towards explaining the superior empirical performance of RCSL methods compared to DP-based methods in environments with near-optimal datasets. Furthermore, in order to learn from sub-optimal datasets, we propose a simple framework called MBRCSL, granting RCSL methods the ability of dynamic programming to stitch together segments from distinct trajectories. MBRCSL leverages learned dynamics models and forward sampling to accomplish trajectory stitching while avoiding the need for Bellman completeness that plagues all dynamic programming algorithms. We propose both theoretical analysis and experimental evaluation to back these claims, outperforming state-of-the-art model-free and model-based offline RL algorithms across several simulated robotics problems.
RePo: Resilient Model-Based Reinforcement Learning by Regularizing Posterior Predictability
Aug 31, 2023



Visual model-based RL methods typically encode image observations into low-dimensional representations in a manner that does not eliminate redundant information. This leaves them susceptible to spurious variations -- changes in task-irrelevant components such as background distractors or lighting conditions. In this paper, we propose a visual model-based RL method that learns a latent representation resilient to such spurious variations. Our training objective encourages the representation to be maximally predictive of dynamics and reward, while constraining the information flow from the observation to the latent representation. We demonstrate that this objective significantly bolsters the resilience of visual model-based RL methods to visual distractors, allowing them to operate in dynamic environments. We then show that while the learned encoder is resilient to spirious variations, it is not invariant under significant distribution shift. To address this, we propose a simple reward-free alignment procedure that enables test time adaptation of the encoder. This allows for quick adaptation to widely differing environments without having to relearn the dynamics and policy. Our effort is a step towards making model-based RL a practical and useful tool for dynamic, diverse domains. We show its effectiveness in simulation benchmarks with significant spurious variations as well as a real-world egocentric navigation task with noisy TVs in the background. Videos and code at https://zchuning.github.io/repo-website/.
Self-Supervised Reinforcement Learning that Transfers using Random Features
May 26, 2023Model-free reinforcement learning algorithms have exhibited great potential in solving single-task sequential decision-making problems with high-dimensional observations and long horizons, but are known to be hard to generalize across tasks. Model-based RL, on the other hand, learns task-agnostic models of the world that naturally enables transfer across different reward functions, but struggles to scale to complex environments due to the compounding error. To get the best of both worlds, we propose a self-supervised reinforcement learning method that enables the transfer of behaviors across tasks with different rewards, while circumventing the challenges of model-based RL. In particular, we show self-supervised pre-training of model-free reinforcement learning with a number of random features as rewards allows implicit modeling of long-horizon environment dynamics. Then, planning techniques like model-predictive control using these implicit models enable fast adaptation to problems with new reward functions. Our method is self-supervised in that it can be trained on offline datasets without reward labels, but can then be quickly deployed on new tasks. We validate that our proposed method enables transfer across tasks on a variety of manipulation and locomotion domains in simulation, opening the door to generalist decision-making agents.
Model-Based Reinforcement Learning via Latent-Space Collocation
Jun 24, 2021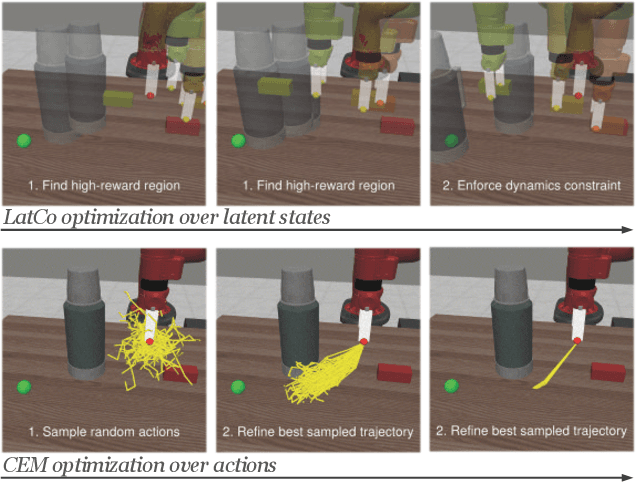
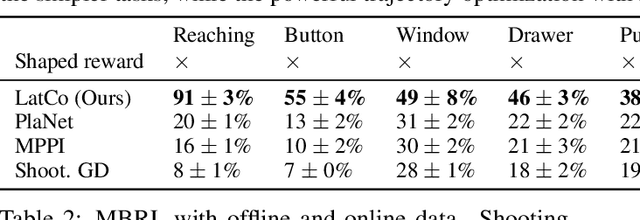
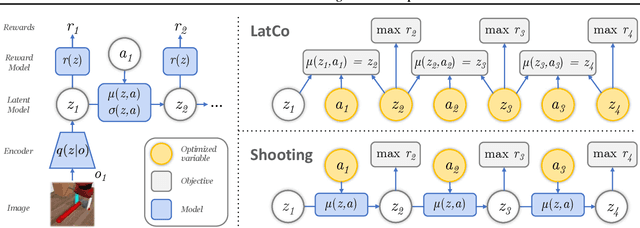

The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals. Videos and code at https://orybkin.github.io/latco/.