 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Dexterity via Diverse Resets and Large-Scale Reinforcement Learning
Mar 16, 2026Reinforcement learning in massively parallel physics simulations has driven major progress in sim-to-real robot learning. However, current approaches remain brittle and task-specific, relying on extensive per-task engineering to design rewards, curricula, and demonstrations. Even with this engineering, they often fail on long-horizon, contact-rich manipulation tasks and do not meaningfully scale with compute, as performance quickly saturates when training revisits the same narrow regions of state space. We introduce \Method, a simple and scalable framework that enables on-policy reinforcement learning to robustly solve a broad class of dexterous manipulation tasks using a single reward function, fixed algorithm hyperparameters, no curricula, and no human demonstrations. Our key insight is that long-horizon exploration can be dramatically simplified by using simulator resets to systematically expose the RL algorithm to the diverse set of robot-object interactions which underlie dexterous manipulation. \Method\ programmatically generates such resets with minimal human input, converting additional compute directly into broader behavioral coverage and continued performance gains. We show that \Method\ gracefully scales to long-horizon dexterous manipulation tasks beyond the capabilities of existing approaches and is able to learn robust policies over significantly wider ranges of initial conditions than baselines. Finally, we distill \Method \ into visuomotor policies which display robust retrying behavior and substantially higher success rates than baselines when transferred to the real world zero-shot. Project webpage: https://omnireset.github.io
Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
Mar 16, 2026Simulation-to-real transfer remains a central challenge in robotics, as mismatches between simulated and real-world dynamics often lead to failures. While reinforcement learning offers a principled mechanism for adaptation, existing sim-to-real finetuning methods struggle with exploration and long-horizon credit assignment in the low-data regimes typical of real-world robotics. We introduce Simulation Distillation (SimDist), a sim-to-real framework that distills structural priors from a simulator into a latent world model and enables rapid real-world adaptation via online planning and supervised dynamics finetuning. By transferring reward and value models directly from simulation, SimDist provides dense planning signals from raw perception without requiring value learning during deployment. As a result, real-world adaptation reduces to short-horizon system identification, avoiding long-horizon credit assignment and enabling fast, stable improvement. Across precise manipulation and quadruped locomotion tasks, SimDist substantially outperforms prior methods in data efficiency, stability, and final performance. Project website and code: https://sim-dist.github.io/
Rapidly Adapting Policies to the Real World via Simulation-Guided Fine-Tuning
Feb 04, 2025



Robot learning requires a considerable amount of high-quality data to realize the promise of generalization. However, large data sets are costly to collect in the real world. Physics simulators can cheaply generate vast data sets with broad coverage over states, actions, and environments. However, physics engines are fundamentally misspecified approximations to reality. This makes direct zero-shot transfer from simulation to reality challenging, especially in tasks where precise and force-sensitive manipulation is necessary. Thus, fine-tuning these policies with small real-world data sets is an appealing pathway for scaling robot learning. However, current reinforcement learning fine-tuning frameworks leverage general, unstructured exploration strategies which are too inefficient to make real-world adaptation practical. This paper introduces the Simulation-Guided Fine-tuning (SGFT) framework, which demonstrates how to extract structural priors from physics simulators to substantially accelerate real-world adaptation. Specifically, our approach uses a value function learned in simulation to guide real-world exploration. We demonstrate this approach across five real-world dexterous manipulation tasks where zero-shot sim-to-real transfer fails. We further demonstrate our framework substantially outperforms baseline fine-tuning methods, requiring up to an order of magnitude fewer real-world samples and succeeding at difficult tasks where prior approaches fail entirely. Last but not least, we provide theoretical justification for this new paradigm which underpins how SGFT can rapidly learn high-performance policies in the face of large sim-to-real dynamics gaps. Project webpage: https://weirdlabuw.github.io/sgft/{weirdlabuw.github.io/sgft}
ASID: Active Exploration for System Identification in Robotic Manipulation
Apr 18, 2024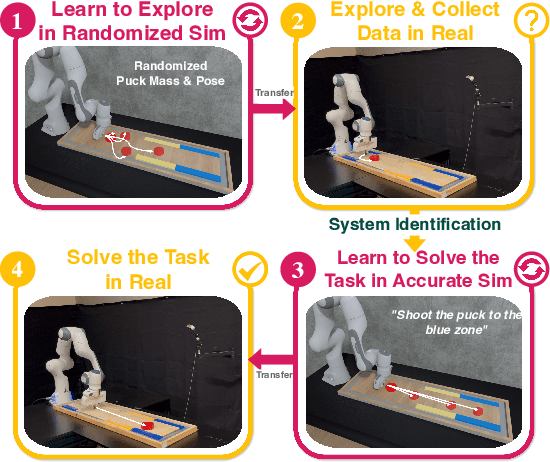


Model-free control strategies such as reinforcement learning have shown the ability to learn control strategies without requiring an accurate model or simulator of the world. While this is appealing due to the lack of modeling requirements, such methods can be sample inefficient, making them impractical in many real-world domains. On the other hand, model-based control techniques leveraging accurate simulators can circumvent these challenges and use a large amount of cheap simulation data to learn controllers that can effectively transfer to the real world. The challenge with such model-based techniques is the requirement for an extremely accurate simulation, requiring both the specification of appropriate simulation assets and physical parameters. This requires considerable human effort to design for every environment being considered. In this work, we propose a learning system that can leverage a small amount of real-world data to autonomously refine a simulation model and then plan an accurate control strategy that can be deployed in the real world. Our approach critically relies on utilizing an initial (possibly inaccurate) simulator to design effective exploration policies that, when deployed in the real world, collect high-quality data. We demonstrate the efficacy of this paradigm in identifying articulation, mass, and other physical parameters in several challenging robotic manipulation tasks, and illustrate that only a small amount of real-world data can allow for effective sim-to-real transfer. Project website at https://weirdlabuw.github.io/asid
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Stabilizing Contrastive RL: Techniques for Offline Goal Reaching
Jun 06, 2023



In the same way that the computer vision (CV) and natural language processing (NLP) communities have developed self-supervised methods, reinforcement learning (RL) can be cast as a self-supervised problem: learning to reach any goal, without requiring human-specified rewards or labels. However, actually building a self-supervised foundation for RL faces some important challenges. Building on prior contrastive approaches to this RL problem, we conduct careful ablation experiments and discover that a shallow and wide architecture, combined with careful weight initialization and data augmentation, can significantly boost the performance of these contrastive RL approaches on challenging simulated benchmarks. Additionally, we demonstrate that, with these design decisions, contrastive approaches can solve real-world robotic manipulation tasks, with tasks being specified by a single goal image provided after training.
Generalization with Lossy Affordances: Leveraging Broad Offline Data for Learning Visuomotor Tasks
Oct 12, 2022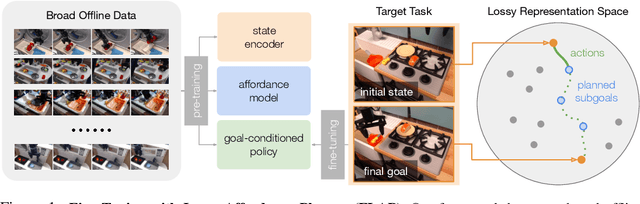
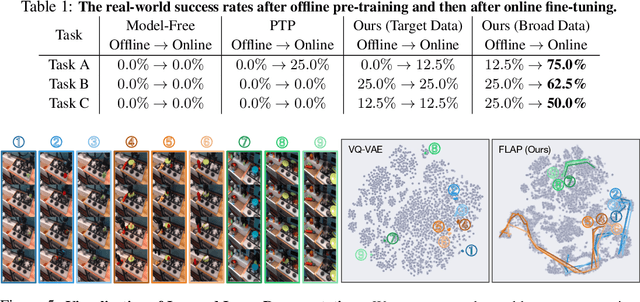
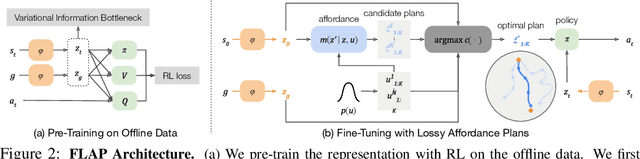
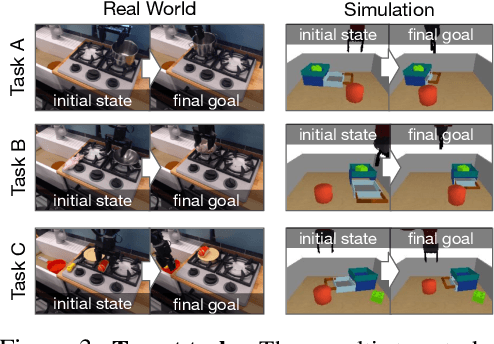
The utilization of broad datasets has proven to be crucial for generalization for a wide range of fields. However, how to effectively make use of diverse multi-task data for novel downstream tasks still remains a grand challenge in robotics. To tackle this challenge, we introduce a framework that acquires goal-conditioned policies for unseen temporally extended tasks via offline reinforcement learning on broad data, in combination with online fine-tuning guided by subgoals in learned lossy representation space. When faced with a novel task goal, the framework uses an affordance model to plan a sequence of lossy representations as subgoals that decomposes the original task into easier problems. Learned from the broad data, the lossy representation emphasizes task-relevant information about states and goals while abstracting away redundant contexts that hinder generalization. It thus enables subgoal planning for unseen tasks, provides a compact input to the policy, and facilitates reward shaping during fine-tuning. We show that our framework can be pre-trained on large-scale datasets of robot experiences from prior work and efficiently fine-tuned for novel tasks, entirely from visual inputs without any manual reward engineering.
Planning to Practice: Efficient Online Fine-Tuning by Composing Goals in Latent Space
May 17, 2022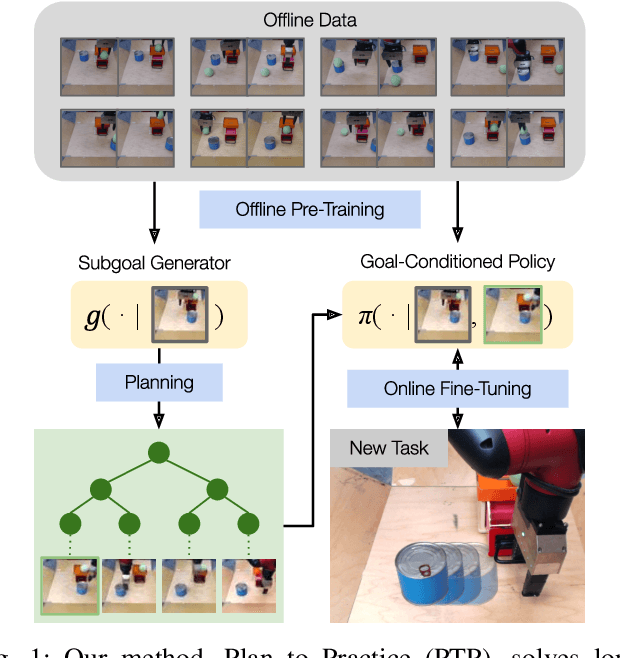
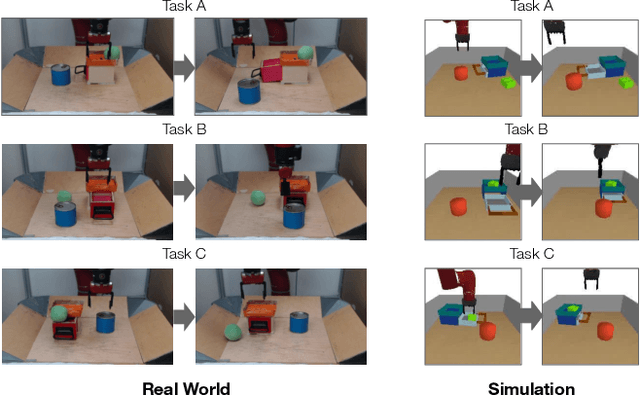
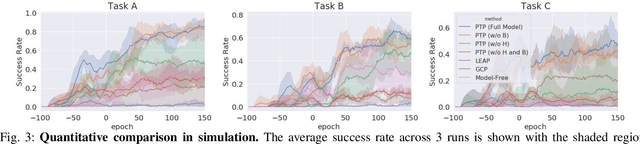

General-purpose robots require diverse repertoires of behaviors to complete challenging tasks in real-world unstructured environments. To address this issue, goal-conditioned reinforcement learning aims to acquire policies that can reach configurable goals for a wide range of tasks on command. However, such goal-conditioned policies are notoriously difficult and time-consuming to train from scratch. In this paper, we propose Planning to Practice (PTP), a method that makes it practical to train goal-conditioned policies for long-horizon tasks that require multiple distinct types of interactions to solve. Our approach is based on two key ideas. First, we decompose the goal-reaching problem hierarchically, with a high-level planner that sets intermediate subgoals using conditional subgoal generators in the latent space for a low-level model-free policy. Second, we propose a hybrid approach which first pre-trains both the conditional subgoal generator and the policy on previously collected data through offline reinforcement learning, and then fine-tunes the policy via online exploration. This fine-tuning process is itself facilitated by the planned subgoals, which breaks down the original target task into short-horizon goal-reaching tasks that are significantly easier to learn. We conduct experiments in both the simulation and real world, in which the policy is pre-trained on demonstrations of short primitive behaviors and fine-tuned for temporally extended tasks that are unseen in the offline data. Our experimental results show that PTP can generate feasible sequences of subgoals that enable the policy to efficiently solve the target tasks.
Bisimulation Makes Analogies in Goal-Conditioned Reinforcement Learning
Apr 28, 2022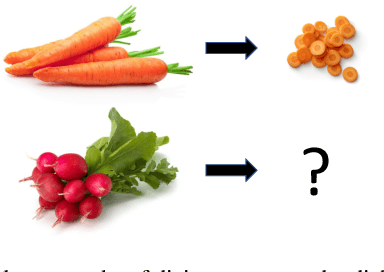
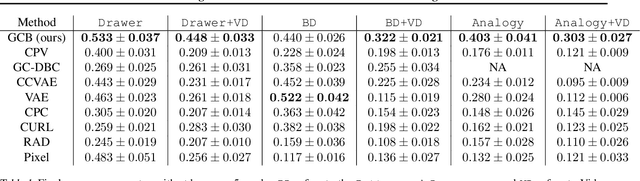


Building generalizable goal-conditioned agents from rich observations is a key to reinforcement learning (RL) solving real world problems. Traditionally in goal-conditioned RL, an agent is provided with the exact goal they intend to reach. However, it is often not realistic to know the configuration of the goal before performing a task. A more scalable framework would allow us to provide the agent with an example of an analogous task, and have the agent then infer what the goal should be for its current state. We propose a new form of state abstraction called goal-conditioned bisimulation that captures functional equivariance, allowing for the reuse of skills to achieve new goals. We learn this representation using a metric form of this abstraction, and show its ability to generalize to new goals in simulation manipulation tasks. Further, we prove that this learned representation is sufficient not only for goal conditioned tasks, but is amenable to any downstream task described by a state-only reward function. Videos can be found at https://sites.google.com/view/gc-bisimulation.