 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEM: Multi-Scale Embodied Memory for Vision Language Action Models
Mar 04, 2026Conventionally, memory in end-to-end robotic learning involves inputting a sequence of past observations into the learned policy. However, in complex multi-stage real-world tasks, the robot's memory must represent past events at multiple levels of granularity: from long-term memory that captures abstracted semantic concepts (e.g., a robot cooking dinner should remember which stages of the recipe are already done) to short-term memory that captures recent events and compensates for occlusions (e.g., a robot remembering the object it wants to pick up once its arm occludes it). In this work, our main insight is that an effective memory architecture for long-horizon robotic control should combine multiple modalities to capture these different levels of abstraction. We introduce Multi-Scale Embodied Memory (MEM), an approach for mixed-modal long-horizon memory in robot policies. MEM combines video-based short-horizon memory, compressed via a video encoder, with text-based long-horizon memory. Together, they enable robot policies to perform tasks that span up to fifteen minutes, like cleaning up a kitchen, or preparing a grilled cheese sandwich. Additionally, we find that memory enables MEM policies to intelligently adapt manipulation strategies in-context.
Emergence of Human to Robot Transfer in Vision-Language-Action Models
Dec 27, 2025Vision-language-action (VLA) models can enable broad open world generalization, but require large and diverse datasets. It is appealing to consider whether some of this data can come from human videos, which cover diverse real-world situations and are easy to obtain. However, it is difficult to train VLAs with human videos alone, and establishing a mapping between humans and robots requires manual engineering and presents a major research challenge. Drawing inspiration from advances in large language models, where the ability to learn from diverse supervision emerges with scale, we ask whether a similar phenomenon holds for VLAs that incorporate human video data. We introduce a simple co-training recipe, and find that human-to-robot transfer emerges once the VLA is pre-trained on sufficient scenes, tasks, and embodiments. Our analysis suggests that this emergent capability arises because diverse pretraining produces embodiment-agnostic representations for human and robot data. We validate these findings through a series of experiments probing human to robot skill transfer and find that with sufficiently diverse robot pre-training our method can nearly double the performance on generalization settings seen only in human data.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
A Representation Sharpening Framework for Zero Shot Dense Retrieval
Nov 07, 2025Zero-shot dense retrieval is a challenging setting where a document corpus is provided without relevant queries, necessitating a reliance on pretrained dense retrievers (DRs). However, since these DRs are not trained on the target corpus, they struggle to represent semantic differences between similar documents. To address this failing, we introduce a training-free representation sharpening framework that augments a document's representation with information that helps differentiate it from similar documents in the corpus. On over twenty datasets spanning multiple languages, the representation sharpening framework proves consistently superior to traditional retrieval, setting a new state-of-the-art on the BRIGHT benchmark. We show that representation sharpening is compatible with prior approaches to zero-shot dense retrieval and consistently improves their performance. Finally, we address the performance-cost tradeoff presented by our framework and devise an indexing-time approximation that preserves the majority of our performance gains over traditional retrieval, yet suffers no additional inference-time cost.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Jan 16, 2025



Autoregressive sequence models, such as Transformer-based vision-language action (VLA) policies, can be tremendously effective for capturing complex and generalizable robotic behaviors. However, such models require us to choose a tokenization of our continuous action signals, which determines how the discrete symbols predicted by the model map to continuous robot actions. We find that current approaches for robot action tokenization, based on simple per-dimension, per-timestep binning schemes, typically perform poorly when learning dexterous skills from high-frequency robot data. To address this challenge, we propose a new compression-based tokenization scheme for robot actions, based on the discrete cosine transform. Our tokenization approach, Frequency-space Action Sequence Tokenization (FAST), enables us to train autoregressive VLAs for highly dexterous and high-frequency tasks where standard discretization methods fail completely. Based on FAST, we release FAST+, a universal robot action tokenizer, trained on 1M real robot action trajectories. It can be used as a black-box tokenizer for a wide range of robot action sequences, with diverse action spaces and control frequencies. Finally, we show that, when combined with the pi0 VLA, our method can scale to training on 10k hours of robot data and match the performance of diffusion VLAs, while reducing training time by up to 5x.
$π_0$: A Vision-Language-Action Flow Model for General Robot Control
Oct 31, 2024
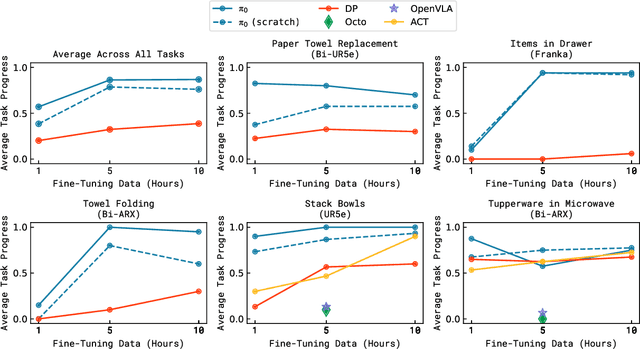

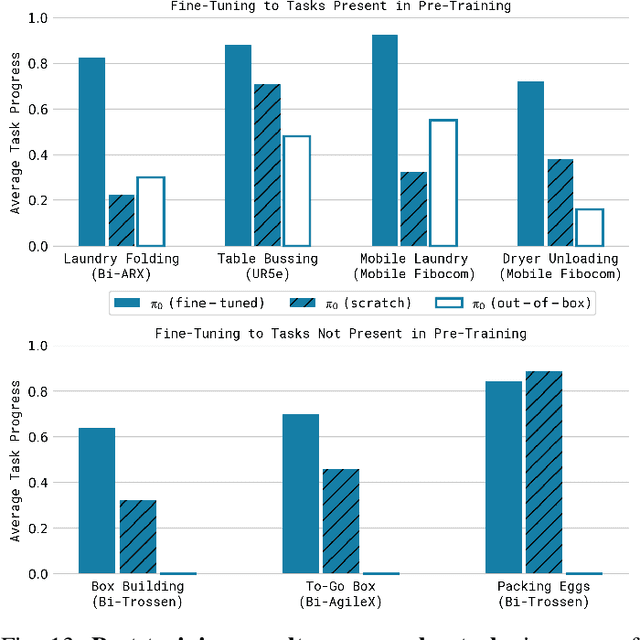
Robot learning holds tremendous promise to unlock the full potential of flexible, general, and dexterous robot systems, as well as to address some of the deepest questions in artificial intelligence. However, bringing robot learning to the level of generality required for effective real-world systems faces major obstacles in terms of data, generalization, and robustness. In this paper, we discuss how generalist robot policies (i.e., robot foundation models) can address these challenges, and how we can design effective generalist robot policies for complex and highly dexterous tasks. We propose a novel flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge. We then discuss how this model can be trained on a large and diverse dataset from multiple dexterous robot platforms, including single-arm robots, dual-arm robots, and mobile manipulators. We evaluate our model in terms of its ability to perform tasks in zero shot after pre-training, follow language instructions from people and from a high-level VLM policy, and its ability to acquire new skills via fine-tuning. Our results cover a wide variety of tasks, such as laundry folding, table cleaning, and assembling boxes.
GHIL-Glue: Hierarchical Control with Filtered Subgoal Images
Oct 26, 2024

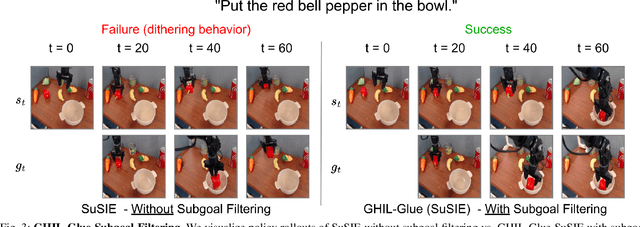

Image and video generative models that are pre-trained on Internet-scale data can greatly increase the generalization capacity of robot learning systems. These models can function as high-level planners, generating intermediate subgoals for low-level goal-conditioned policies to reach. However, the performance of these systems can be greatly bottlenecked by the interface between generative models and low-level controllers. For example, generative models may predict photorealistic yet physically infeasible frames that confuse low-level policies. Low-level policies may also be sensitive to subtle visual artifacts in generated goal images. This paper addresses these two facets of generalization, providing an interface to effectively "glue together" language-conditioned image or video prediction models with low-level goal-conditioned policies. Our method, Generative Hierarchical Imitation Learning-Glue (GHIL-Glue), filters out subgoals that do not lead to task progress and improves the robustness of goal-conditioned policies to generated subgoals with harmful visual artifacts. We find in extensive experiments in both simulated and real environments that GHIL-Glue achieves a 25% improvement across several hierarchical models that leverage generative subgoals, achieving a new state-of-the-art on the CALVIN simulation benchmark for policies using observations from a single RGB camera. GHIL-Glue also outperforms other generalist robot policies across 3/4 language-conditioned manipulation tasks testing zero-shot generalization in physical experiments.
OpenVLA: An Open-Source Vision-Language-Action Model
Jun 13, 2024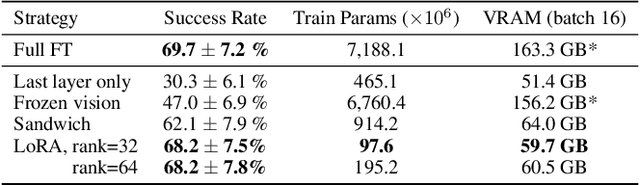
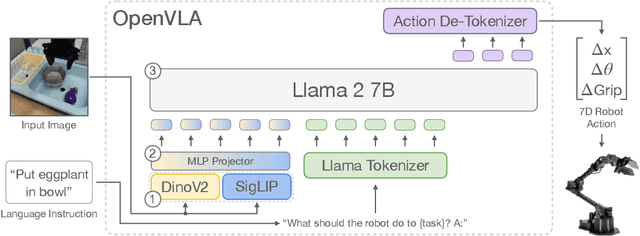
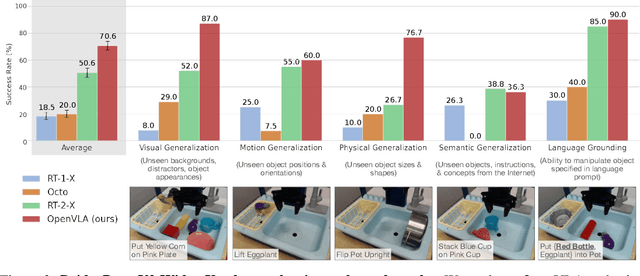
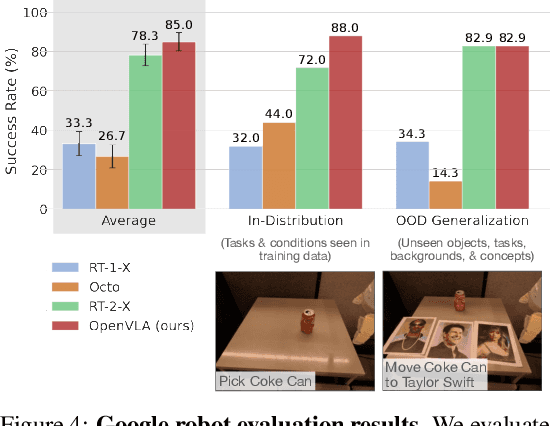
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
Efficiency-Effectiveness Tradeoff of Probabilistic Structured Queries for Cross-Language Information Retrieval
Apr 29, 2024



Probabilistic Structured Queries (PSQ) is a cross-language information retrieval (CLIR) method that uses translation probabilities statistically derived from aligned corpora. PSQ is a strong baseline for efficient CLIR using sparse indexing. It is, therefore, useful as the first stage in a cascaded neural CLIR system whose second stage is more effective but too inefficient to be used on its own to search a large text collection. In this reproducibility study, we revisit PSQ by introducing an efficient Python implementation. Unconstrained use of all translation probabilities that can be estimated from aligned parallel text would in the limit assign a weight to every vocabulary term, precluding use of an inverted index to serve queries efficiently. Thus, PSQ's effectiveness and efficiency both depend on how translation probabilities are pruned. This paper presents experiments over a range of modern CLIR test collections to demonstrate that achieving Pareto optimal PSQ effectiveness-efficiency tradeoffs benefits from multi-criteria pruning, which has not been fully explored in prior work. Our Python PSQ implementation is available on GitHub(https://github.com/hltcoe/PSQ) and unpruned translation tables are available on Huggingface Models(https://huggingface.co/hltcoe/psq_translation_tables).