 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaWika 2: A More Comprehensive Multilingual Collection of Articles and their Sources
Aug 05, 2025We introduce MegaWika 2, a large, multilingual dataset of Wikipedia articles with their citations and scraped web sources; articles are represented in a rich data structure, and scraped source texts are stored inline with precise character offsets of their citations in the article text. MegaWika 2 is a major upgrade from the original MegaWika, spanning six times as many articles and twice as many fully scraped citations. Both MegaWika and MegaWika 2 support report generation research ; whereas MegaWika also focused on supporting question answering and retrieval applications, MegaWika 2 is designed to support fact checking and analyses across time and language.
Towards Large Language Models for Lunar Mission Planning and In Situ Resource Utilization
Apr 28, 2025



A key factor for lunar mission planning is the ability to assess the local availability of raw materials. However, many potentially relevant measurements are scattered across a variety of scientific publications. In this paper we consider the viability of obtaining lunar composition data by leveraging LLMs to rapidly process a corpus of scientific publications. While leveraging LLMs to obtain knowledge from scientific documents is not new, this particular application presents interesting challenges due to the heterogeneity of lunar samples and the nuances involved in their characterization. Accuracy and uncertainty quantification are particularly crucial since many materials properties can be sensitive to small variations in composition. Our findings indicate that off-the-shelf LLMs are generally effective at extracting data from tables commonly found in these documents. However, there remains opportunity to further refine the data we extract in this initial approach; in particular, to capture fine-grained mineralogy information and to improve performance on more subtle/complex pieces of information.
To Burst or Not to Burst: Generating and Quantifying Improbable Text
Jan 27, 2024



While large language models (LLMs) are extremely capable at text generation, their outputs are still distinguishable from human-authored text. We explore this separation across many metrics over text, many sampling techniques, many types of text data, and across two popular LLMs, LLaMA and Vicuna. Along the way, we introduce a new metric, recoverability, to highlight differences between human and machine text; and we propose a new sampling technique, burst sampling, designed to close this gap. We find that LLaMA and Vicuna have distinct distributions under many of the metrics, and that this influences our results: Recoverability separates real from fake text better than any other metric when using LLaMA. When using Vicuna, burst sampling produces text which is distributionally closer to real text compared to other sampling techniques.
MegaWika: Millions of reports and their sources across 50 diverse languages
Jul 13, 2023To foster the development of new models for collaborative AI-assisted report generation, we introduce MegaWika, consisting of 13 million Wikipedia articles in 50 diverse languages, along with their 71 million referenced source materials. We process this dataset for a myriad of applications, going beyond the initial Wikipedia citation extraction and web scraping of content, including translating non-English articles for cross-lingual applications and providing FrameNet parses for automated semantic analysis. MegaWika is the largest resource for sentence-level report generation and the only report generation dataset that is multilingual. We manually analyze the quality of this resource through a semantically stratified sample. Finally, we provide baseline results and trained models for crucial steps in automated report generation: cross-lingual question answering and citation retrieval.
Synthetic Cross-language Information Retrieval Training Data
Apr 29, 2023A key stumbling block for neural cross-language information retrieval (CLIR) systems has been the paucity of training data. The appearance of the MS MARCO monolingual training set led to significant advances in the state of the art in neural monolingual retrieval. By translating the MS MARCO documents into other languages using machine translation, this resource has been made useful to the CLIR community. Yet such translation suffers from a number of problems. While MS MARCO is a large resource, it is of fixed size; its genre and domain of discourse are fixed; and the translated documents are not written in the language of a native speaker of the language, but rather in translationese. To address these problems, we introduce the JH-POLO CLIR training set creation methodology. The approach begins by selecting a pair of non-English passages. A generative large language model is then used to produce an English query for which the first passage is relevant and the second passage is not relevant. By repeating this process, collections of arbitrary size can be created in the style of MS MARCO but using naturally-occurring documents in any desired genre and domain of discourse. This paper describes the methodology in detail, shows its use in creating new CLIR training sets, and describes experiments using the newly created training data.
Interpretable Adversarial Training for Text
May 30, 2019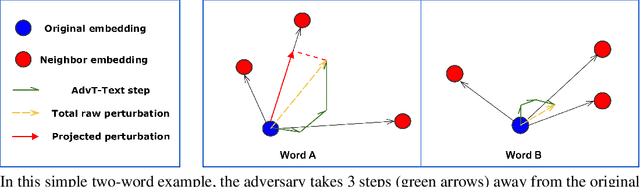
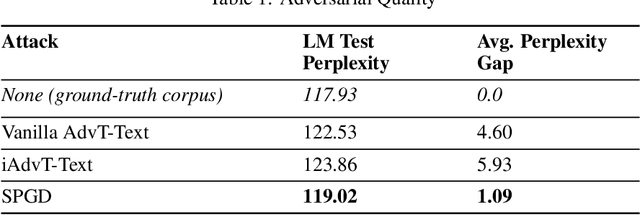
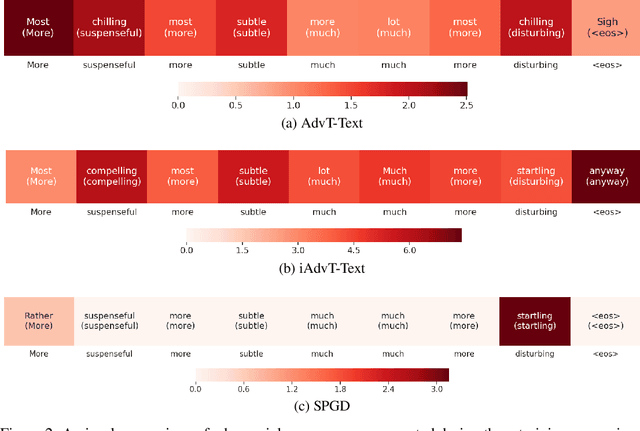

Generating high-quality and interpretable adversarial examples in the text domain is a much more daunting task than it is in the image domain. This is due partly to the discrete nature of text, partly to the problem of ensuring that the adversarial examples are still probable and interpretable, and partly to the problem of maintaining label invariance under input perturbations. In order to address some of these challenges, we introduce sparse projected gradient descent (SPGD), a new approach to crafting interpretable adversarial examples for text. SPGD imposes a directional regularization constraint on input perturbations by projecting them onto the directions to nearby word embeddings with highest cosine similarities. This constraint ensures that perturbations move each word embedding in an interpretable direction (i.e., towards another nearby word embedding). Moreover, SPGD imposes a sparsity constraint on perturbations at the sentence level by ignoring word-embedding perturbations whose norms are below a certain threshold. This constraint ensures that our method changes only a few words per sequence, leading to higher quality adversarial examples. Our experiments with the IMDB movie review dataset show that the proposed SPGD method improves adversarial example interpretability and likelihood (evaluated by average per-word perplexity) compared to state-of-the-art methods, while suffering little to no loss in training performance.