 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Hybrid Captioner for Improved Long-form Video Understanding
Jul 22, 2025Video data, especially long-form video, is extremely dense and high-dimensional. Text-based summaries of video content offer a way to represent query-relevant content in a much more compact manner than raw video. In addition, textual representations are easily ingested by state-of-the-art large language models (LLMs), which enable reasoning over video content to answer complex natural language queries. To solve this issue, we rely on the progressive construction of a text-based memory by a video captioner operating on shorter chunks of the video, where spatio-temporal modeling is computationally feasible. We explore ways to improve the quality of the activity log comprised solely of short video captions. Because the video captions tend to be focused on human actions, and questions may pertain to other information in the scene, we seek to enrich the memory with static scene descriptions using Vision Language Models (VLMs). Our video understanding system relies on the LaViLa video captioner in combination with a LLM to answer questions about videos. We first explored different ways of partitioning the video into meaningful segments such that the textual descriptions more accurately reflect the structure of the video content. Furthermore, we incorporated static scene descriptions into the captioning pipeline using LLaVA VLM, resulting in a more detailed and complete caption log and expanding the space of questions that are answerable from the textual memory. Finally, we have successfully fine-tuned the LaViLa video captioner to produce both action and scene captions, significantly improving the efficiency of the captioning pipeline compared to using separate captioning models for the two tasks. Our model, controllable hybrid captioner, can alternate between different types of captions according to special input tokens that signals scene changes detected in the video.
Sparse Autoencoder Features for Classifications and Transferability
Feb 17, 2025Sparse Autoencoders (SAEs) provide potentials for uncovering structured, human-interpretable representations in Large Language Models (LLMs), making them a crucial tool for transparent and controllable AI systems. We systematically analyze SAE for interpretable feature extraction from LLMs in safety-critical classification tasks. Our framework evaluates (1) model-layer selection and scaling properties, (2) SAE architectural configurations, including width and pooling strategies, and (3) the effect of binarizing continuous SAE activations. SAE-derived features achieve macro F1 > 0.8, outperforming hidden-state and BoW baselines while demonstrating cross-model transfer from Gemma 2 2B to 9B-IT models. These features generalize in a zero-shot manner to cross-lingual toxicity detection and visual classification tasks. Our analysis highlights the significant impact of pooling strategies and binarization thresholds, showing that binarization offers an efficient alternative to traditional feature selection while maintaining or improving performance. These findings establish new best practices for SAE-based interpretability and enable scalable, transparent deployment of LLMs in real-world applications. Full repo: https://github.com/shan23chen/MOSAIC.
Making FETCH! Happen: Finding Emergent Dog Whistles Through Common Habitats
Dec 16, 2024WARNING: This paper contains content that maybe upsetting or offensive to some readers. Dog whistles are coded expressions with dual meanings: one intended for the general public (outgroup) and another that conveys a specific message to an intended audience (ingroup). Often, these expressions are used to convey controversial political opinions while maintaining plausible deniability and slip by content moderation filters. Identification of dog whistles relies on curated lexicons, which have trouble keeping up to date. We introduce \textbf{FETCH!}, a task for finding novel dog whistles in massive social media corpora. We find that state-of-the-art systems fail to achieve meaningful results across three distinct social media case studies. We present \textbf{EarShot}, a novel system that combines the strengths of vector databases and Large Language Models (LLMs) to efficiently and effectively identify new dog whistles.
Mapping Bias in Vision Language Models: Signposts, Pitfalls, and the Road Ahead
Oct 17, 2024


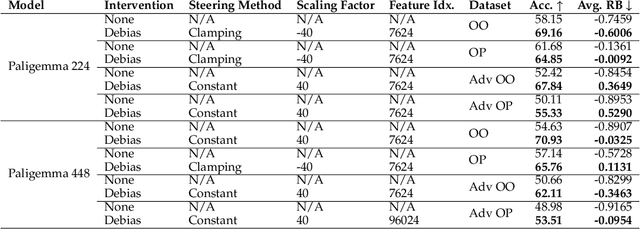
As Vision Language Models (VLMs) gain widespread use, their fairness remains under-explored. In this paper, we analyze demographic biases across five models and six datasets. We find that portrait datasets like UTKFace and CelebA are the best tools for bias detection, finding gaps in performance and fairness between LLaVa and CLIP models. However, scene based datasets like PATA, VLStereoSet fail to be useful benchmarks for bias due to their construction. As for pronoun based datasets like VisoGender, we receive mixed signals as only some subsets of the data are useful in providing insights. To alleviate this problem, we introduce a more difficult version of VisoGender to serve as a more rigorous evaluation. Based on these results, we call for more effective and carefully designed datasets to ensure VLMs are both fair and reliable.
Disease Entity Recognition and Normalization is Improved with Large Language Model Derived Synthetic Normalized Mentions
Oct 10, 2024



Background: Machine learning methods for clinical named entity recognition and entity normalization systems can utilize both labeled corpora and Knowledge Graphs (KGs) for learning. However, infrequently occurring concepts may have few mentions in training corpora and lack detailed descriptions or synonyms, even in large KGs. For Disease Entity Recognition (DER) and Disease Entity Normalization (DEN), this can result in fewer high quality training examples relative to the number of known diseases. Large Language Model (LLM) generation of synthetic training examples could improve performance in these information extraction tasks. Methods: We fine-tuned a LLaMa-2 13B Chat LLM to generate a synthetic corpus containing normalized mentions of concepts from the Unified Medical Language System (UMLS) Disease Semantic Group. We measured overall and Out of Distribution (OOD) performance for DER and DEN, with and without synthetic data augmentation. We evaluated performance on 3 different disease corpora using 4 different data augmentation strategies, assessed using BioBERT for DER and SapBERT and KrissBERT for DEN. Results: Our synthetic data yielded a substantial improvement for DEN, in all 3 training corpora the top 1 accuracy of both SapBERT and KrissBERT improved by 3-9 points in overall performance and by 20-55 points in OOD data. A small improvement (1-2 points) was also seen for DER in overall performance, but only one dataset showed OOD improvement. Conclusion: LLM generation of normalized disease mentions can improve DEN relative to normalization approaches that do not utilize LLMs to augment data with synthetic mentions. Ablation studies indicate that performance gains for DEN were only partially attributable to improvements in OOD performance. The same approach has only a limited ability to improve DER. We make our software and dataset publicly available.
Wait, but Tylenol is Acetaminophen... Investigating and Improving Language Models' Ability to Resist Requests for Misinformation
Sep 30, 2024Background: Large language models (LLMs) are trained to follow directions, but this introduces a vulnerability to blindly comply with user requests even if they generate wrong information. In medicine, this could accelerate the generation of misinformation that impacts human well-being. Objectives/Methods: We analyzed compliance to requests to generate misleading content about medications in settings where models know the request is illogical. We investigated whether in-context directions and instruction-tuning of LLMs to prioritize logical reasoning over compliance reduced misinformation risk. Results: While all frontier LLMs complied with misinformation requests, both prompt-based and parameter-based approaches can improve the detection of logic flaws in requests and prevent the dissemination of medical misinformation. Conclusion: Shifting LLMs to prioritize logic over compliance could reduce risks of exploitation for medical misinformation.
To Burst or Not to Burst: Generating and Quantifying Improbable Text
Jan 27, 2024While large language models (LLMs) are extremely capable at text generation, their outputs are still distinguishable from human-authored text. We explore this separation across many metrics over text, many sampling techniques, many types of text data, and across two popular LLMs, LLaMA and Vicuna. Along the way, we introduce a new metric, recoverability, to highlight differences between human and machine text; and we propose a new sampling technique, burst sampling, designed to close this gap. We find that LLaMA and Vicuna have distinct distributions under many of the metrics, and that this influences our results: Recoverability separates real from fake text better than any other metric when using LLaMA. When using Vicuna, burst sampling produces text which is distributionally closer to real text compared to other sampling techniques.
Selecting Shots for Demographic Fairness in Few-Shot Learning with Large Language Models
Nov 14, 2023Recently, work in NLP has shifted to few-shot (in-context) learning, with large language models (LLMs) performing well across a range of tasks. However, while fairness evaluations have become a standard for supervised methods, little is known about the fairness of LLMs as prediction systems. Further, common standard methods for fairness involve access to models weights or are applied during finetuning, which are not applicable in few-shot learning. Do LLMs exhibit prediction biases when used for standard NLP tasks? In this work, we explore the effect of shots, which directly affect the performance of models, on the fairness of LLMs as NLP classification systems. We consider how different shot selection strategies, both existing and new demographically sensitive methods, affect model fairness across three standard fairness datasets. We discuss how future work can include LLM fairness evaluations.