 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Bias in Vision Language Models: Signposts, Pitfalls, and the Road Ahead
Oct 17, 2024


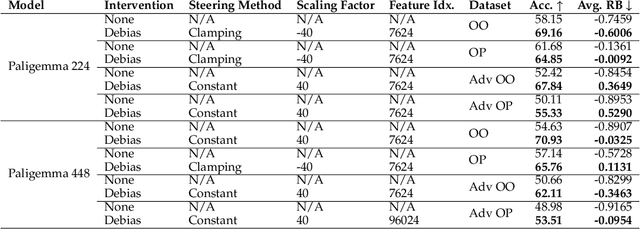
As Vision Language Models (VLMs) gain widespread use, their fairness remains under-explored. In this paper, we analyze demographic biases across five models and six datasets. We find that portrait datasets like UTKFace and CelebA are the best tools for bias detection, finding gaps in performance and fairness between LLaVa and CLIP models. However, scene based datasets like PATA, VLStereoSet fail to be useful benchmarks for bias due to their construction. As for pronoun based datasets like VisoGender, we receive mixed signals as only some subsets of the data are useful in providing insights. To alleviate this problem, we introduce a more difficult version of VisoGender to serve as a more rigorous evaluation. Based on these results, we call for more effective and carefully designed datasets to ensure VLMs are both fair and reliable.