 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Bias in Vision Language Models: Signposts, Pitfalls, and the Road Ahead
Oct 17, 2024


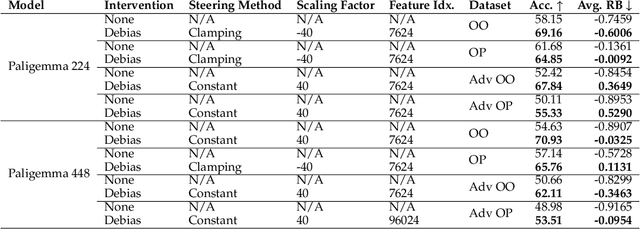
As Vision Language Models (VLMs) gain widespread use, their fairness remains under-explored. In this paper, we analyze demographic biases across five models and six datasets. We find that portrait datasets like UTKFace and CelebA are the best tools for bias detection, finding gaps in performance and fairness between LLaVa and CLIP models. However, scene based datasets like PATA, VLStereoSet fail to be useful benchmarks for bias due to their construction. As for pronoun based datasets like VisoGender, we receive mixed signals as only some subsets of the data are useful in providing insights. To alleviate this problem, we introduce a more difficult version of VisoGender to serve as a more rigorous evaluation. Based on these results, we call for more effective and carefully designed datasets to ensure VLMs are both fair and reliable.
Language Models are Surprisingly Fragile to Drug Names in Biomedical Benchmarks
Jun 17, 2024Medical knowledge is context-dependent and requires consistent reasoning across various natural language expressions of semantically equivalent phrases. This is particularly crucial for drug names, where patients often use brand names like Advil or Tylenol instead of their generic equivalents. To study this, we create a new robustness dataset, RABBITS, to evaluate performance differences on medical benchmarks after swapping brand and generic drug names using physician expert annotations. We assess both open-source and API-based LLMs on MedQA and MedMCQA, revealing a consistent performance drop ranging from 1-10\%. Furthermore, we identify a potential source of this fragility as the contamination of test data in widely used pre-training datasets. All code is accessible at https://github.com/BittermanLab/RABBITS, and a HuggingFace leaderboard is available at https://huggingface.co/spaces/AIM-Harvard/rabbits-leaderboard.