 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Hybrid Captioner for Improved Long-form Video Understanding
Jul 22, 2025Video data, especially long-form video, is extremely dense and high-dimensional. Text-based summaries of video content offer a way to represent query-relevant content in a much more compact manner than raw video. In addition, textual representations are easily ingested by state-of-the-art large language models (LLMs), which enable reasoning over video content to answer complex natural language queries. To solve this issue, we rely on the progressive construction of a text-based memory by a video captioner operating on shorter chunks of the video, where spatio-temporal modeling is computationally feasible. We explore ways to improve the quality of the activity log comprised solely of short video captions. Because the video captions tend to be focused on human actions, and questions may pertain to other information in the scene, we seek to enrich the memory with static scene descriptions using Vision Language Models (VLMs). Our video understanding system relies on the LaViLa video captioner in combination with a LLM to answer questions about videos. We first explored different ways of partitioning the video into meaningful segments such that the textual descriptions more accurately reflect the structure of the video content. Furthermore, we incorporated static scene descriptions into the captioning pipeline using LLaVA VLM, resulting in a more detailed and complete caption log and expanding the space of questions that are answerable from the textual memory. Finally, we have successfully fine-tuned the LaViLa video captioner to produce both action and scene captions, significantly improving the efficiency of the captioning pipeline compared to using separate captioning models for the two tasks. Our model, controllable hybrid captioner, can alternate between different types of captions according to special input tokens that signals scene changes detected in the video.
To Burst or Not to Burst: Generating and Quantifying Improbable Text
Jan 27, 2024



While large language models (LLMs) are extremely capable at text generation, their outputs are still distinguishable from human-authored text. We explore this separation across many metrics over text, many sampling techniques, many types of text data, and across two popular LLMs, LLaMA and Vicuna. Along the way, we introduce a new metric, recoverability, to highlight differences between human and machine text; and we propose a new sampling technique, burst sampling, designed to close this gap. We find that LLaMA and Vicuna have distinct distributions under many of the metrics, and that this influences our results: Recoverability separates real from fake text better than any other metric when using LLaMA. When using Vicuna, burst sampling produces text which is distributionally closer to real text compared to other sampling techniques.
Answer Span Correction in Machine Reading Comprehension
Nov 06, 2020

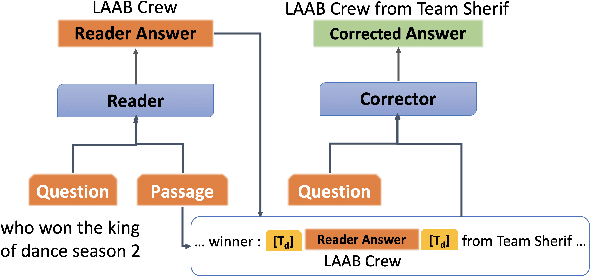

Answer validation in machine reading comprehension (MRC) consists of verifying an extracted answer against an input context and question pair. Previous work has looked at re-assessing the "answerability" of the question given the extracted answer. Here we address a different problem: the tendency of existing MRC systems to produce partially correct answers when presented with answerable questions. We explore the nature of such errors and propose a post-processing correction method that yields statistically significant performance improvements over state-of-the-art MRC systems in both monolingual and multilingual evaluation.
Multi-Stage Pre-training for Low-Resource Domain Adaptation
Oct 12, 2020
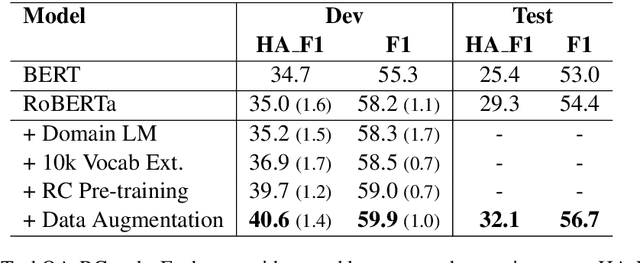
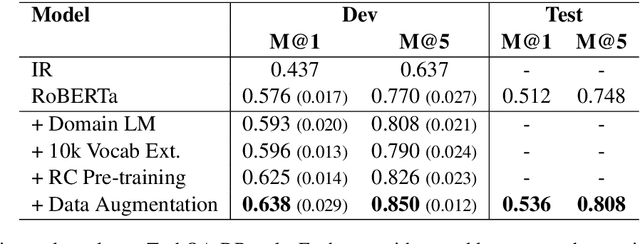
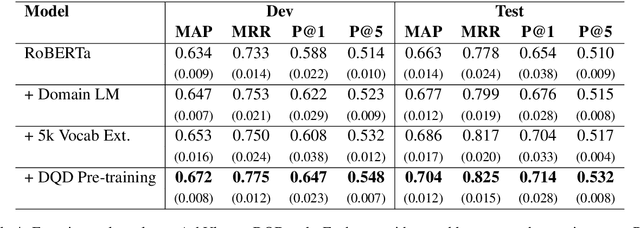
Transfer learning techniques are particularly useful in NLP tasks where a sizable amount of high-quality annotated data is difficult to obtain. Current approaches directly adapt a pre-trained language model (LM) on in-domain text before fine-tuning to downstream tasks. We show that extending the vocabulary of the LM with domain-specific terms leads to further gains. To a bigger effect, we utilize structure in the unlabeled data to create auxiliary synthetic tasks, which helps the LM transfer to downstream tasks. We apply these approaches incrementally on a pre-trained Roberta-large LM and show considerable performance gain on three tasks in the IT domain: Extractive Reading Comprehension, Document Ranking and Duplicate Question Detection.
Predictive Linguistic Features of Schizophrenia
Oct 22, 2018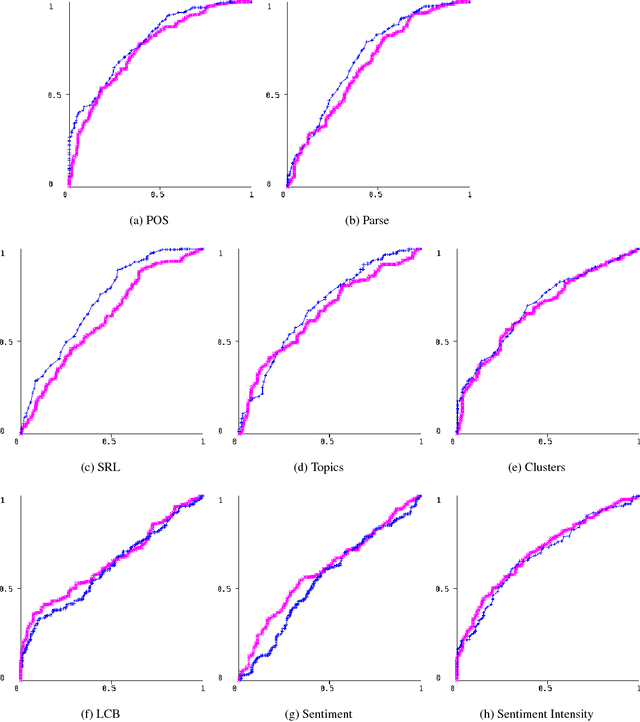

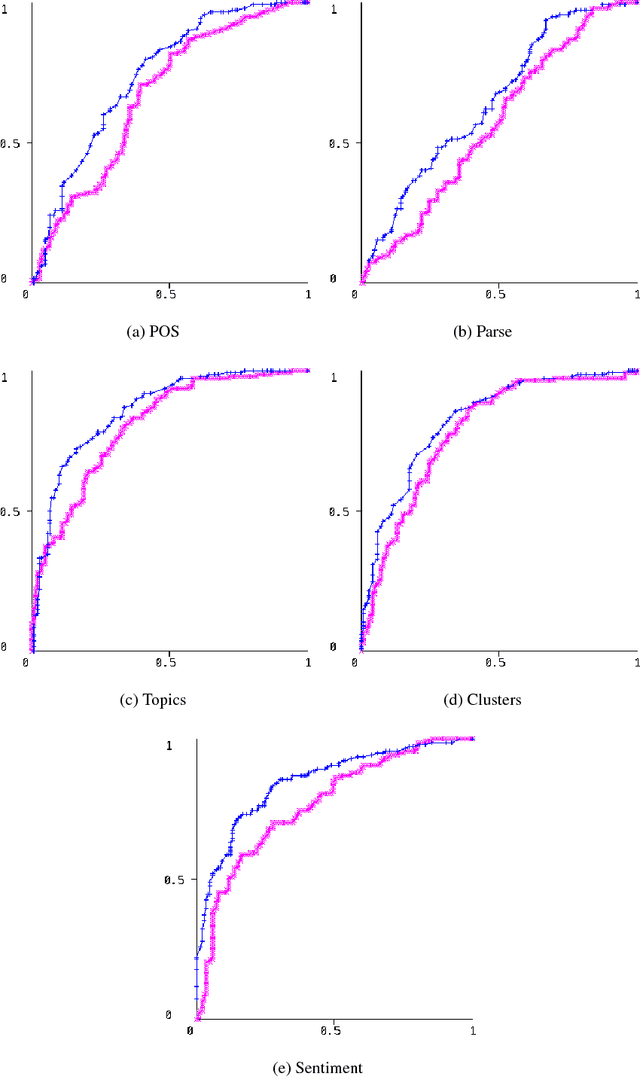
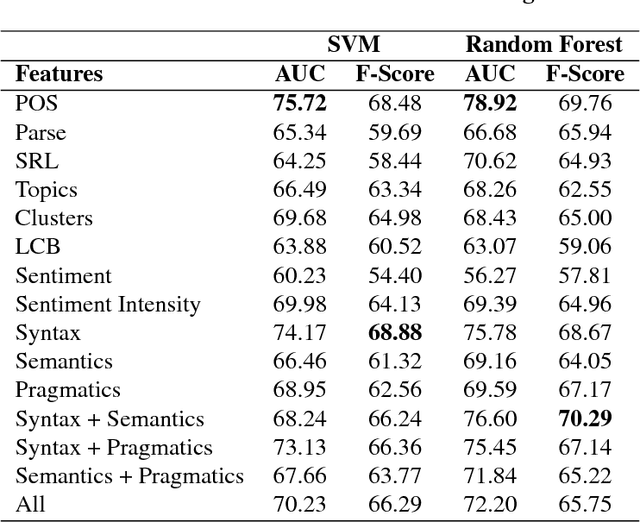
Schizophrenia is one of the most disabling and difficult to treat of all human medical/health conditions, ranking in the top ten causes of disability worldwide. It has been a puzzle in part due to difficulty in identifying its basic, fundamental components. Several studies have shown that some manifestations of schizophrenia (e.g., the negative symptoms that include blunting of speech prosody, as well as the disorganization symptoms that lead to disordered language) can be understood from the perspective of linguistics. However, schizophrenia research has not kept pace with technologies in computational linguistics, especially in semantics and pragmatics. As such, we examine the writings of schizophrenia patients analyzing their syntax, semantics and pragmatics. In addition, we analyze tweets of (self pro-claimed) schizophrenia patients who publicly discuss their diagnoses. For writing samples dataset, syntactic features are found to be the most successful in classification whereas for the less structured Twitter dataset, a combination of features performed the best.
Topic Modeling for Classification of Clinical Reports
Jun 19, 2017
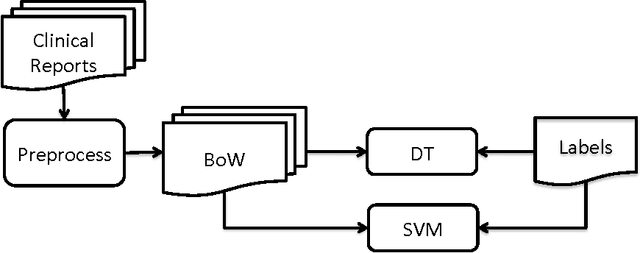
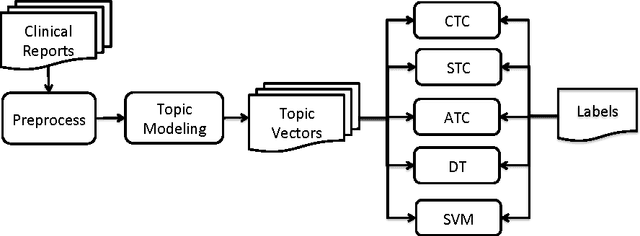
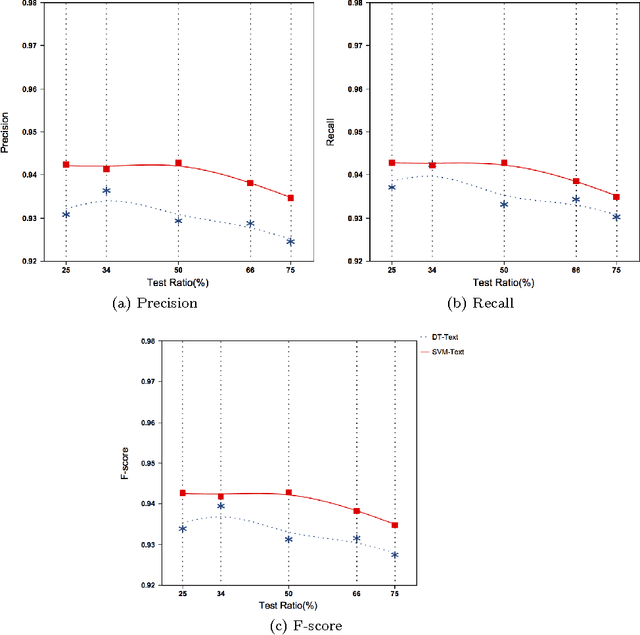
Electronic health records (EHRs) contain important clinical information about patients. Efficient and effective use of this information could supplement or even replace manual chart review as a means of studying and improving the quality and safety of healthcare delivery. However, some of these clinical data are in the form of free text and require pre-processing before use in automated systems. A common free text data source is radiology reports, typically dictated by radiologists to explain their interpretations. We sought to demonstrate machine learning classification of computed tomography (CT) imaging reports into binary outcomes, i.e. positive and negative for fracture, using regular text classification and classifiers based on topic modeling. Topic modeling provides interpretable themes (topic distributions) in reports, a representation that is more compact than the commonly used bag-of-words representation and can be processed faster than raw text in subsequent automated processes. We demonstrate new classifiers based on this topic modeling representation of the reports. Aggregate topic classifier (ATC) and confidence-based topic classifier (CTC) use a single topic that is determined from the training dataset based on different measures to classify the reports on the test dataset. Alternatively, similarity-based topic classifier (STC) measures the similarity between the reports' topic distributions to determine the predicted class. Our proposed topic modeling-based classifier systems are shown to be competitive with existing text classification techniques and provides an efficient and interpretable representation.