Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer Span Correction in Machine Reading Comprehension
Paper and Code
Nov 06, 2020

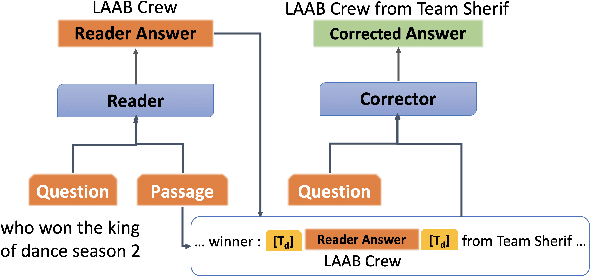

Answer validation in machine reading comprehension (MRC) consists of verifying an extracted answer against an input context and question pair. Previous work has looked at re-assessing the "answerability" of the question given the extracted answer. Here we address a different problem: the tendency of existing MRC systems to produce partially correct answers when presented with answerable questions. We explore the nature of such errors and propose a post-processing correction method that yields statistically significant performance improvements over state-of-the-art MRC systems in both monolingual and multilingual evaluation.
* Accepted in Findings of EMNLP 2020
View paper on