 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Linguistic Features of Schizophrenia
Oct 22, 2018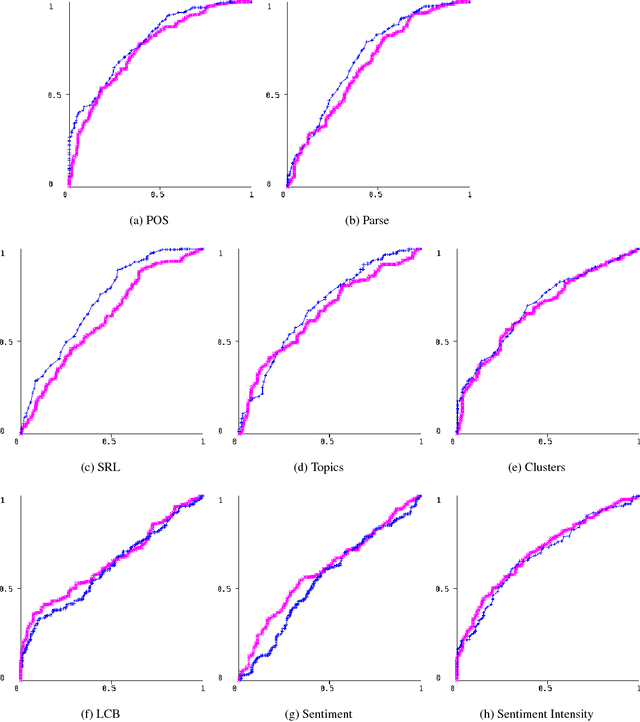

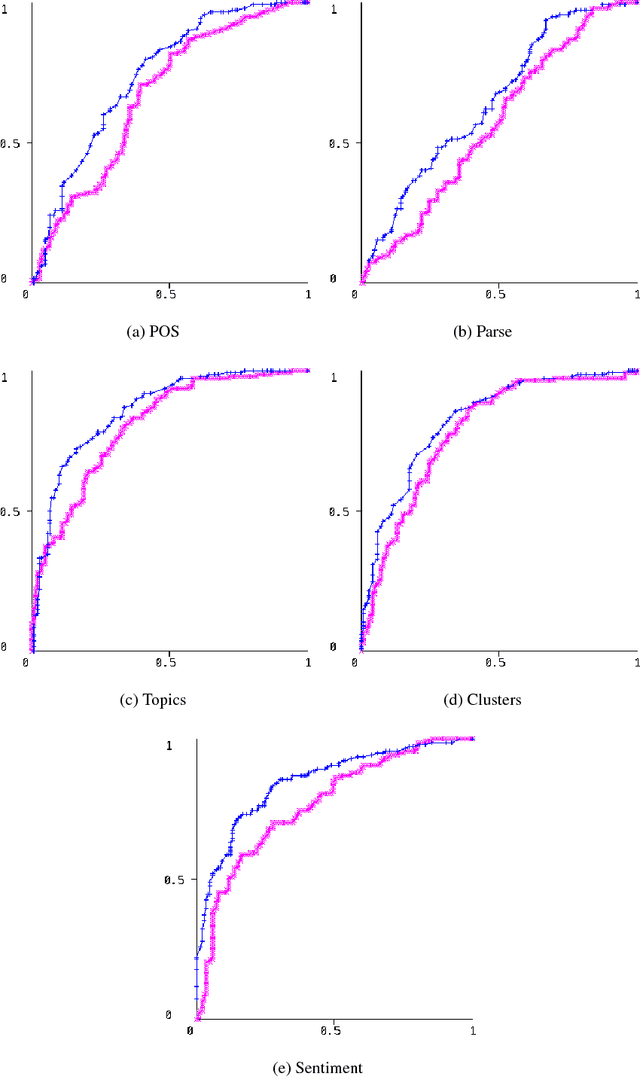
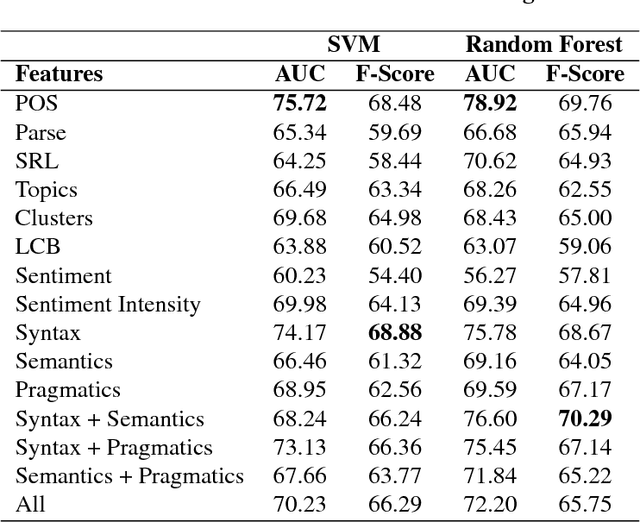
Schizophrenia is one of the most disabling and difficult to treat of all human medical/health conditions, ranking in the top ten causes of disability worldwide. It has been a puzzle in part due to difficulty in identifying its basic, fundamental components. Several studies have shown that some manifestations of schizophrenia (e.g., the negative symptoms that include blunting of speech prosody, as well as the disorganization symptoms that lead to disordered language) can be understood from the perspective of linguistics. However, schizophrenia research has not kept pace with technologies in computational linguistics, especially in semantics and pragmatics. As such, we examine the writings of schizophrenia patients analyzing their syntax, semantics and pragmatics. In addition, we analyze tweets of (self pro-claimed) schizophrenia patients who publicly discuss their diagnoses. For writing samples dataset, syntactic features are found to be the most successful in classification whereas for the less structured Twitter dataset, a combination of features performed the best.
Quantifying Mental Health from Social Media with Neural User Embeddings
Apr 30, 2017
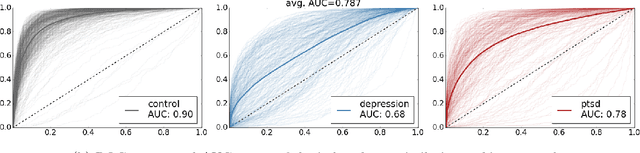

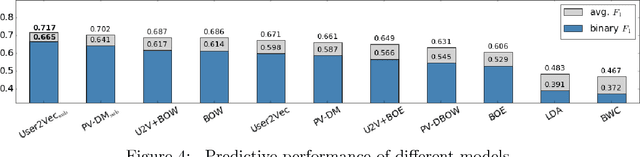
Mental illnesses adversely affect a significant proportion of the population worldwide. However, the methods traditionally used for estimating and characterizing the prevalence of mental health conditions are time-consuming and expensive. Consequently, best-available estimates concerning the prevalence of mental health conditions are often years out of date. Automated approaches to supplement these survey methods with broad, aggregated information derived from social media content provides a potential means for near real-time estimates at scale. These may, in turn, provide grist for supporting, evaluating and iteratively improving upon public health programs and interventions. We propose a novel model for automated mental health status quantification that incorporates user embeddings. This builds upon recent work exploring representation learning methods that induce embeddings by leveraging social media post histories. Such embeddings capture latent characteristics of individuals (e.g., political leanings) and encode a soft notion of homophily. In this paper, we investigate whether user embeddings learned from twitter post histories encode information that correlates with mental health statuses. To this end, we estimated user embeddings for a set of users known to be affected by depression and post-traumatic stress disorder (PTSD), and for a set of demographically matched `control' users. We then evaluated these embeddings with respect to: (i) their ability to capture homophilic relations with respect to mental health status; and (ii) the performance of downstream mental health prediction models based on these features. Our experimental results demonstrate that the user embeddings capture similarities between users with respect to mental conditions, and are predictive of mental health.