 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND - Mainstream and Independent News Documents Corpus
Aug 13, 2021
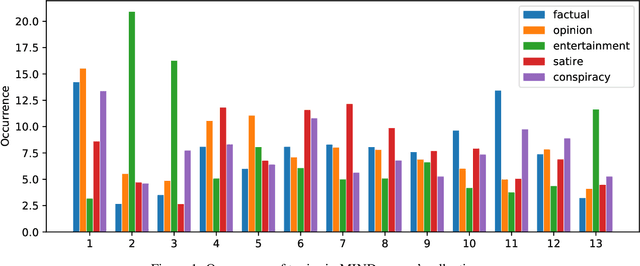


This paper presents and characterizes MIND, a new Portuguese corpus comprised of different types of articles collected from online mainstream and alternative media sources, over a 10-month period. The articles in the corpus are organized into five collections: facts, opinions, entertainment, satires, and conspiracy theories. Throughout this paper, we explain how the data collection process was conducted, and present a set of linguistic metrics that allow us to perform a preliminary characterization of the texts included in the corpus. Also, we deliver an analysis of the most frequent topics in the corpus, and discuss the main differences and similarities among the collections considered. Finally, we enumerate some tasks and applications that could benefit from this corpus, in particular the ones (in)directly related to misinformation detection. Overall, our contribution of a corpus and initial analysis are designed to support future exploratory news studies, and provide a better insight into misinformation.
Quantifying Mental Health from Social Media with Neural User Embeddings
Apr 30, 2017
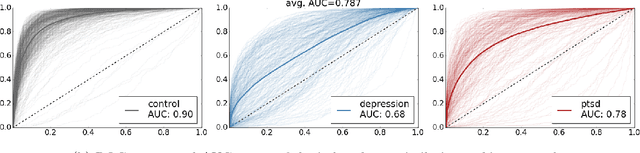

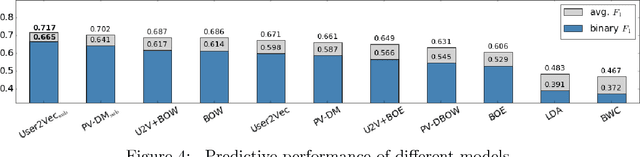
Mental illnesses adversely affect a significant proportion of the population worldwide. However, the methods traditionally used for estimating and characterizing the prevalence of mental health conditions are time-consuming and expensive. Consequently, best-available estimates concerning the prevalence of mental health conditions are often years out of date. Automated approaches to supplement these survey methods with broad, aggregated information derived from social media content provides a potential means for near real-time estimates at scale. These may, in turn, provide grist for supporting, evaluating and iteratively improving upon public health programs and interventions. We propose a novel model for automated mental health status quantification that incorporates user embeddings. This builds upon recent work exploring representation learning methods that induce embeddings by leveraging social media post histories. Such embeddings capture latent characteristics of individuals (e.g., political leanings) and encode a soft notion of homophily. In this paper, we investigate whether user embeddings learned from twitter post histories encode information that correlates with mental health statuses. To this end, we estimated user embeddings for a set of users known to be affected by depression and post-traumatic stress disorder (PTSD), and for a set of demographically matched `control' users. We then evaluated these embeddings with respect to: (i) their ability to capture homophilic relations with respect to mental health status; and (ii) the performance of downstream mental health prediction models based on these features. Our experimental results demonstrate that the user embeddings capture similarities between users with respect to mental conditions, and are predictive of mental health.
Expanding Subjective Lexicons for Social Media Mining with Embedding Subspaces
Jan 06, 2017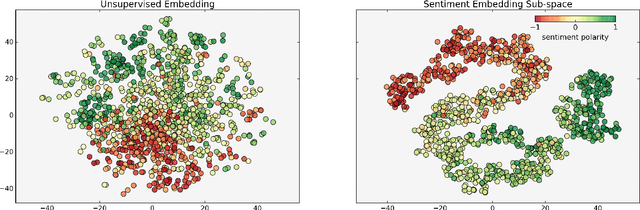
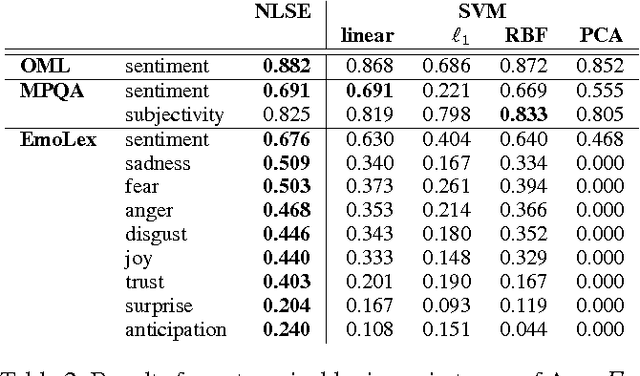
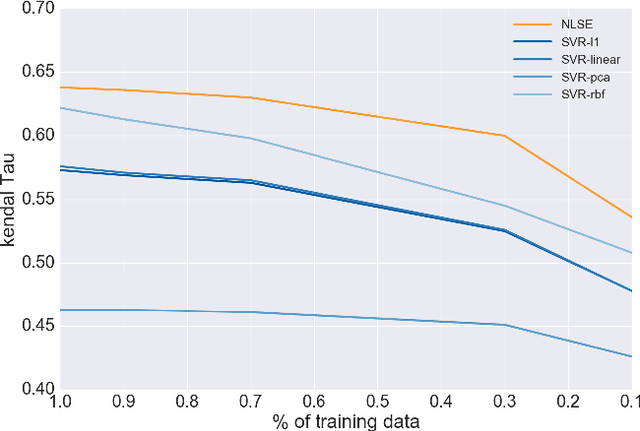
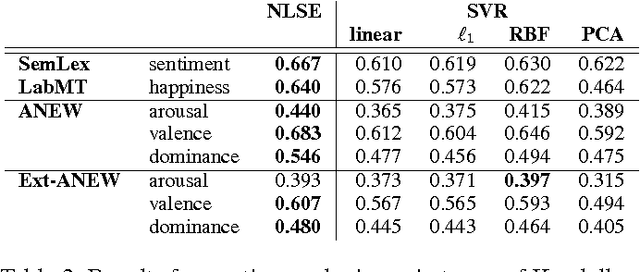
Recent approaches for sentiment lexicon induction have capitalized on pre-trained word embeddings that capture latent semantic properties. However, embeddings obtained by optimizing performance of a given task (e.g. predicting contextual words) are sub-optimal for other applications. In this paper, we address this problem by exploiting task-specific representations, induced via embedding sub-space projection. This allows us to expand lexicons describing multiple semantic properties. For each property, our model jointly learns suitable representations and the concomitant predictor. Experiments conducted over multiple subjective lexicons, show that our model outperforms previous work and other baselines; even in low training data regimes. Furthermore, lexicon-based sentiment classifiers built on top of our lexicons outperform similar resources and yield performances comparable to those of supervised models.