 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND - Mainstream and Independent News Documents Corpus
Paper and Code
Aug 13, 2021
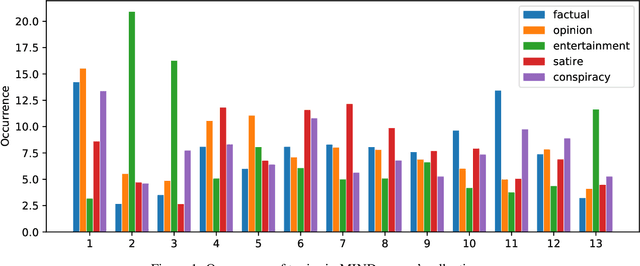


This paper presents and characterizes MIND, a new Portuguese corpus comprised of different types of articles collected from online mainstream and alternative media sources, over a 10-month period. The articles in the corpus are organized into five collections: facts, opinions, entertainment, satires, and conspiracy theories. Throughout this paper, we explain how the data collection process was conducted, and present a set of linguistic metrics that allow us to perform a preliminary characterization of the texts included in the corpus. Also, we deliver an analysis of the most frequent topics in the corpus, and discuss the main differences and similarities among the collections considered. Finally, we enumerate some tasks and applications that could benefit from this corpus, in particular the ones (in)directly related to misinformation detection. Overall, our contribution of a corpus and initial analysis are designed to support future exploratory news studies, and provide a better insight into misinformation.