 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD for Robust Reinforcement Learning in Machine Translation
Jul 18, 2022
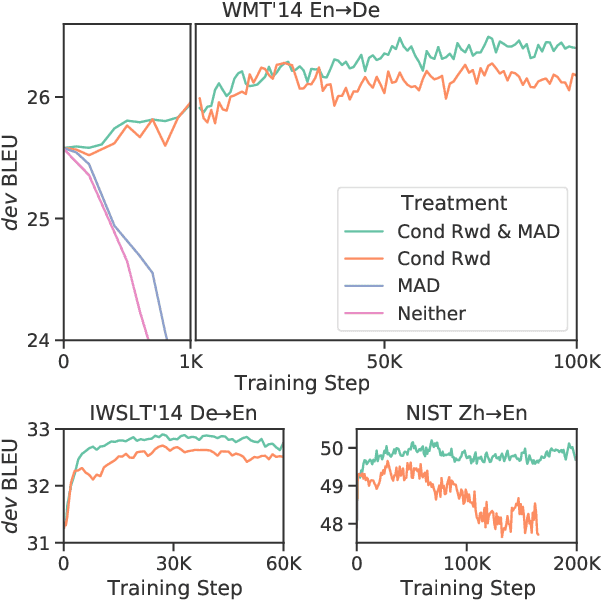

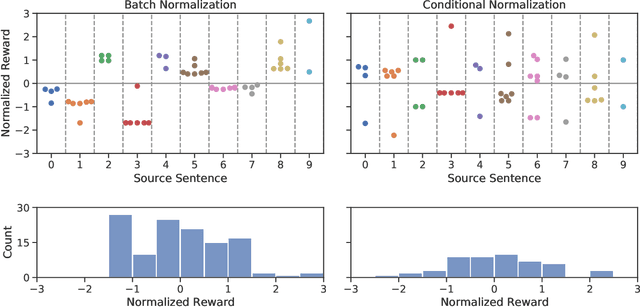
We introduce a new distributed policy gradient algorithm and show that it outperforms existing reward-aware training procedures such as REINFORCE, minimum risk training (MRT) and proximal policy optimization (PPO) in terms of training stability and generalization performance when optimizing machine translation models. Our algorithm, which we call MAD (on account of using the mean absolute deviation in the importance weighting calculation), has distributed data generators sampling multiple candidates per source sentence on worker nodes, while a central learner updates the policy. MAD depends crucially on two variance reduction strategies: (1) a conditional reward normalization method that ensures each source sentence has both positive and negative reward translation examples and (2) a new robust importance weighting scheme that acts as a conditional entropy regularizer. Experiments on a variety of translation tasks show that policies learned using the MAD algorithm perform very well when using both greedy decoding and beam search, and that the learned policies are sensitive to the specific reward used during training.
Enabling arbitrary translation objectives with Adaptive Tree Search
Feb 23, 2022
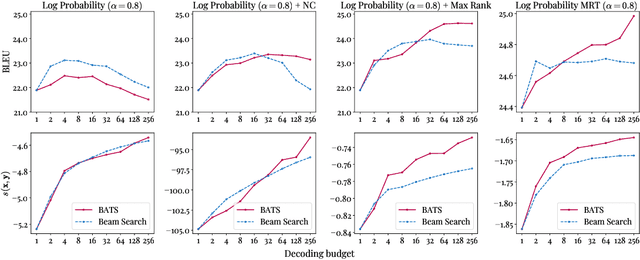
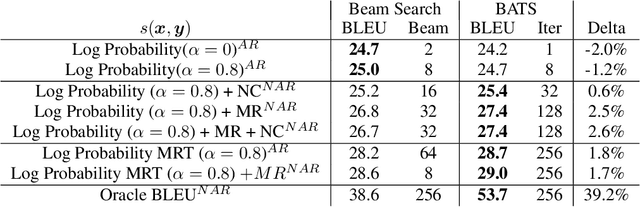
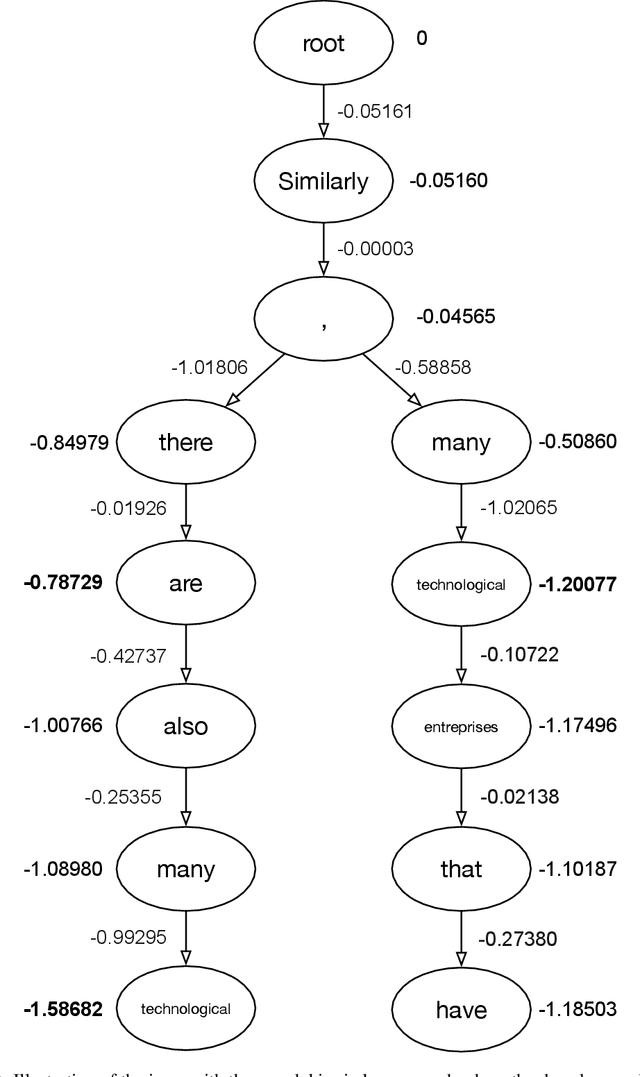
We introduce an adaptive tree search algorithm, that can find high-scoring outputs under translation models that make no assumptions about the form or structure of the search objective. This algorithm -- a deterministic variant of Monte Carlo tree search -- enables the exploration of new kinds of models that are unencumbered by constraints imposed to make decoding tractable, such as autoregressivity or conditional independence assumptions. When applied to autoregressive models, our algorithm has different biases than beam search has, which enables a new analysis of the role of decoding bias in autoregressive models. Empirically, we show that our adaptive tree search algorithm finds outputs with substantially better model scores compared to beam search in autoregressive models, and compared to reranking techniques in models whose scores do not decompose additively with respect to the words in the output. We also characterise the correlation of several translation model objectives with respect to BLEU. We find that while some standard models are poorly calibrated and benefit from the beam search bias, other often more robust models (autoregressive models tuned to maximize expected automatic metric scores, the noisy channel model and a newly proposed objective) benefit from increasing amounts of search using our proposed decoder, whereas the beam search bias limits the improvements obtained from such objectives. Thus, we argue that as models improve, the improvements may be masked by over-reliance on beam search or reranking based methods.
A Mutual Information Maximization Perspective of Language Representation Learning
Nov 26, 2019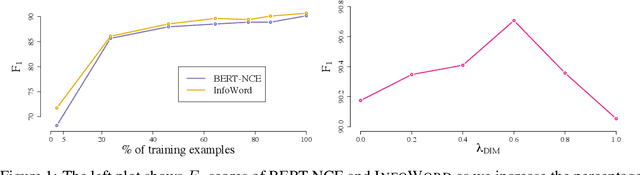
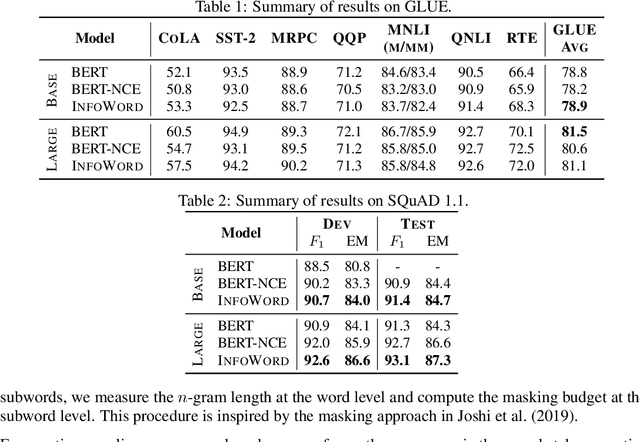
We show state-of-the-art word representation learning methods maximize an objective function that is a lower bound on the mutual information between different parts of a word sequence (i.e., a sentence). Our formulation provides an alternative perspective that unifies classical word embedding models (e.g., Skip-gram) and modern contextual embeddings (e.g., BERT, XLNet). In addition to enhancing our theoretical understanding of these methods, our derivation leads to a principled framework that can be used to construct new self-supervised tasks. We provide an example by drawing inspirations from related methods based on mutual information maximization that have been successful in computer vision, and introduce a simple self-supervised objective that maximizes the mutual information between a global sentence representation and n-grams in the sentence. Our analysis offers a holistic view of representation learning methods to transfer knowledge and translate progress across multiple domains (e.g., natural language processing, computer vision, audio processing).
Putting Machine Translation in Context with the Noisy Channel Model
Oct 01, 2019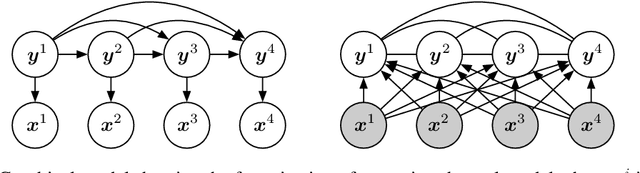
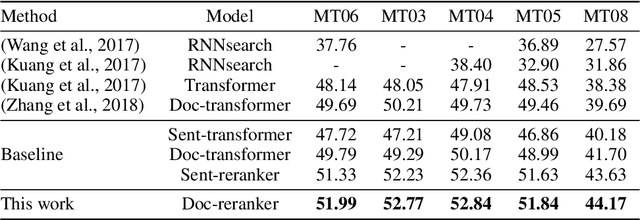
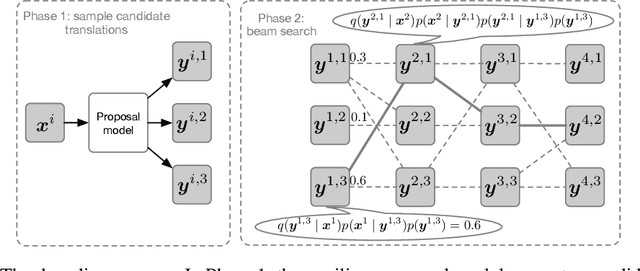

We show that Bayes' rule provides a compelling mechanism for controlling unconditional document language models, using the long-standing challenge of effectively leveraging document context in machine translation. In our formulation, we estimate the probability of a candidate translation as the product of the unconditional probability of the candidate output document and the ``reverse translation probability'' of translating the candidate output back into the input source language document---the so-called ``noisy channel'' decomposition. A particular advantage of our model is that it requires only parallel sentences to train, rather than parallel documents, which are not always available. Using a new beam search reranking approximation to solve the decoding problem, we find that document language models outperform language models that assume independence between sentences, and that using either a document or sentence language model outperforms comparable models that directly estimate the translation probability. We obtain the best-published results on the NIST Chinese--English translation task, a standard task for evaluating document translation. Our model also outperforms the benchmark Transformer model by approximately 2.5 BLEU on the WMT19 Chinese--English translation task.
Learning and Evaluating General Linguistic Intelligence
Jan 31, 2019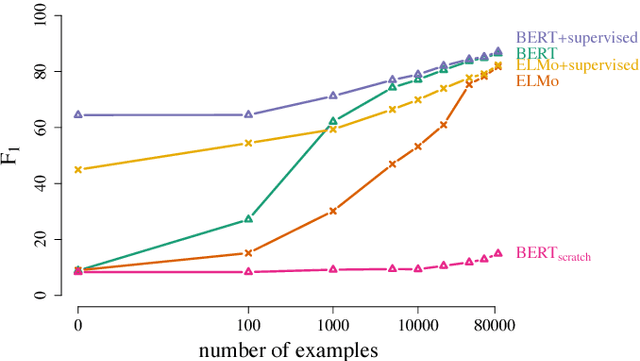
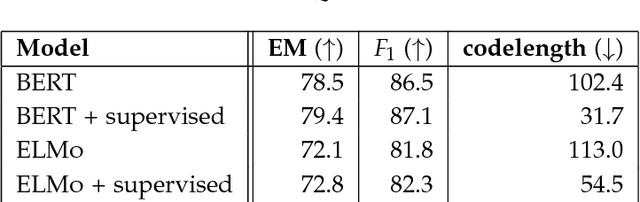
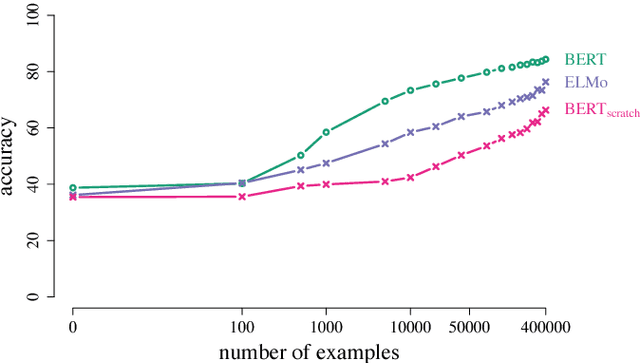

We define general linguistic intelligence as the ability to reuse previously acquired knowledge about a language's lexicon, syntax, semantics, and pragmatic conventions to adapt to new tasks quickly. Using this definition, we analyze state-of-the-art natural language understanding models and conduct an extensive empirical investigation to evaluate them against these criteria through a series of experiments that assess the task-independence of the knowledge being acquired by the learning process. In addition to task performance, we propose a new evaluation metric based on an online encoding of the test data that quantifies how quickly an existing agent (model) learns a new task. Our results show that while the field has made impressive progress in terms of model architectures that generalize to many tasks, these models still require a lot of in-domain training examples (e.g., for fine tuning, training task-specific modules), and are prone to catastrophic forgetting. Moreover, we find that far from solving general tasks (e.g., document question answering), our models are overfitting to the quirks of particular datasets (e.g., SQuAD). We discuss missing components and conjecture on how to make progress toward general linguistic intelligence.
Variational Smoothing in Recurrent Neural Network Language Models
Jan 27, 2019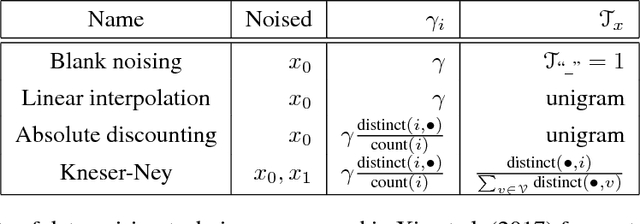

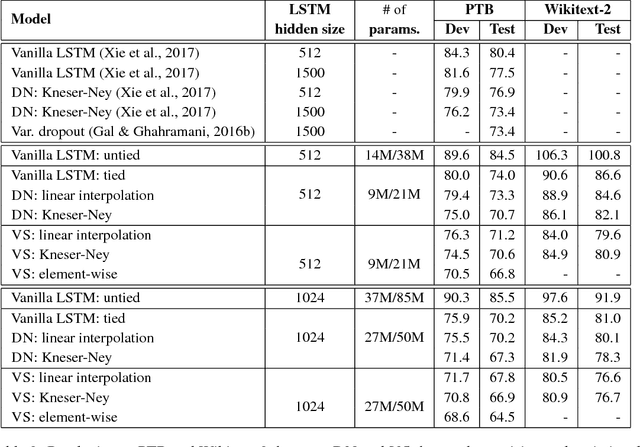
We present a new theoretical perspective of data noising in recurrent neural network language models (Xie et al., 2017). We show that each variant of data noising is an instance of Bayesian recurrent neural networks with a particular variational distribution (i.e., a mixture of Gaussians whose weights depend on statistics derived from the corpus such as the unigram distribution). We use this insight to propose a more principled method to apply at prediction time and propose natural extensions to data noising under the variational framework. In particular, we propose variational smoothing with tied input and output embedding matrices and an element-wise variational smoothing method. We empirically verify our analysis on two benchmark language modeling datasets and demonstrate performance improvements over existing data noising methods.
Sentence Encoding with Tree-constrained Relation Networks
Nov 26, 2018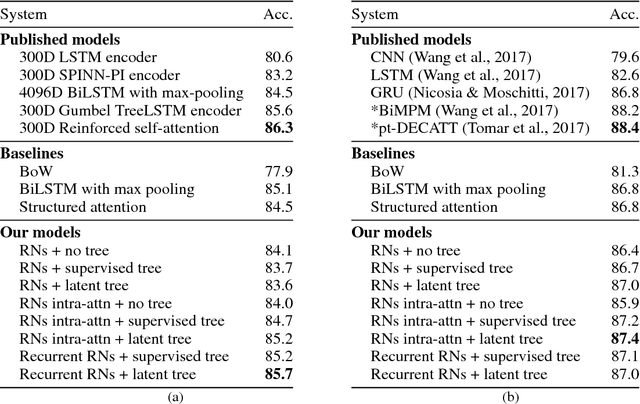

The meaning of a sentence is a function of the relations that hold between its words. We instantiate this relational view of semantics in a series of neural models based on variants of relation networks (RNs) which represent a set of objects (for us, words forming a sentence) in terms of representations of pairs of objects. We propose two extensions to the basic RN model for natural language. First, building on the intuition that not all word pairs are equally informative about the meaning of a sentence, we use constraints based on both supervised and unsupervised dependency syntax to control which relations influence the representation. Second, since higher-order relations are poorly captured by a sum of pairwise relations, we use a recurrent extension of RNs to propagate information so as to form representations of higher order relations. Experiments on sentence classification, sentence pair classification, and machine translation reveal that, while basic RNs are only modestly effective for sentence representation, recurrent RNs with latent syntax are a reliably powerful representational device.
Program Induction by Rationale Generation : Learning to Solve and Explain Algebraic Word Problems
Oct 23, 2017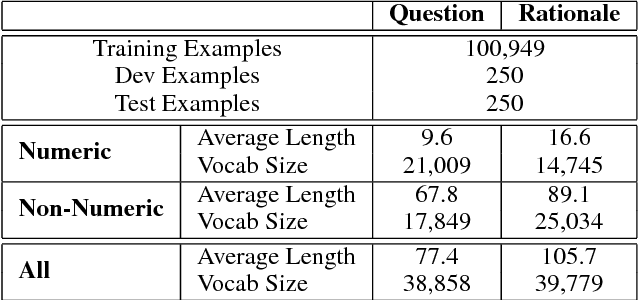
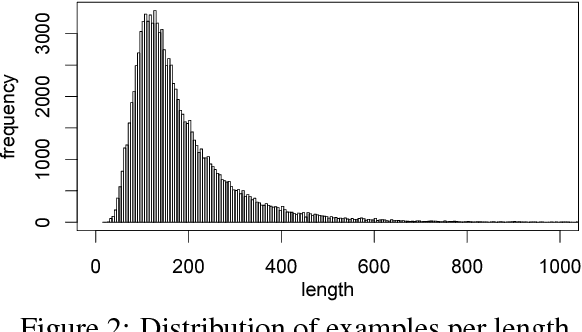


Solving algebraic word problems requires executing a series of arithmetic operations---a program---to obtain a final answer. However, since programs can be arbitrarily complicated, inducing them directly from question-answer pairs is a formidable challenge. To make this task more feasible, we solve these problems by generating answer rationales, sequences of natural language and human-readable mathematical expressions that derive the final answer through a series of small steps. Although rationales do not explicitly specify programs, they provide a scaffolding for their structure via intermediate milestones. To evaluate our approach, we have created a new 100,000-sample dataset of questions, answers and rationales. Experimental results show that indirect supervision of program learning via answer rationales is a promising strategy for inducing arithmetic programs.
Reference-Aware Language Models
Aug 09, 2017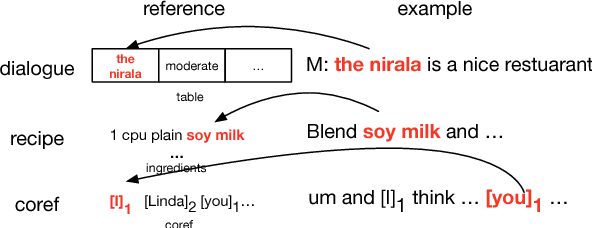



We propose a general class of language models that treat reference as an explicit stochastic latent variable. This architecture allows models to create mentions of entities and their attributes by accessing external databases (required by, e.g., dialogue generation and recipe generation) and internal state (required by, e.g. language models which are aware of coreference). This facilitates the incorporation of information that can be accessed in predictable locations in databases or discourse context, even when the targets of the reference may be rare words. Experiments on three tasks shows our model variants based on deterministic attention.
Generative and Discriminative Text Classification with Recurrent Neural Networks
May 26, 2017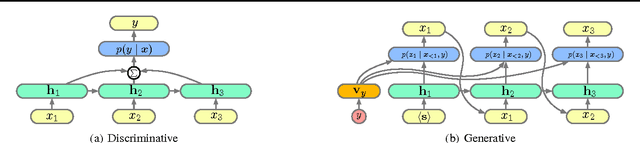
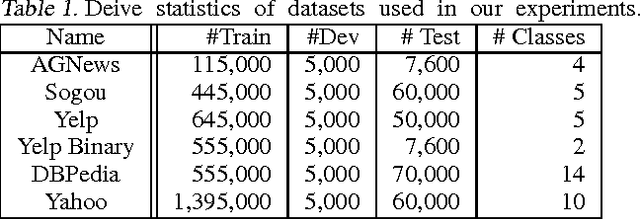

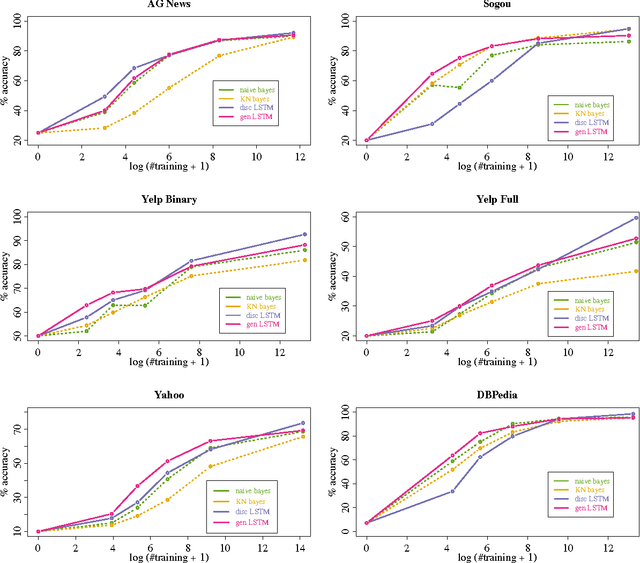
We empirically characterize the performance of discriminative and generative LSTM models for text classification. We find that although RNN-based generative models are more powerful than their bag-of-words ancestors (e.g., they account for conditional dependencies across words in a document), they have higher asymptotic error rates than discriminatively trained RNN models. However we also find that generative models approach their asymptotic error rate more rapidly than their discriminative counterparts---the same pattern that Ng & Jordan (2001) proved holds for linear classification models that make more naive conditional independence assumptions. Building on this finding, we hypothesize that RNN-based generative classification models will be more robust to shifts in the data distribution. This hypothesis is confirmed in a series of experiments in zero-shot and continual learning settings that show that generative models substantially outperform discriminative models.