 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy of Industrial Scale Multilingual ASR
Apr 16, 2024
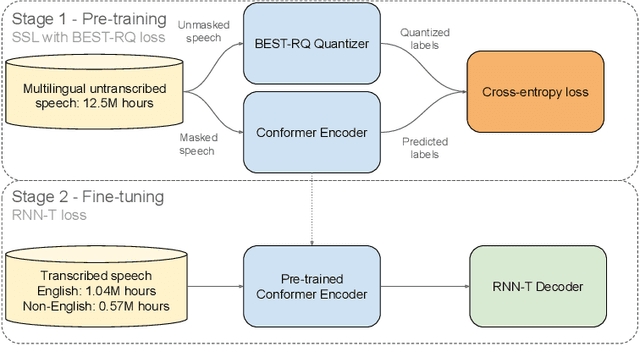


This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
Conformer-1: Robust ASR via Large-Scale Semisupervised Bootstrapping
Apr 12, 2024



This paper presents Conformer-1, an end-to-end Automatic Speech Recognition (ASR) model trained on an extensive dataset of 570k hours of speech audio data, 91% of which was acquired from publicly available sources. To achieve this, we perform Noisy Student Training after generating pseudo-labels for the unlabeled public data using a strong Conformer RNN-T baseline model. The addition of these pseudo-labeled data results in remarkable improvements in relative Word Error Rate (WER) by 11.5% and 24.3% for our asynchronous and realtime models, respectively. Additionally, the model is more robust to background noise owing to the addition of these data. The results obtained in this study demonstrate that the incorporation of pseudo-labeled publicly available data is a highly effective strategy for improving ASR accuracy and noise robustness.
MAD for Robust Reinforcement Learning in Machine Translation
Jul 18, 2022
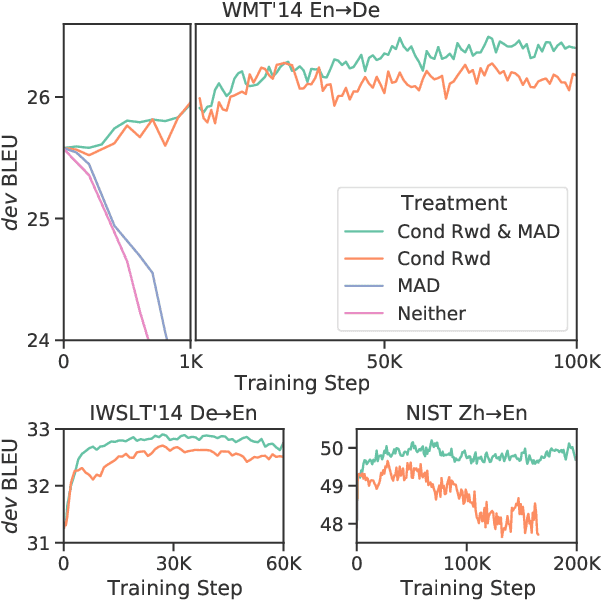

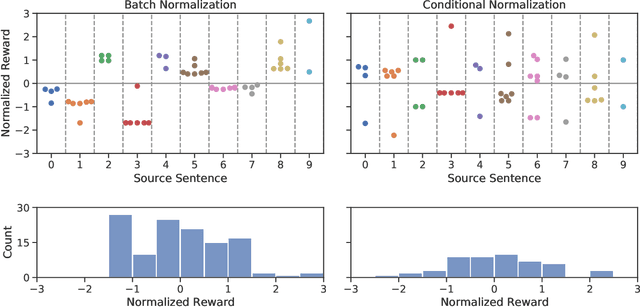
We introduce a new distributed policy gradient algorithm and show that it outperforms existing reward-aware training procedures such as REINFORCE, minimum risk training (MRT) and proximal policy optimization (PPO) in terms of training stability and generalization performance when optimizing machine translation models. Our algorithm, which we call MAD (on account of using the mean absolute deviation in the importance weighting calculation), has distributed data generators sampling multiple candidates per source sentence on worker nodes, while a central learner updates the policy. MAD depends crucially on two variance reduction strategies: (1) a conditional reward normalization method that ensures each source sentence has both positive and negative reward translation examples and (2) a new robust importance weighting scheme that acts as a conditional entropy regularizer. Experiments on a variety of translation tasks show that policies learned using the MAD algorithm perform very well when using both greedy decoding and beam search, and that the learned policies are sensitive to the specific reward used during training.
Enabling arbitrary translation objectives with Adaptive Tree Search
Feb 23, 2022
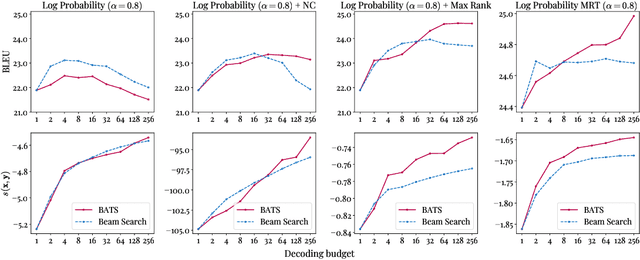
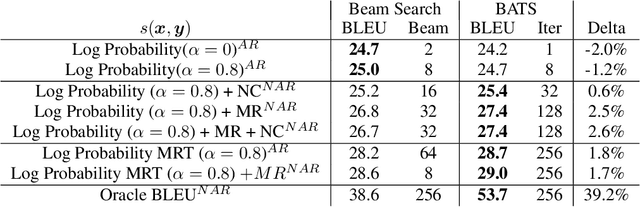
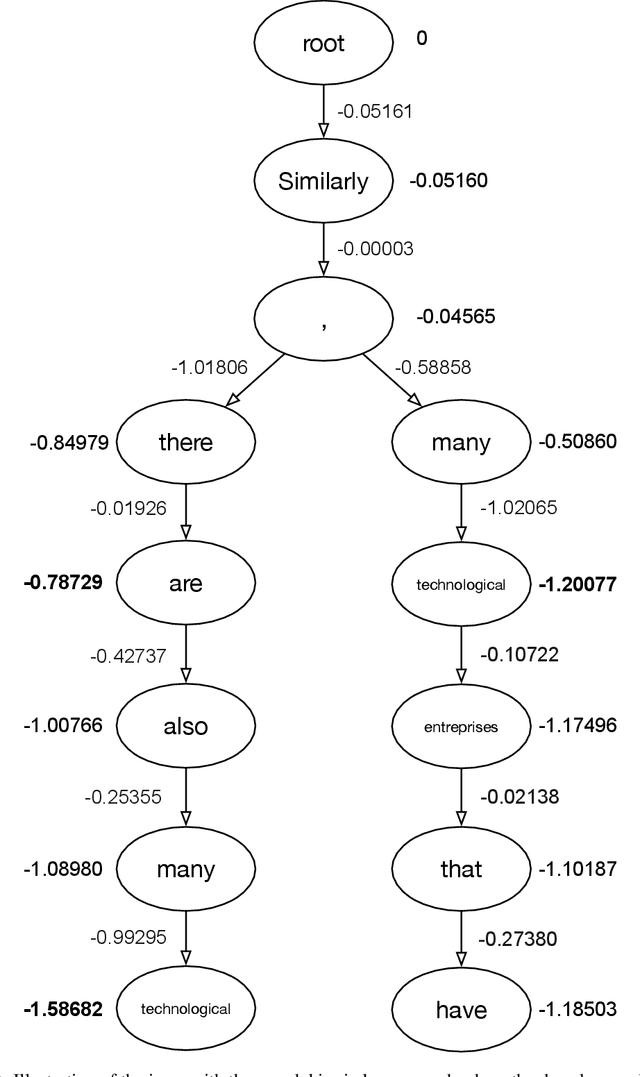
We introduce an adaptive tree search algorithm, that can find high-scoring outputs under translation models that make no assumptions about the form or structure of the search objective. This algorithm -- a deterministic variant of Monte Carlo tree search -- enables the exploration of new kinds of models that are unencumbered by constraints imposed to make decoding tractable, such as autoregressivity or conditional independence assumptions. When applied to autoregressive models, our algorithm has different biases than beam search has, which enables a new analysis of the role of decoding bias in autoregressive models. Empirically, we show that our adaptive tree search algorithm finds outputs with substantially better model scores compared to beam search in autoregressive models, and compared to reranking techniques in models whose scores do not decompose additively with respect to the words in the output. We also characterise the correlation of several translation model objectives with respect to BLEU. We find that while some standard models are poorly calibrated and benefit from the beam search bias, other often more robust models (autoregressive models tuned to maximize expected automatic metric scores, the noisy channel model and a newly proposed objective) benefit from increasing amounts of search using our proposed decoder, whereas the beam search bias limits the improvements obtained from such objectives. Thus, we argue that as models improve, the improvements may be masked by over-reliance on beam search or reranking based methods.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Diverse Pretrained Context Encodings Improve Document Translation
Jun 07, 2021



We propose a new architecture for adapting a sentence-level sequence-to-sequence transformer by incorporating multiple pretrained document context signals and assess the impact on translation performance of (1) different pretraining approaches for generating these signals, (2) the quantity of parallel data for which document context is available, and (3) conditioning on source, target, or source and target contexts. Experiments on the NIST Chinese-English, and IWSLT and WMT English-German tasks support four general conclusions: that using pretrained context representations markedly improves sample efficiency, that adequate parallel data resources are crucial for learning to use document context, that jointly conditioning on multiple context representations outperforms any single representation, and that source context is more valuable for translation performance than target side context. Our best multi-context model consistently outperforms the best existing context-aware transformers.