 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review of Poisoning Attacks Against Large Language Models
Jun 06, 2025With the widespread availability of pretrained Large Language Models (LLMs) and their training datasets, concerns about the security risks associated with their usage has increased significantly. One of these security risks is the threat of LLM poisoning attacks where an attacker modifies some part of the LLM training process to cause the LLM to behave in a malicious way. As an emerging area of research, the current frameworks and terminology for LLM poisoning attacks are derived from earlier classification poisoning literature and are not fully equipped for generative LLM settings. We conduct a systematic review of published LLM poisoning attacks to clarify the security implications and address inconsistencies in terminology across the literature. We propose a comprehensive poisoning threat model applicable to categorize a wide range of LLM poisoning attacks. The poisoning threat model includes four poisoning attack specifications that define the logistics and manipulation strategies of an attack as well as six poisoning metrics used to measure key characteristics of an attack. Under our proposed framework, we organize our discussion of published LLM poisoning literature along four critical dimensions of LLM poisoning attacks: concept poisons, stealthy poisons, persistent poisons, and poisons for unique tasks, to better understand the current landscape of security risks.
To Burst or Not to Burst: Generating and Quantifying Improbable Text
Jan 27, 2024



While large language models (LLMs) are extremely capable at text generation, their outputs are still distinguishable from human-authored text. We explore this separation across many metrics over text, many sampling techniques, many types of text data, and across two popular LLMs, LLaMA and Vicuna. Along the way, we introduce a new metric, recoverability, to highlight differences between human and machine text; and we propose a new sampling technique, burst sampling, designed to close this gap. We find that LLaMA and Vicuna have distinct distributions under many of the metrics, and that this influences our results: Recoverability separates real from fake text better than any other metric when using LLaMA. When using Vicuna, burst sampling produces text which is distributionally closer to real text compared to other sampling techniques.
Clipped-Objective Policy Gradients for Pessimistic Policy Optimization
Nov 10, 2023



To facilitate efficient learning, policy gradient approaches to deep reinforcement learning (RL) are typically paired with variance reduction measures and strategies for making large but safe policy changes based on a batch of experiences. Natural policy gradient methods, including Trust Region Policy Optimization (TRPO), seek to produce monotonic improvement through bounded changes in policy outputs. Proximal Policy Optimization (PPO) is a commonly used, first-order algorithm that instead uses loss clipping to take multiple safe optimization steps per batch of data, replacing the bound on the single step of TRPO with regularization on multiple steps. In this work, we find that the performance of PPO, when applied to continuous action spaces, may be consistently improved through a simple change in objective. Instead of the importance sampling objective of PPO, we instead recommend a basic policy gradient, clipped in an equivalent fashion. While both objectives produce biased gradient estimates with respect to the RL objective, they also both display significantly reduced variance compared to the unbiased off-policy policy gradient. Additionally, we show that (1) the clipped-objective policy gradient (COPG) objective is on average "pessimistic" compared to both the PPO objective and (2) this pessimism promotes enhanced exploration. As a result, we empirically observe that COPG produces improved learning compared to PPO in single-task, constrained, and multi-task learning, without adding significant computational cost or complexity. Compared to TRPO, the COPG approach is seen to offer comparable or superior performance, while retaining the simplicity of a first-order method.
Triangular Dropout: Variable Network Width without Retraining
May 02, 2022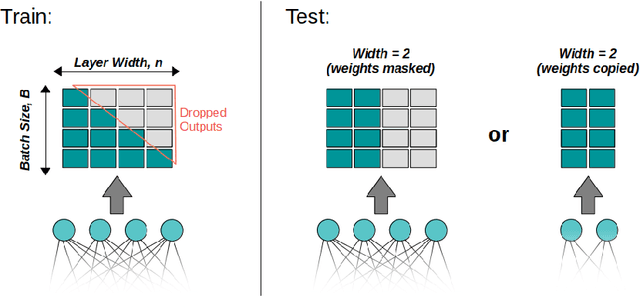
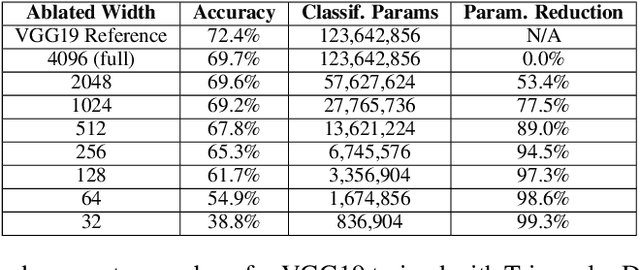
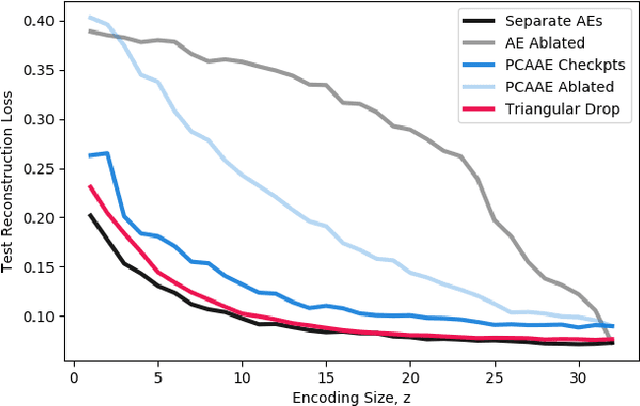

One of the most fundamental design choices in neural networks is layer width: it affects the capacity of what a network can learn and determines the complexity of the solution. This latter property is often exploited when introducing information bottlenecks, forcing a network to learn compressed representations. However, such an architecture decision is typically immutable once training begins; switching to a more compressed architecture requires retraining. In this paper we present a new layer design, called Triangular Dropout, which does not have this limitation. After training, the layer can be arbitrarily reduced in width to exchange performance for narrowness. We demonstrate the construction and potential use cases of such a mechanism in three areas. Firstly, we describe the formulation of Triangular Dropout in autoencoders, creating models with selectable compression after training. Secondly, we add Triangular Dropout to VGG19 on ImageNet, creating a powerful network which, without retraining, can be significantly reduced in parameters. Lastly, we explore the application of Triangular Dropout to reinforcement learning (RL) policies on selected control problems.
Meta Arcade: A Configurable Environment Suite for Meta-Learning
Dec 01, 2021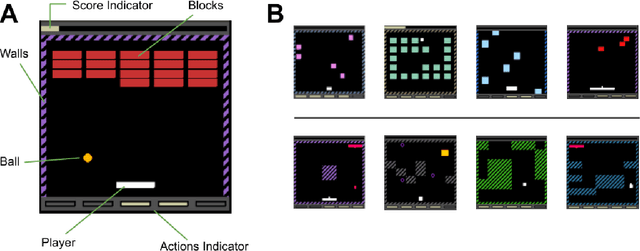
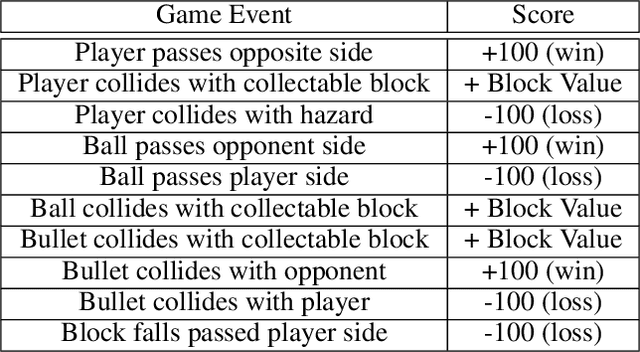
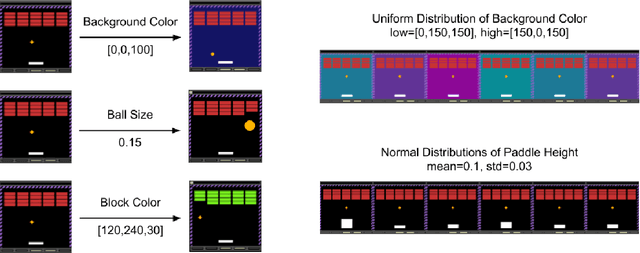
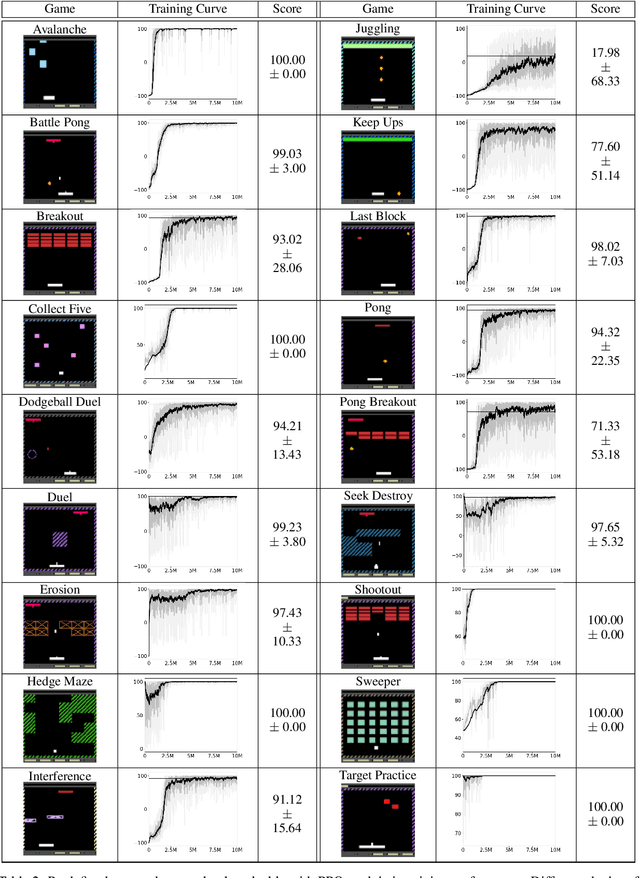
Most approaches to deep reinforcement learning (DRL) attempt to solve a single task at a time. As a result, most existing research benchmarks consist of individual games or suites of games that have common interfaces but little overlap in their perceptual features, objectives, or reward structures. To facilitate research into knowledge transfer among trained agents (e.g. via multi-task and meta-learning), more environment suites that provide configurable tasks with enough commonality to be studied collectively are needed. In this paper we present Meta Arcade, a tool to easily define and configure custom 2D arcade games that share common visuals, state spaces, action spaces, game components, and scoring mechanisms. Meta Arcade differs from prior environments in that both task commonality and configurability are prioritized: entire sets of games can be constructed from common elements, and these elements are adjustable through exposed parameters. We include a suite of 24 predefined games that collectively illustrate the possibilities of this framework and discuss how these games can be configured for research applications. We provide several experiments that illustrate how Meta Arcade could be used, including single-task benchmarks of predefined games, sample curriculum-based approaches that change game parameters over a set schedule, and an exploration of transfer learning between games.
The AI Arena: A Framework for Distributed Multi-Agent Reinforcement Learning
Mar 09, 2021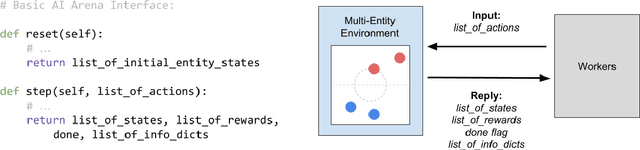

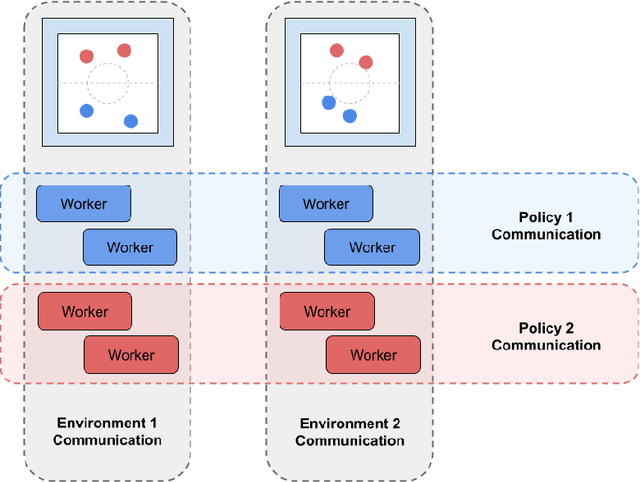
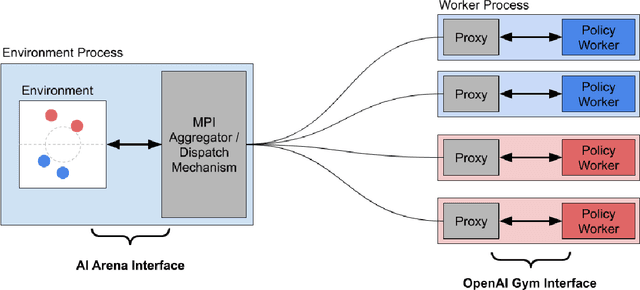
Advances in reinforcement learning (RL) have resulted in recent breakthroughs in the application of artificial intelligence (AI) across many different domains. An emerging landscape of development environments is making powerful RL techniques more accessible for a growing community of researchers. However, most existing frameworks do not directly address the problem of learning in complex operating environments, such as dense urban settings or defense-related scenarios, that incorporate distributed, heterogeneous teams of agents. To help enable AI research for this important class of applications, we introduce the AI Arena: a scalable framework with flexible abstractions for distributed multi-agent reinforcement learning. The AI Arena extends the OpenAI Gym interface to allow greater flexibility in learning control policies across multiple agents with heterogeneous learning strategies and localized views of the environment. To illustrate the utility of our framework, we present experimental results that demonstrate performance gains due to a distributed multi-agent learning approach over commonly-used RL techniques in several different learning environments.
PICO: Primitive Imitation for COntrol
Jun 22, 2020
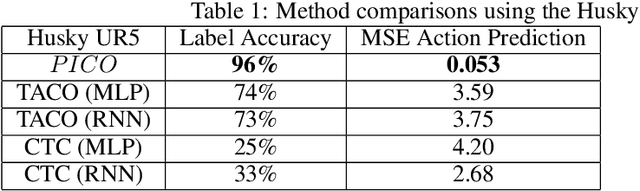
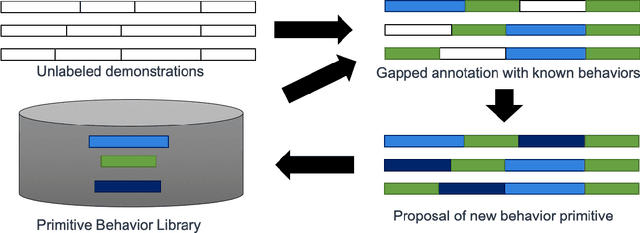
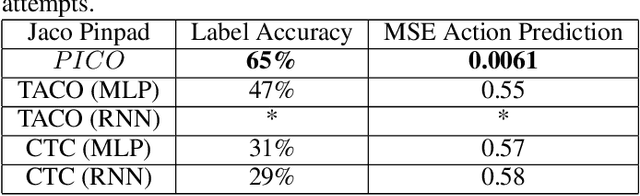
In this work, we explore a novel framework for control of complex systems called Primitive Imitation for Control PICO. The approach combines ideas from imitation learning, task decomposition, and novel task sequencing to generalize from demonstrations to new behaviors. Demonstrations are automatically decomposed into existing or missing sub-behaviors which allows the framework to identify novel behaviors while not duplicating existing behaviors. Generalization to new tasks is achieved through dynamic blending of behavior primitives. We evaluated the approach using demonstrations from two different robotic platforms. The experimental results show that PICO is able to detect the presence of a novel behavior primitive and build the missing control policy.
TanksWorld: A Multi-Agent Environment for AI Safety Research
Feb 25, 2020

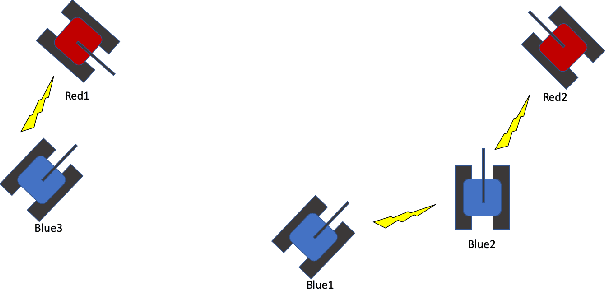
The ability to create artificial intelligence (AI) capable of performing complex tasks is rapidly outpacing our ability to ensure the safe and assured operation of AI-enabled systems. Fortunately, a landscape of AI safety research is emerging in response to this asymmetry and yet there is a long way to go. In particular, recent simulation environments created to illustrate AI safety risks are relatively simple or narrowly-focused on a particular issue. Hence, we see a critical need for AI safety research environments that abstract essential aspects of complex real-world applications. In this work, we introduce the AI safety TanksWorld as an environment for AI safety research with three essential aspects: competing performance objectives, human-machine teaming, and multi-agent competition. The AI safety TanksWorld aims to accelerate the advancement of safe multi-agent decision-making algorithms by providing a software framework to support competitions with both system performance and safety objectives. As a work in progress, this paper introduces our research objectives and learning environment with reference code and baseline performance metrics to follow in a future work.