 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Properties of Lifelong Learning Systems
Jul 28, 2022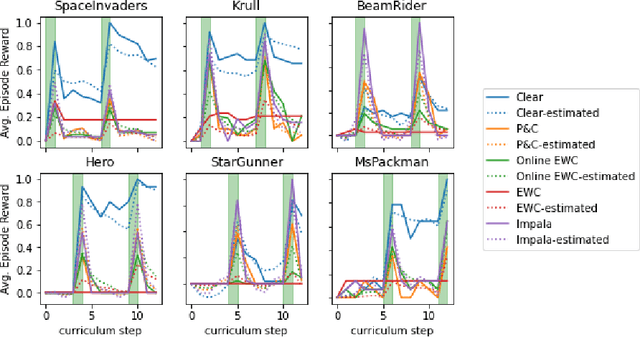
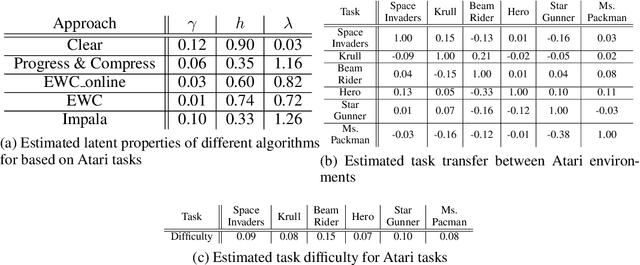
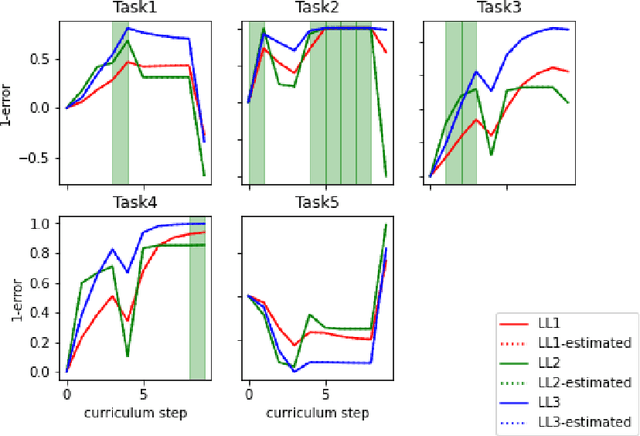
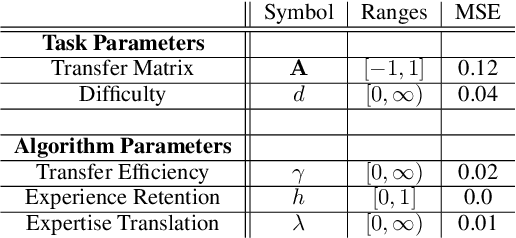
Creating artificial intelligence (AI) systems capable of demonstrating lifelong learning is a fundamental challenge, and many approaches and metrics have been proposed to analyze algorithmic properties. However, for existing lifelong learning metrics, algorithmic contributions are confounded by task and scenario structure. To mitigate this issue, we introduce an algorithm-agnostic explainable surrogate-modeling approach to estimate latent properties of lifelong learning algorithms. We validate the approach for estimating these properties via experiments on synthetic data. To validate the structure of the surrogate model, we analyze real performance data from a collection of popular lifelong learning approaches and baselines adapted for lifelong classification and lifelong reinforcement learning.
Lifelong Learning Metrics
Jan 20, 2022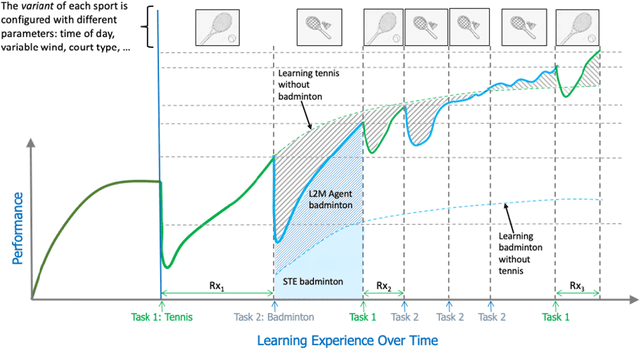
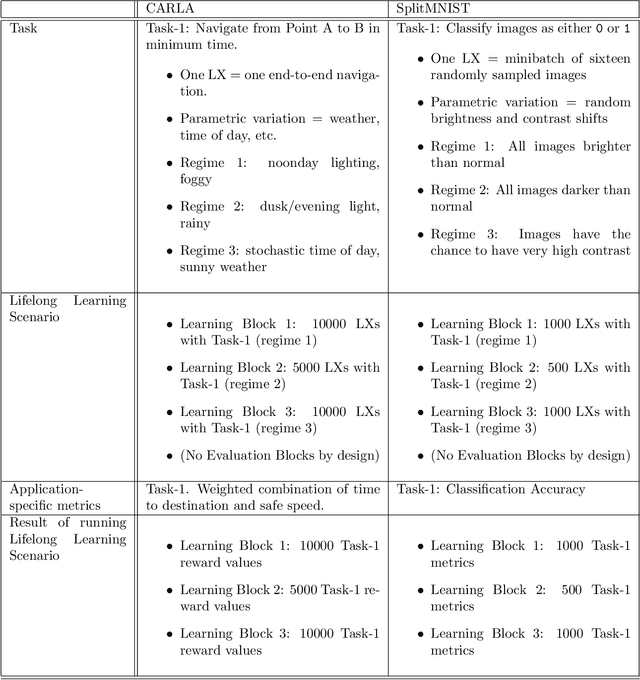
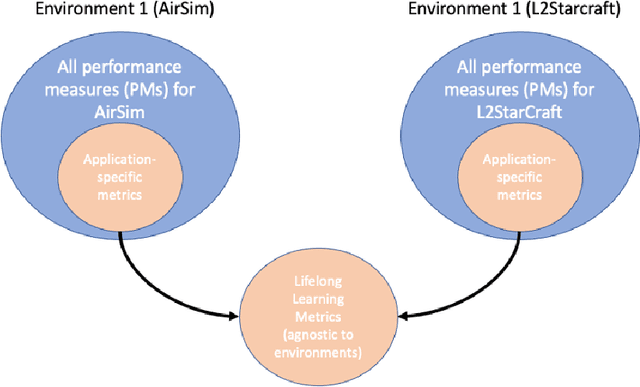
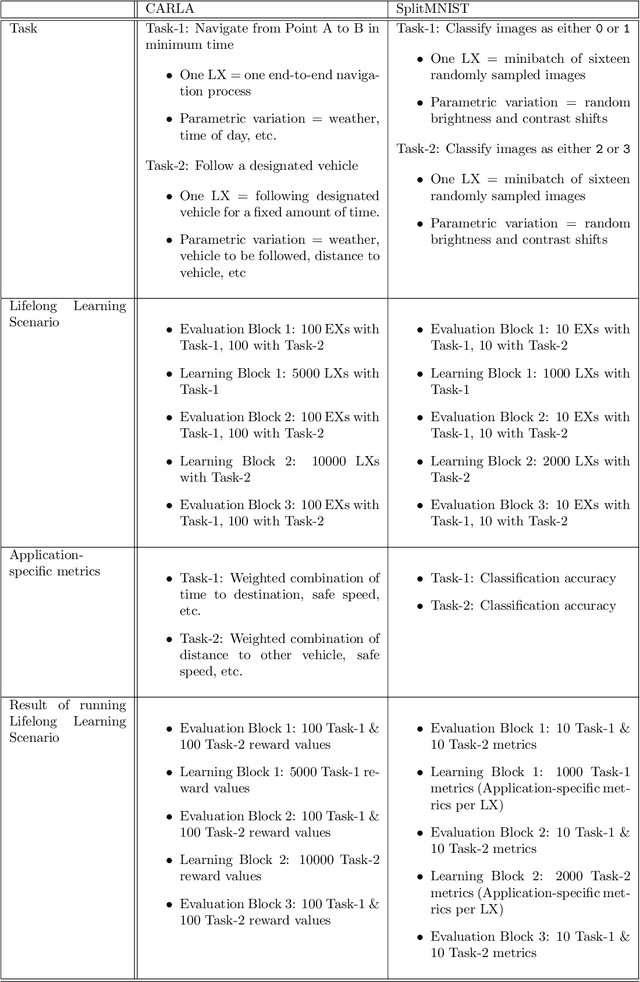
The DARPA Lifelong Learning Machines (L2M) program seeks to yield advances in artificial intelligence (AI) systems so that they are capable of learning (and improving) continuously, leveraging data on one task to improve performance on another, and doing so in a computationally sustainable way. Performers on this program developed systems capable of performing a diverse range of functions, including autonomous driving, real-time strategy, and drone simulation. These systems featured a diverse range of characteristics (e.g., task structure, lifetime duration), and an immediate challenge faced by the program's testing and evaluation team was measuring system performance across these different settings. This document, developed in close collaboration with DARPA and the program performers, outlines a formalism for constructing and characterizing the performance of agents performing lifelong learning scenarios.
Meta Arcade: A Configurable Environment Suite for Meta-Learning
Dec 01, 2021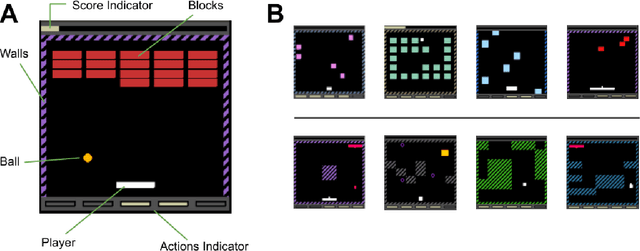
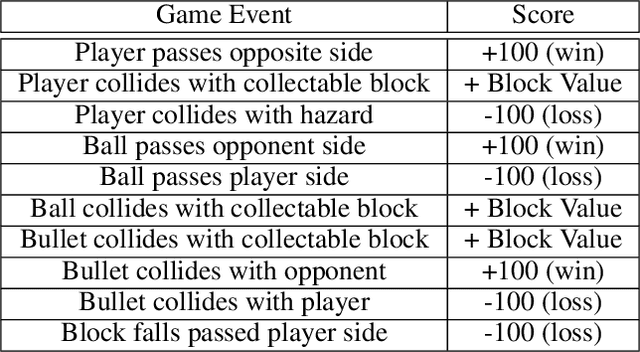
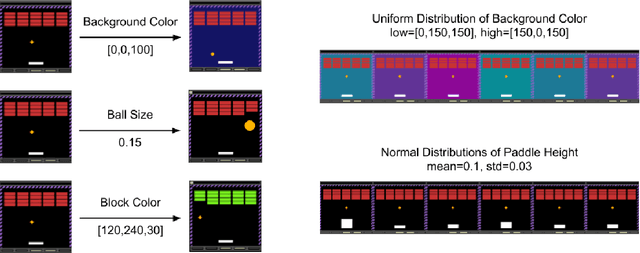
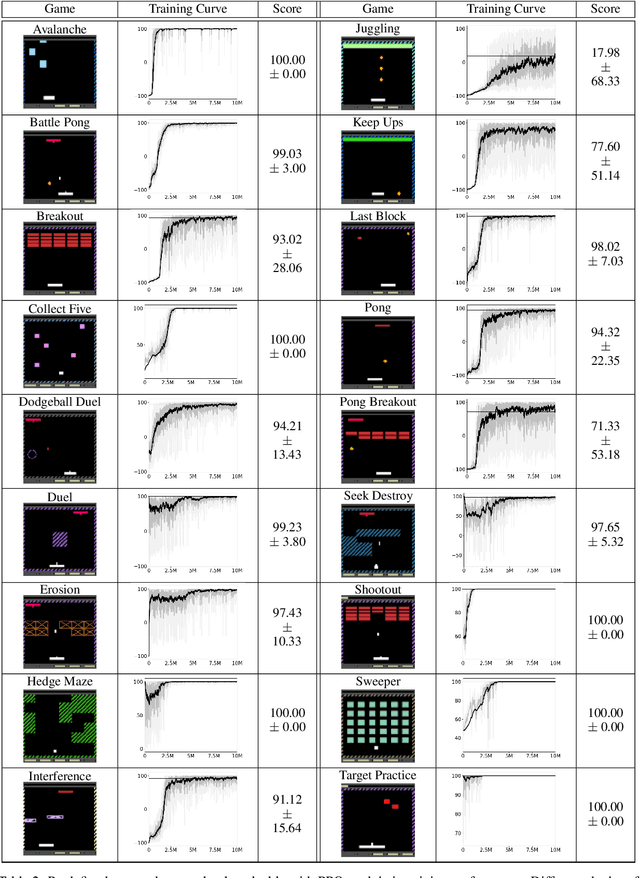
Most approaches to deep reinforcement learning (DRL) attempt to solve a single task at a time. As a result, most existing research benchmarks consist of individual games or suites of games that have common interfaces but little overlap in their perceptual features, objectives, or reward structures. To facilitate research into knowledge transfer among trained agents (e.g. via multi-task and meta-learning), more environment suites that provide configurable tasks with enough commonality to be studied collectively are needed. In this paper we present Meta Arcade, a tool to easily define and configure custom 2D arcade games that share common visuals, state spaces, action spaces, game components, and scoring mechanisms. Meta Arcade differs from prior environments in that both task commonality and configurability are prioritized: entire sets of games can be constructed from common elements, and these elements are adjustable through exposed parameters. We include a suite of 24 predefined games that collectively illustrate the possibilities of this framework and discuss how these games can be configured for research applications. We provide several experiments that illustrate how Meta Arcade could be used, including single-task benchmarks of predefined games, sample curriculum-based approaches that change game parameters over a set schedule, and an exploration of transfer learning between games.