 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe AI Arena: A Framework for Distributed Multi-Agent Reinforcement Learning
Mar 09, 2021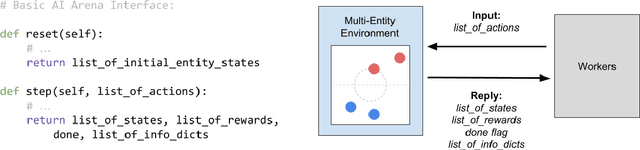

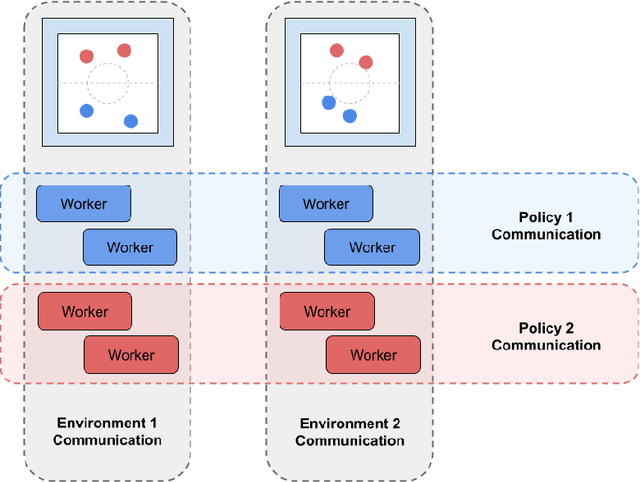
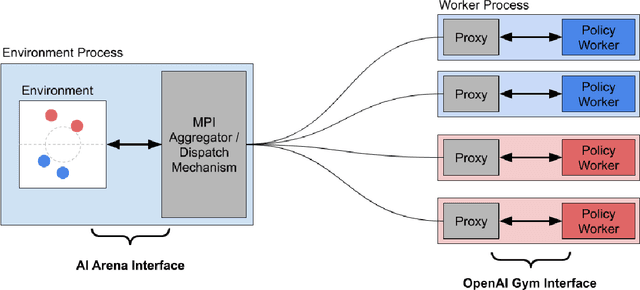
Advances in reinforcement learning (RL) have resulted in recent breakthroughs in the application of artificial intelligence (AI) across many different domains. An emerging landscape of development environments is making powerful RL techniques more accessible for a growing community of researchers. However, most existing frameworks do not directly address the problem of learning in complex operating environments, such as dense urban settings or defense-related scenarios, that incorporate distributed, heterogeneous teams of agents. To help enable AI research for this important class of applications, we introduce the AI Arena: a scalable framework with flexible abstractions for distributed multi-agent reinforcement learning. The AI Arena extends the OpenAI Gym interface to allow greater flexibility in learning control policies across multiple agents with heterogeneous learning strategies and localized views of the environment. To illustrate the utility of our framework, we present experimental results that demonstrate performance gains due to a distributed multi-agent learning approach over commonly-used RL techniques in several different learning environments.
TanksWorld: A Multi-Agent Environment for AI Safety Research
Feb 25, 2020

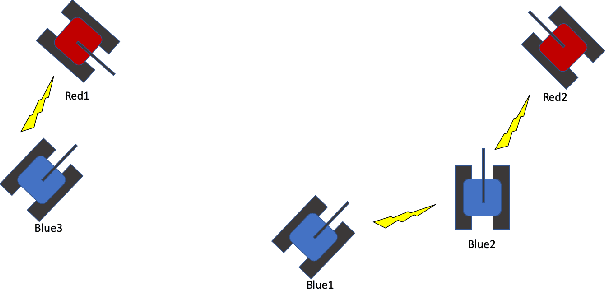
The ability to create artificial intelligence (AI) capable of performing complex tasks is rapidly outpacing our ability to ensure the safe and assured operation of AI-enabled systems. Fortunately, a landscape of AI safety research is emerging in response to this asymmetry and yet there is a long way to go. In particular, recent simulation environments created to illustrate AI safety risks are relatively simple or narrowly-focused on a particular issue. Hence, we see a critical need for AI safety research environments that abstract essential aspects of complex real-world applications. In this work, we introduce the AI safety TanksWorld as an environment for AI safety research with three essential aspects: competing performance objectives, human-machine teaming, and multi-agent competition. The AI safety TanksWorld aims to accelerate the advancement of safe multi-agent decision-making algorithms by providing a software framework to support competitions with both system performance and safety objectives. As a work in progress, this paper introduces our research objectives and learning environment with reference code and baseline performance metrics to follow in a future work.
On the Complexity of Reconnaissance Blind Chess
Nov 07, 2018
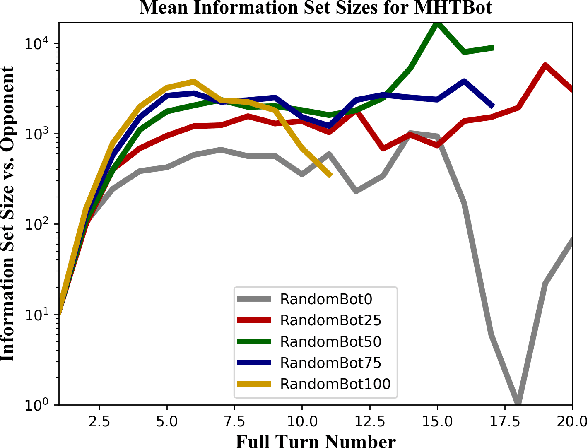

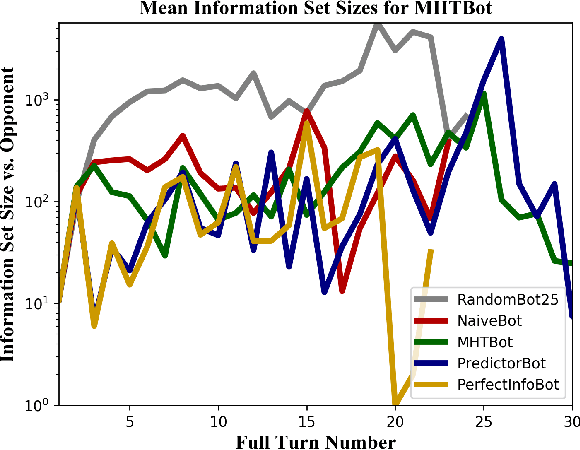
This paper provides a complexity analysis for the game of reconnaissance blind chess (RBC), a recently-introduced variant of chess where each player does not know the positions of the opponent's pieces a priori but may reveal a subset of them through chosen, private sensing actions. In contrast to commonly studied imperfect information games like poker and Kriegspiel, an RBC player does not know what the opponent knows or has chosen to learn, exponentially expanding the size of the game's information sets (i.e., the number of possible game states that are consistent with what a player has observed). Effective RBC sensing and moving strategies must account for the uncertainty of both players, an essential element of many real-world decision-making problems. Here we evaluate RBC from a game theoretic perspective, tracking the proliferation of information sets from the perspective of selected canonical bot players in tournament play. We show that, even for effective sensing strategies, the game sizes of RBC compare to those of Go while the average size of a player's information set throughout an RBC game is much greater than that of a player in Heads-up Limit Hold 'Em. We compare these measures of complexity among different playing algorithms and provide cursory assessments of the various sensing and moving strategies.