 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Goal-Directed Meta-Learning with Contextual Planning Networks
Nov 18, 2021


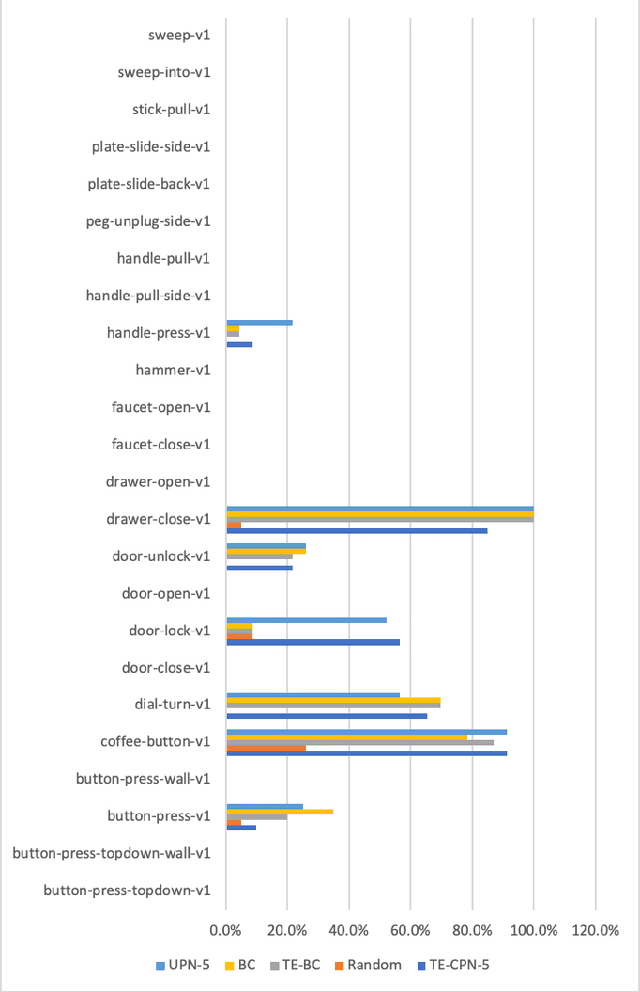
The goal of meta-learning is to generalize to new tasks and goals as quickly as possible. Ideally, we would like approaches that generalize to new goals and tasks on the first attempt. Toward that end, we introduce contextual planning networks (CPN). Tasks are represented as goal images and used to condition the approach. We evaluate CPN along with several other approaches adapted for zero-shot goal-directed meta-learning. We evaluate these approaches across 24 distinct manipulation tasks using Metaworld benchmark tasks. We found that CPN outperformed several approaches and baselines on one task and was competitive with existing approaches on others. We demonstrate the approach on a physical platform on Jenga tasks using a Kinova Jaco robotic arm.
The AI Arena: A Framework for Distributed Multi-Agent Reinforcement Learning
Mar 09, 2021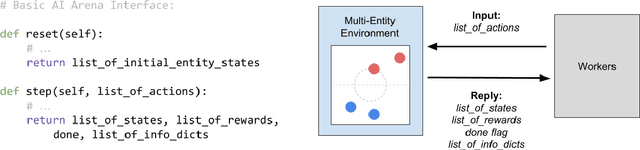

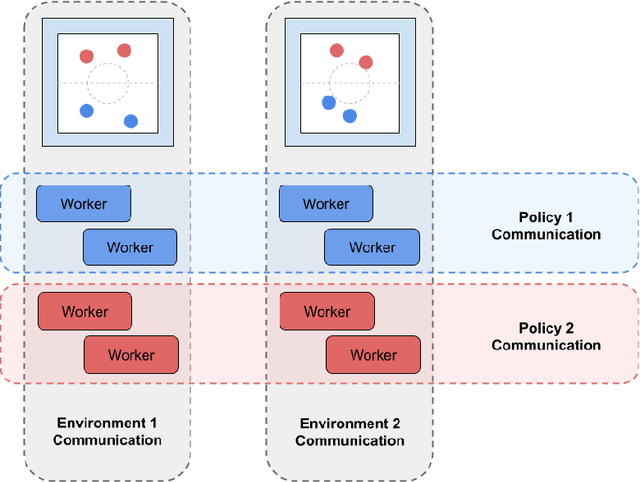
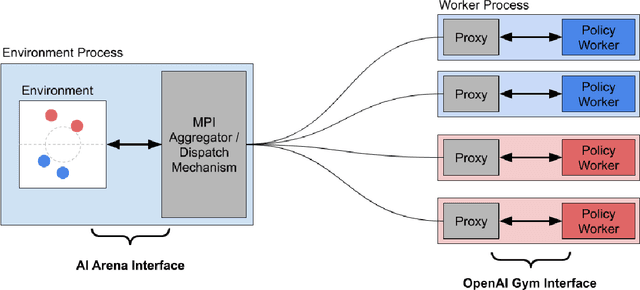
Advances in reinforcement learning (RL) have resulted in recent breakthroughs in the application of artificial intelligence (AI) across many different domains. An emerging landscape of development environments is making powerful RL techniques more accessible for a growing community of researchers. However, most existing frameworks do not directly address the problem of learning in complex operating environments, such as dense urban settings or defense-related scenarios, that incorporate distributed, heterogeneous teams of agents. To help enable AI research for this important class of applications, we introduce the AI Arena: a scalable framework with flexible abstractions for distributed multi-agent reinforcement learning. The AI Arena extends the OpenAI Gym interface to allow greater flexibility in learning control policies across multiple agents with heterogeneous learning strategies and localized views of the environment. To illustrate the utility of our framework, we present experimental results that demonstrate performance gains due to a distributed multi-agent learning approach over commonly-used RL techniques in several different learning environments.
PICO: Primitive Imitation for COntrol
Jun 22, 2020
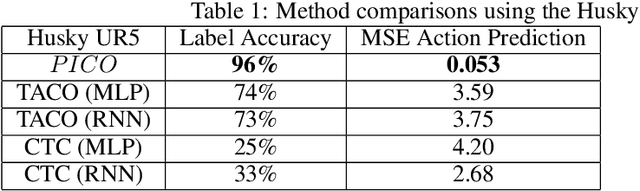
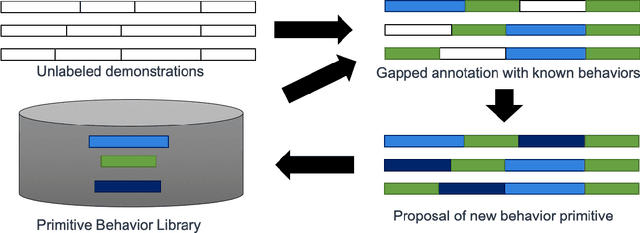
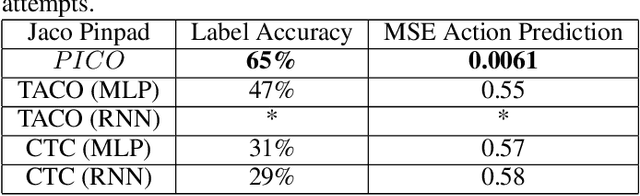
In this work, we explore a novel framework for control of complex systems called Primitive Imitation for Control PICO. The approach combines ideas from imitation learning, task decomposition, and novel task sequencing to generalize from demonstrations to new behaviors. Demonstrations are automatically decomposed into existing or missing sub-behaviors which allows the framework to identify novel behaviors while not duplicating existing behaviors. Generalization to new tasks is achieved through dynamic blending of behavior primitives. We evaluated the approach using demonstrations from two different robotic platforms. The experimental results show that PICO is able to detect the presence of a novel behavior primitive and build the missing control policy.
TanksWorld: A Multi-Agent Environment for AI Safety Research
Feb 25, 2020

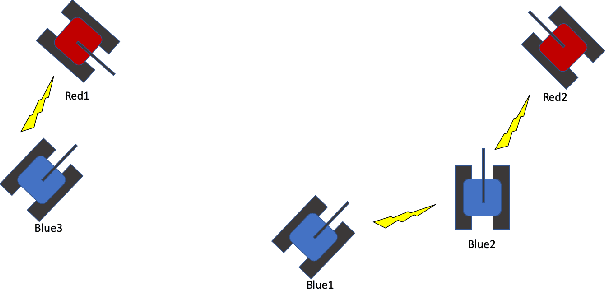
The ability to create artificial intelligence (AI) capable of performing complex tasks is rapidly outpacing our ability to ensure the safe and assured operation of AI-enabled systems. Fortunately, a landscape of AI safety research is emerging in response to this asymmetry and yet there is a long way to go. In particular, recent simulation environments created to illustrate AI safety risks are relatively simple or narrowly-focused on a particular issue. Hence, we see a critical need for AI safety research environments that abstract essential aspects of complex real-world applications. In this work, we introduce the AI safety TanksWorld as an environment for AI safety research with three essential aspects: competing performance objectives, human-machine teaming, and multi-agent competition. The AI safety TanksWorld aims to accelerate the advancement of safe multi-agent decision-making algorithms by providing a software framework to support competitions with both system performance and safety objectives. As a work in progress, this paper introduces our research objectives and learning environment with reference code and baseline performance metrics to follow in a future work.