 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review of Poisoning Attacks Against Large Language Models
Jun 06, 2025With the widespread availability of pretrained Large Language Models (LLMs) and their training datasets, concerns about the security risks associated with their usage has increased significantly. One of these security risks is the threat of LLM poisoning attacks where an attacker modifies some part of the LLM training process to cause the LLM to behave in a malicious way. As an emerging area of research, the current frameworks and terminology for LLM poisoning attacks are derived from earlier classification poisoning literature and are not fully equipped for generative LLM settings. We conduct a systematic review of published LLM poisoning attacks to clarify the security implications and address inconsistencies in terminology across the literature. We propose a comprehensive poisoning threat model applicable to categorize a wide range of LLM poisoning attacks. The poisoning threat model includes four poisoning attack specifications that define the logistics and manipulation strategies of an attack as well as six poisoning metrics used to measure key characteristics of an attack. Under our proposed framework, we organize our discussion of published LLM poisoning literature along four critical dimensions of LLM poisoning attacks: concept poisons, stealthy poisons, persistent poisons, and poisons for unique tasks, to better understand the current landscape of security risks.
Backdoors in DRL: Four Environments Focusing on In-distribution Triggers
May 22, 2025



Backdoor attacks, or trojans, pose a security risk by concealing undesirable behavior in deep neural network models. Open-source neural networks are downloaded from the internet daily, possibly containing backdoors, and third-party model developers are common. To advance research on backdoor attack mitigation, we develop several trojans for deep reinforcement learning (DRL) agents. We focus on in-distribution triggers, which occur within the agent's natural data distribution, since they pose a more significant security threat than out-of-distribution triggers due to their ease of activation by the attacker during model deployment. We implement backdoor attacks in four reinforcement learning (RL) environments: LavaWorld, Randomized LavaWorld, Colorful Memory, and Modified Safety Gymnasium. We train various models, both clean and backdoored, to characterize these attacks. We find that in-distribution triggers can require additional effort to implement and be more challenging for models to learn, but are nevertheless viable threats in DRL even using basic data poisoning attacks.
Investigating the Treacherous Turn in Deep Reinforcement Learning
Apr 11, 2025


The Treacherous Turn refers to the scenario where an artificial intelligence (AI) agent subtly, and perhaps covertly, learns to perform a behavior that benefits itself but is deemed undesirable and potentially harmful to a human supervisor. During training, the agent learns to behave as expected by the human supervisor, but when deployed to perform its task, it performs an alternate behavior without the supervisor there to prevent it. Initial experiments applying DRL to an implementation of the A Link to the Past example do not produce the treacherous turn effect naturally, despite various modifications to the environment intended to produce it. However, in this work, we find the treacherous behavior to be reproducible in a DRL agent when using other trojan injection strategies. This approach deviates from the prototypical treacherous turn behavior since the behavior is explicitly trained into the agent, rather than occurring as an emergent consequence of environmental complexity or poor objective specification. Nonetheless, these experiments provide new insights into the challenges of producing agents capable of true treacherous turn behavior.
Detecting Dataset Bias in Medical AI: A Generalized and Modality-Agnostic Auditing Framework
Mar 13, 2025Data-driven AI is establishing itself at the center of evidence-based medicine. However, reports of shortcomings and unexpected behavior are growing due to AI's reliance on association-based learning. A major reason for this behavior: latent bias in machine learning datasets can be amplified during training and/or hidden during testing. We present a data modality-agnostic auditing framework for generating targeted hypotheses about sources of bias which we refer to as Generalized Attribute Utility and Detectability-Induced bias Testing (G-AUDIT) for datasets. Our method examines the relationship between task-level annotations and data properties including protected attributes (e.g., race, age, sex) and environment and acquisition characteristics (e.g., clinical site, imaging protocols). G-AUDIT automatically quantifies the extent to which the observed data attributes may enable shortcut learning, or in the case of testing data, hide predictions made based on spurious associations. We demonstrate the broad applicability and value of our method by analyzing large-scale medical datasets for three distinct modalities and learning tasks: skin lesion classification in images, stigmatizing language classification in Electronic Health Records (EHR), and mortality prediction for ICU tabular data. In each setting, G-AUDIT successfully identifies subtle biases commonly overlooked by traditional qualitative methods that focus primarily on social and ethical objectives, underscoring its practical value in exposing dataset-level risks and supporting the downstream development of reliable AI systems. Our method paves the way for achieving deeper understanding of machine learning datasets throughout the AI development life-cycle from initial prototyping all the way to regulation, and creates opportunities to reduce model bias, enabling safer and more trustworthy AI systems.
A Causal Framework for Aligning Image Quality Metrics and Deep Neural Network Robustness
Mar 04, 2025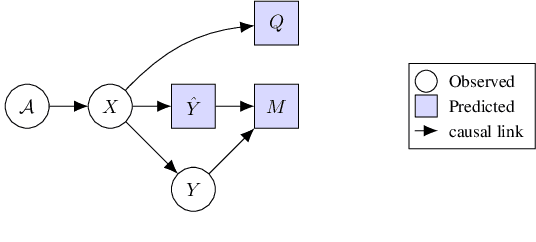
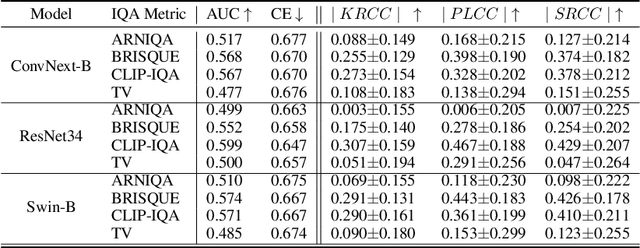
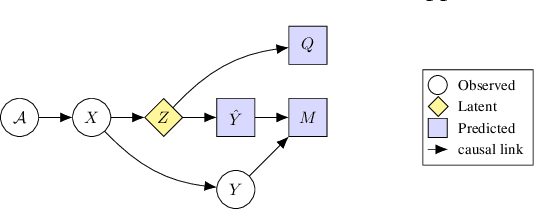
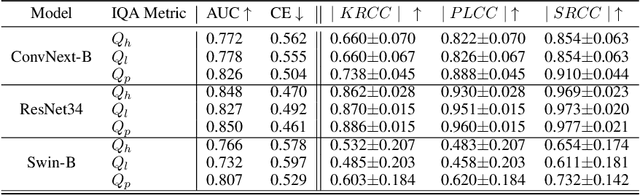
Image quality plays an important role in the performance of deep neural networks (DNNs) and DNNs have been widely shown to exhibit sensitivity to changes in imaging conditions. Large-scale datasets often contain images under a wide range of conditions prompting a need to quantify and understand their underlying quality distribution in order to better characterize DNN performance and robustness. Aligning the sensitivities of image quality metrics and DNNs ensures that estimates of quality can act as proxies for image/dataset difficulty independent of the task models trained/evaluated on the data. Conventional image quality assessment (IQA) seeks to measure and align quality relative to human perceptual judgments, but here we seek a quality measure that is not only sensitive to imaging conditions but also well-aligned with DNN sensitivities. We first ask whether conventional IQA metrics are also informative of DNN performance. In order to answer this question, we reframe IQA from a causal perspective and examine conditions under which quality metrics are predictive of DNN performance. We show theoretically and empirically that current IQA metrics are weak predictors of DNN performance in the context of classification. We then use our causal framework to provide an alternative formulation and a new image quality metric that is more strongly correlated with DNN performance and can act as a prior on performance without training new task models. Our approach provides a means to directly estimate the quality distribution of large-scale image datasets towards characterizing the relationship between dataset composition and DNN performance.
Causality-Driven Audits of Model Robustness
Oct 30, 2024
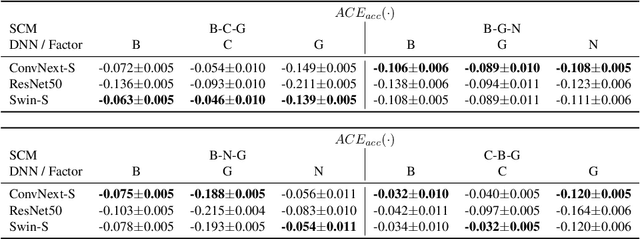
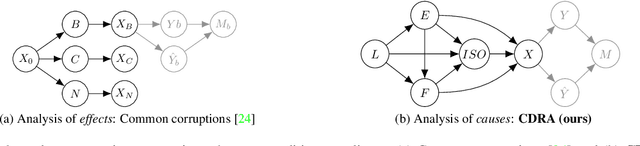
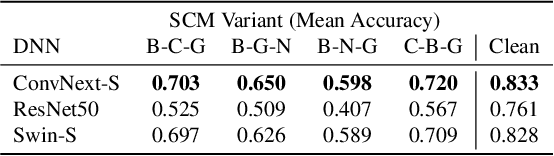
Robustness audits of deep neural networks (DNN) provide a means to uncover model sensitivities to the challenging real-world imaging conditions that significantly degrade DNN performance in-the-wild. Such conditions are often the result of the compounding of multiple factors inherent to the environment, sensor, or processing pipeline and may lead to complex image distortions that are not easily categorized. When robustness audits are limited to a set of pre-determined imaging effects or distortions, the results cannot be (easily) transferred to real-world conditions where image corruptions may be more complex or nuanced. To address this challenge, we present a new alternative robustness auditing method that uses causal inference to measure DNN sensitivities to the factors of the imaging process that cause complex distortions. Our approach uses causal models to explicitly encode assumptions about the domain-relevant factors and their interactions. Then, through extensive experiments on natural and rendered images across multiple vision tasks, we show that our approach reliably estimates causal effects of each factor on DNN performance using observational domain data. These causal effects directly tie DNN sensitivities to observable properties of the imaging pipeline in the domain of interest towards reducing the risk of unexpected DNN failures when deployed in that domain.
From Generalization to Precision: Exploring SAM for Tool Segmentation in Surgical Environments
Feb 28, 2024Purpose: Accurate tool segmentation is essential in computer-aided procedures. However, this task conveys challenges due to artifacts' presence and the limited training data in medical scenarios. Methods that generalize to unseen data represent an interesting venue, where zero-shot segmentation presents an option to account for data limitation. Initial exploratory works with the Segment Anything Model (SAM) show that bounding-box-based prompting presents notable zero-short generalization. However, point-based prompting leads to a degraded performance that further deteriorates under image corruption. We argue that SAM drastically over-segment images with high corruption levels, resulting in degraded performance when only a single segmentation mask is considered, while the combination of the masks overlapping the object of interest generates an accurate prediction. Method: We use SAM to generate the over-segmented prediction of endoscopic frames. Then, we employ the ground-truth tool mask to analyze the results of SAM when the best single mask is selected as prediction and when all the individual masks overlapping the object of interest are combined to obtain the final predicted mask. We analyze the Endovis18 and Endovis17 instrument segmentation datasets using synthetic corruptions of various strengths and an In-House dataset featuring counterfactually created real-world corruptions. Results: Combining the over-segmented masks contributes to improvements in the IoU. Furthermore, selecting the best single segmentation presents a competitive IoU score for clean images. Conclusions: Combined SAM predictions present improved results and robustness up to a certain corruption level. However, appropriate prompting strategies are fundamental for implementing these models in the medical domain.
RobustCLEVR: A Benchmark and Framework for Evaluating Robustness in Object-centric Learning
Aug 28, 2023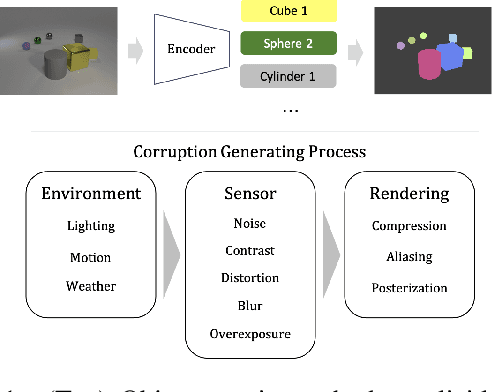


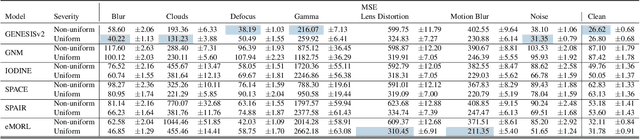
Object-centric representation learning offers the potential to overcome limitations of image-level representations by explicitly parsing image scenes into their constituent components. While image-level representations typically lack robustness to natural image corruptions, the robustness of object-centric methods remains largely untested. To address this gap, we present the RobustCLEVR benchmark dataset and evaluation framework. Our framework takes a novel approach to evaluating robustness by enabling the specification of causal dependencies in the image generation process grounded in expert knowledge and capable of producing a wide range of image corruptions unattainable in existing robustness evaluations. Using our framework, we define several causal models of the image corruption process which explicitly encode assumptions about the causal relationships and distributions of each corruption type. We generate dataset variants for each causal model on which we evaluate state-of-the-art object-centric methods. Overall, we find that object-centric methods are not inherently robust to image corruptions. Our causal evaluation approach exposes model sensitivities not observed using conventional evaluation processes, yielding greater insight into robustness differences across algorithms. Lastly, while conventional robustness evaluations view corruptions as out-of-distribution, we use our causal framework to show that even training on in-distribution image corruptions does not guarantee increased model robustness. This work provides a step towards more concrete and substantiated understanding of model performance and deterioration under complex corruption processes of the real-world.
Exploiting Large Neuroimaging Datasets to Create Connectome-Constrained Approaches for more Robust, Efficient, and Adaptable Artificial Intelligence
May 26, 2023Despite the progress in deep learning networks, efficient learning at the edge (enabling adaptable, low-complexity machine learning solutions) remains a critical need for defense and commercial applications. We envision a pipeline to utilize large neuroimaging datasets, including maps of the brain which capture neuron and synapse connectivity, to improve machine learning approaches. We have pursued different approaches within this pipeline structure. First, as a demonstration of data-driven discovery, the team has developed a technique for discovery of repeated subcircuits, or motifs. These were incorporated into a neural architecture search approach to evolve network architectures. Second, we have conducted analysis of the heading direction circuit in the fruit fly, which performs fusion of visual and angular velocity features, to explore augmenting existing computational models with new insight. Our team discovered a novel pattern of connectivity, implemented a new model, and demonstrated sensor fusion on a robotic platform. Third, the team analyzed circuitry for memory formation in the fruit fly connectome, enabling the design of a novel generative replay approach. Finally, the team has begun analysis of connectivity in mammalian cortex to explore potential improvements to transformer networks. These constraints increased network robustness on the most challenging examples in the CIFAR-10-C computer vision robustness benchmark task, while reducing learnable attention parameters by over an order of magnitude. Taken together, these results demonstrate multiple potential approaches to utilize insight from neural systems for developing robust and efficient machine learning techniques.
Data AUDIT: Identifying Attribute Utility- and Detectability-Induced Bias in Task Models
Apr 06, 2023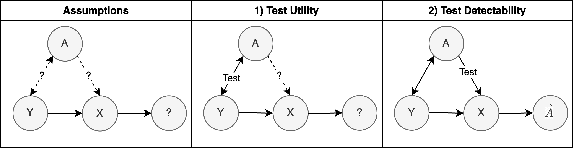
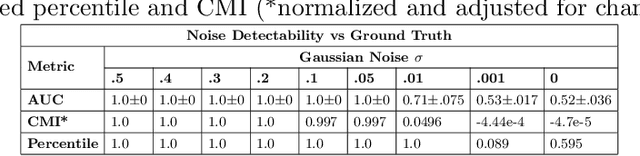
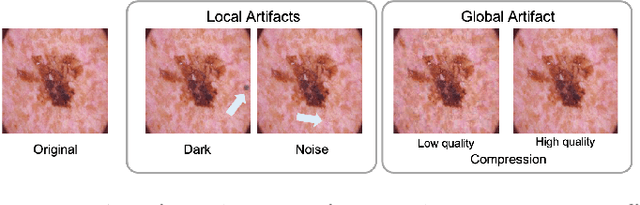
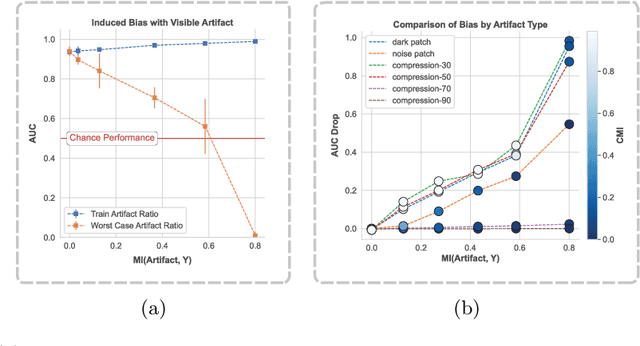
To safely deploy deep learning-based computer vision models for computer-aided detection and diagnosis, we must ensure that they are robust and reliable. Towards that goal, algorithmic auditing has received substantial attention. To guide their audit procedures, existing methods rely on heuristic approaches or high-level objectives (e.g., non-discrimination in regards to protected attributes, such as sex, gender, or race). However, algorithms may show bias with respect to various attributes beyond the more obvious ones, and integrity issues related to these more subtle attributes can have serious consequences. To enable the generation of actionable, data-driven hypotheses which identify specific dataset attributes likely to induce model bias, we contribute a first technique for the rigorous, quantitative screening of medical image datasets. Drawing from literature in the causal inference and information theory domains, our procedure decomposes the risks associated with dataset attributes in terms of their detectability and utility (defined as the amount of information knowing the attribute gives about a task label). To demonstrate the effectiveness and sensitivity of our method, we develop a variety of datasets with synthetically inserted artifacts with different degrees of association to the target label that allow evaluation of inherited model biases via comparison of performance against true counterfactual examples. Using these datasets and results from hundreds of trained models, we show our screening method reliably identifies nearly imperceptible bias-inducing artifacts. Lastly, we apply our method to the natural attributes of a popular skin-lesion dataset and demonstrate its success. Our approach provides a means to perform more systematic algorithmic audits and guide future data collection efforts in pursuit of safer and more reliable models.